大模型能否为不同硬件平台生成高性能内核?南大、浙大提出跨平台内核生成评测框架MultiKernelBench
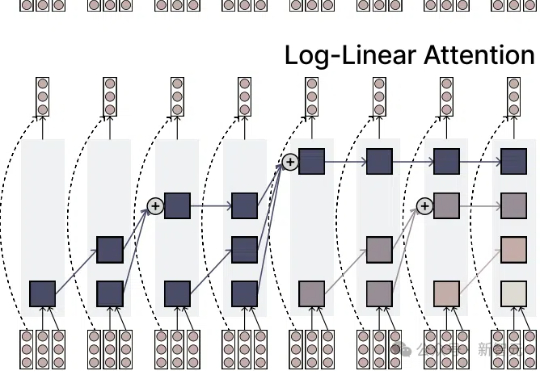
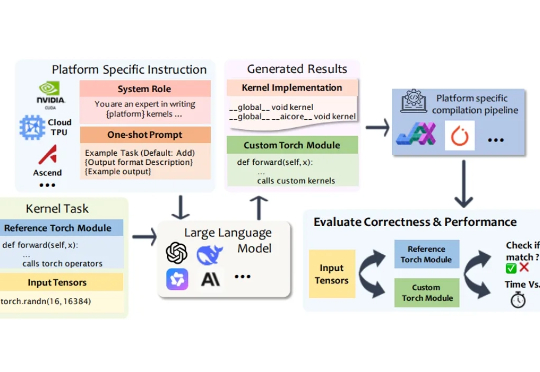
大模型能否为不同硬件平台生成高性能内核?南大、浙大提出跨平台内核生成评测框架MultiKernelBench在深度学习模型的推理与训练过程中,绝大部分计算都依赖于底层计算内核(Kernel)来执行。计算内核是运行在硬件加速器(如 GPU、NPU、TPU)上的 “小型高性能程序”,它负责完成矩阵乘法、卷积、归一化等深度学习的核心算子运算。
来自主题: AI技术研报
9019 点击 2025-08-25 15:44