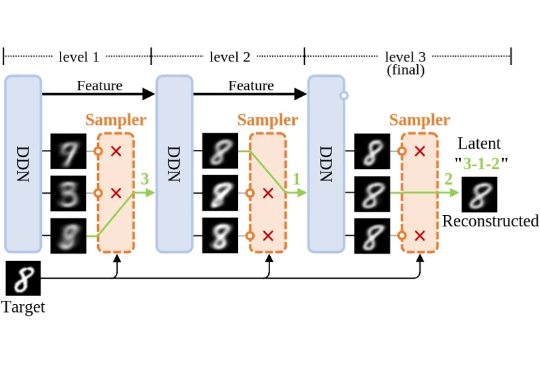
简单即强大:全新生成模型「离散分布网络DDN」是如何做到原理简单,性质独特?
简单即强大:全新生成模型「离散分布网络DDN」是如何做到原理简单,性质独特?本项工作提出了一种全新的生成模型:离散分布网络(Discrete Distribution Networks),简称 DDN。相关论文已发表于 ICLR 2025。
来自主题: AI技术研报
8285 点击 2025-08-17 13:35
 搜索
搜索
本项工作提出了一种全新的生成模型:离散分布网络(Discrete Distribution Networks),简称 DDN。相关论文已发表于 ICLR 2025。
制作一个视频需要几步?可以简单概括为:拍摄 + 配音 + 剪辑。 还记得 veo3 发布时引起的轰动吗?「音画同步」功能的革命性直接把其他视频生成模型按在地上摩擦,拍摄 + 配音 + 粗剪一键搞定。
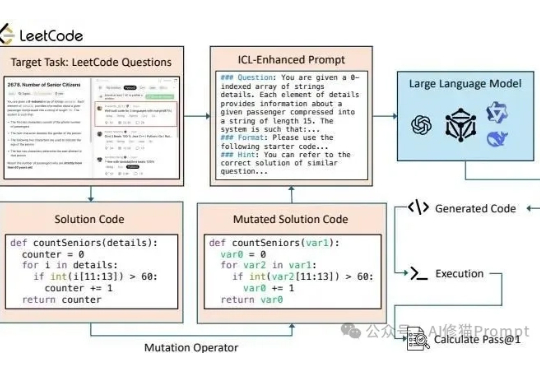
长久以来我们都知道在Prompt里塞几个好例子能让LLM表现得更好,这就像教小孩学东西前先给他做个示范。在Vibe coding爆火后,和各种代码生成模型打交道的人变得更多了,大家也一定用过上下文学习(In-Context Learning, ICL)或者检索增强生成(RAG)这类技术来提升它的表现。
近年来,文生图模型(Text-to-Image Models)飞速发展,从早期的 GAN 架构到如今的扩散和自回归模型,生成图像的质量和细节表现力实现了跨越式提升。这些模型大大降低了高质量图像创作的门槛,为设计、教育、艺术创作等领域带来了前所未有的便利。
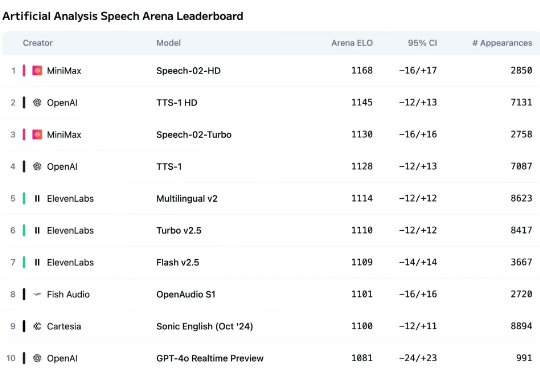
今天,MiniMax发布新一代语音生成模型Speech 2.5,再次刷新全球最强语音模型的上限。

7月底 Black Forest Labs 和 Krea 合作开发的高级文本到图像生成模型 Flux.1 Krea Dev,最近终于有时间进行测评了。Flux.1 Krea Dev 是基于FLUX.1 dev 模型进行蒸馏的,参数规模12B,专注于提升图像的美学和真实感,避免了常见的 AI 生成痕迹(过度饱和或不自然高光等等),更倾向于追求自然细节、照片级真实感和多样性。

通义模型家族,刚刚又双叒开源了,这次是Qwen-Image——一个200亿参数、采用MMDiT架构的图像生成模型。 这也是通义千问系列中首个图像生成基础模型。

电影级视频生成模型来了。
