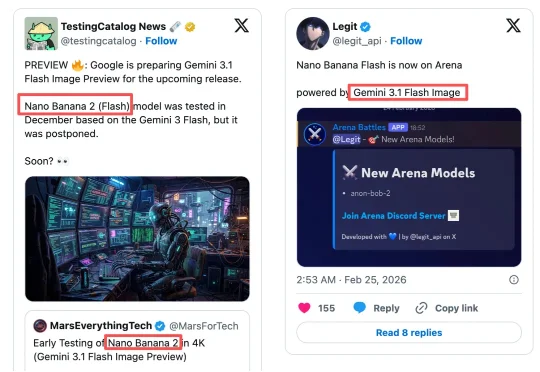
Nano Banana 2,泄露!
Nano Banana 2,泄露!过去48小时,Nano Banana 2成为AI开发者圈的热议话题。在海外社交平台X上,关于谷歌这款最新图片生成模型(又名Gemini 3.1 Flash Image预览版)将发布的帖子层出不穷,4K图片四处流传,各种猜测也甚嚣尘上。
来自主题: AI资讯
9622 点击 2026-02-25 21:41
 搜索
搜索
过去48小时,Nano Banana 2成为AI开发者圈的热议话题。在海外社交平台X上,关于谷歌这款最新图片生成模型(又名Gemini 3.1 Flash Image预览版)将发布的帖子层出不穷,4K图片四处流传,各种猜测也甚嚣尘上。

2026年2月12日,字节跳动正式发布新一代AI视频生成模型Seedance 2.0,同步接入豆包App、即梦App等平台,凭借广播级画质、丝滑运镜、多镜头叙事控制的工业级生成能力,迅速引发全球行业关注。

随着豆包大模型和seedance视频生成模型等业务的爆发,自研芯片成功后,字节有望大大降低其算力成本。
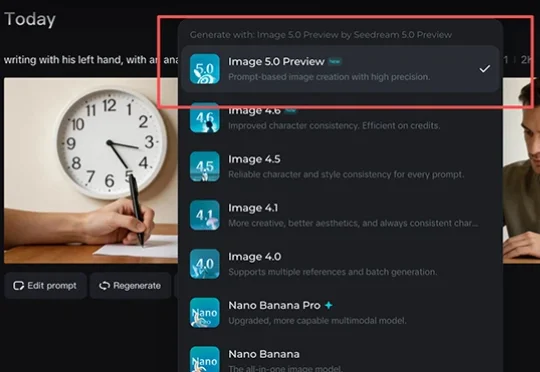
新模型对标Nano Banana Pro,能免费体验。Seedance 2.0的热度还没下去,字节新模型又来了!今日,字节图像生成模型Seedream 5.0 Preview在视频编辑应用剪映、剪映海外版Capcut、字节AI创作平台小云雀均已上线,在即梦AI平台开启灰度测试,图片生成可限时免费体验。
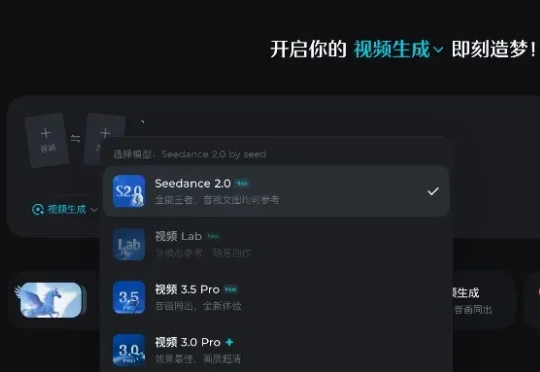
2月7日,字节跳动AI视频生成模型Seedance2.0开启灰度测试,该模型支持文本、图片、视频、音频素材输入,可以完成自分镜和自运镜,镜头移动后人物特征能够保持一致。
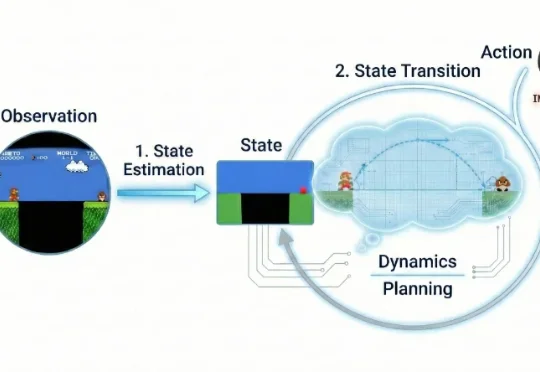
近年来,视频生成(Video Generation)与世界模型(World Models)已跃升为人工智能领域最炙手可热的焦点。从 Sora 到可灵(Kling),视频生成模型在运动连续性、物体交互与部分物理先验上逐渐表现出更强的「世界一致性」,让人们开始认真讨论:能否把视频生成从「逼真短片」推进到可用于推理、规划与控制的「通用世界模拟器」。
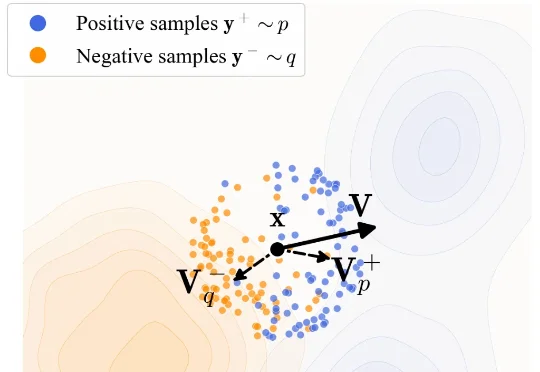
训练一个生成模型是很复杂的一件事儿。 从底层逻辑上来看,生成模型是一个逐步拟合的过程。与常见的判别类模型不同,判别类模型通常关注的是将单个样本映射到对应标签,而生成模型则关注从一个分布映射到另一个分布。

刚刚,何恺明团队提出全新生成模型范式漂移模型(Drifting Models)。

xAI“迄今为止最强大的视频音频生成模型”Grok Imagine 1.0版本,正式全面上线。
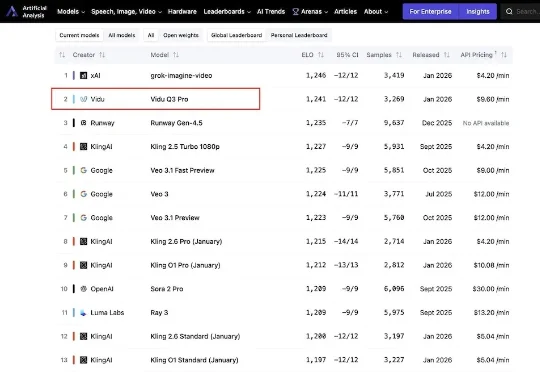
今日,来自生数科技的AI视频模型Vidu Q3 Pro登上国际权威AI基准平台Artificial Analysis榜单,位列中国第一,全球第二。这是最新榜单内,首个打入国际第一梯队的国产视频生成模型。