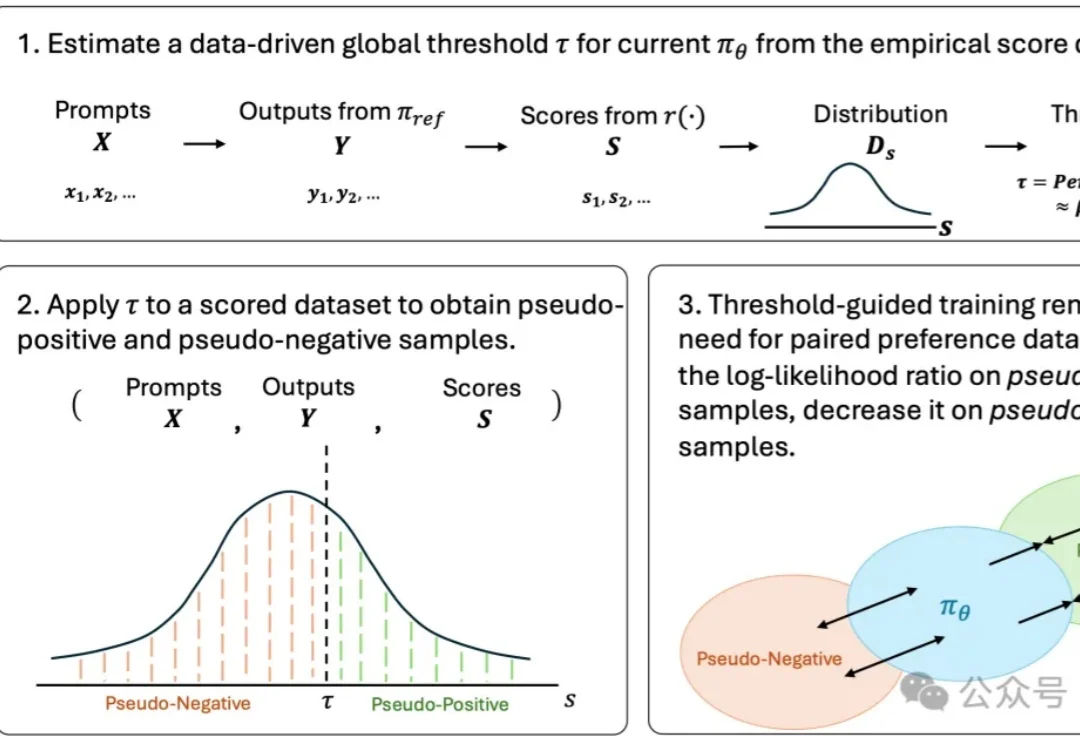
无需构造偏好对:TGO用标量反馈对齐视觉生成模型|ICML'26
无需构造偏好对:TGO用标量反馈对齐视觉生成模型|ICML'26生成模型的偏好对齐,可能正在进入一个新的阶段。
来自主题: AI技术研报
10402 点击 2026-05-18 09:54
 搜索
搜索
生成模型的偏好对齐,可能正在进入一个新的阶段。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。
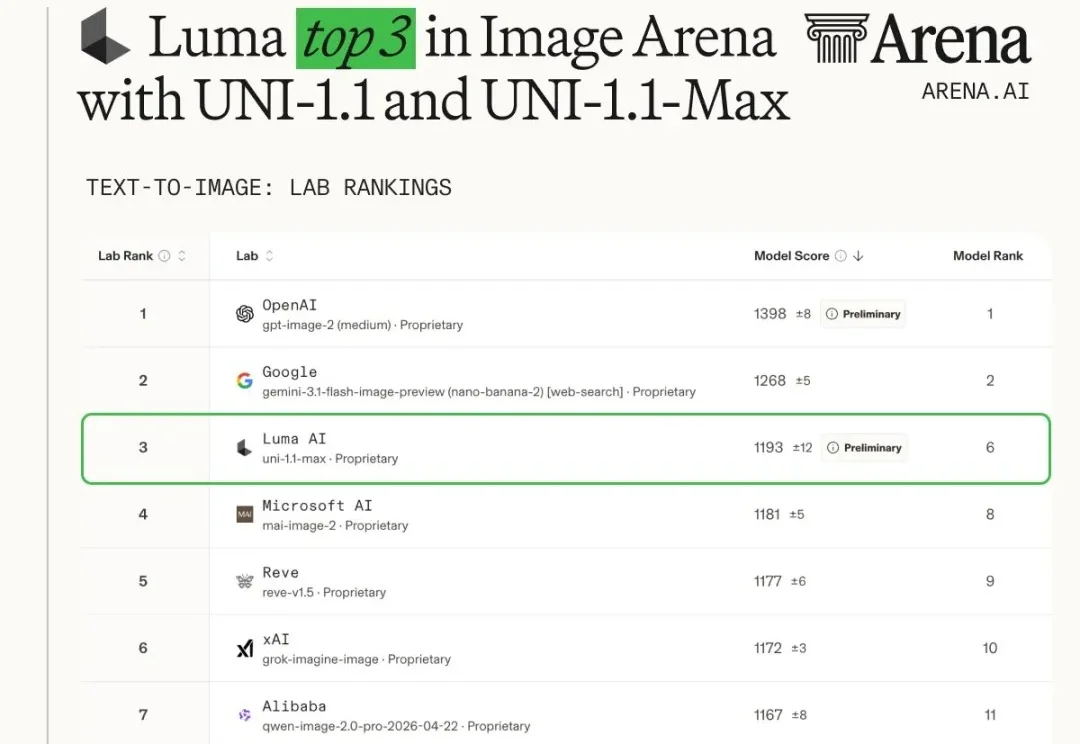
今年以来,图像生成模型的迭代节奏明显加快。
做过 AI 视频的都懂,除了 Seedance 2.0 本身的高定价,废片所烧掉的 token 算力也是一笔不小的开支。但在 Topview 平台,直接把这笔最大试错成本给重新定义了!热门视频生成模型 Seedance 2.0,加上最新的图片生成模型 Image 2,订阅 Ultra Plan,可不限量使用。

邓明扬现为 MIT 博士生,师从何恺明,主要研究生成模型。本科期间,他在 MIT 学习数学与计算机科学,也曾在 DeepMind 和 Meta 实习。更早之前,他曾获得 IMO 金牌和 IOI 金牌。2026 年,他以第一作者发表了 Drifting Models,尝试探索一种不同于传统路径的生成建模思路。

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。
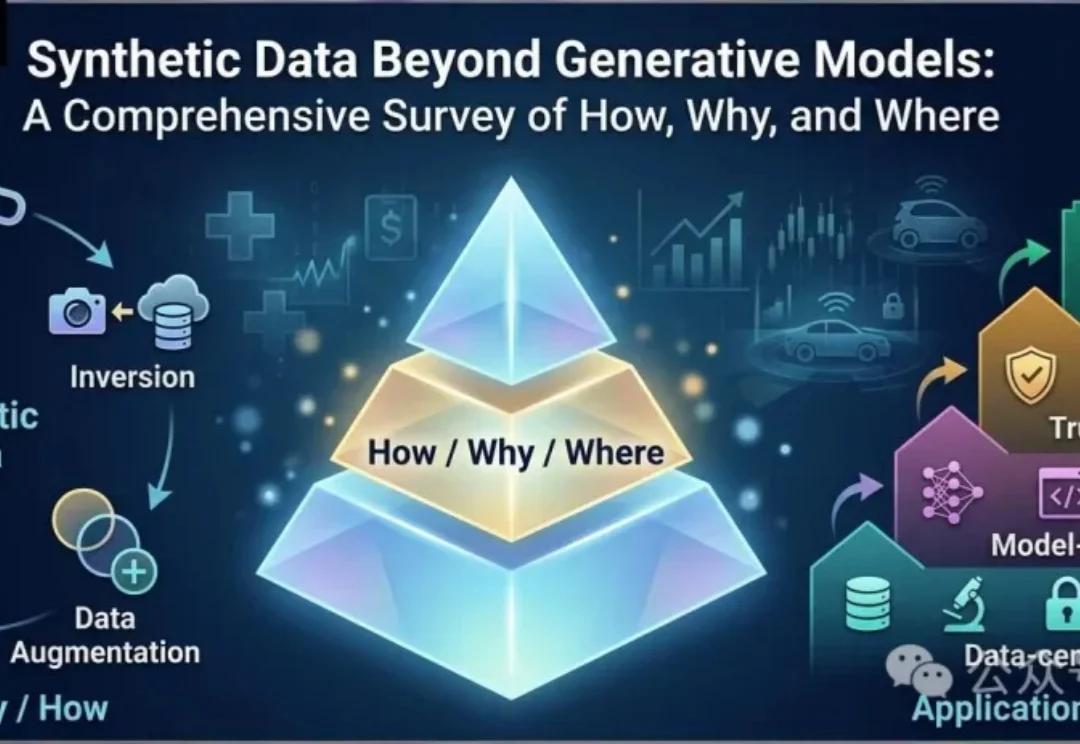
最新研究提出合成数据的全新分类框架,突破「生成模型=合成数据」的传统认知,涵盖反演、仿真与数据增强等方法,并按应用层次划分为数据中心AI、模型中心AI、可信AI和具身AI。
米哈游蔡浩宇的AI公司Anuttacon,首个视频模型正式曝光!Anuttacon技术团队成员@Ailing Zeng,在X上展示了全新视频角色表演生成模型——LPM 1.0。
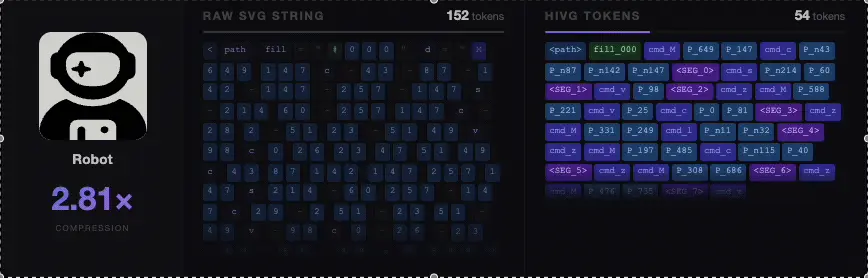
HiVG是一个面向SVG生成的层次化分词框架,在减少63.8% token数量的同时,以仅3B参数在多项指标上超越所有开源SVG模型和GPT-5.2等闭源模型。仅3B参数的HiVG,在SVG生成任务中多项指标超越了GPT-5.2、Claude-4.5-Sonnet等闭源模型。

过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。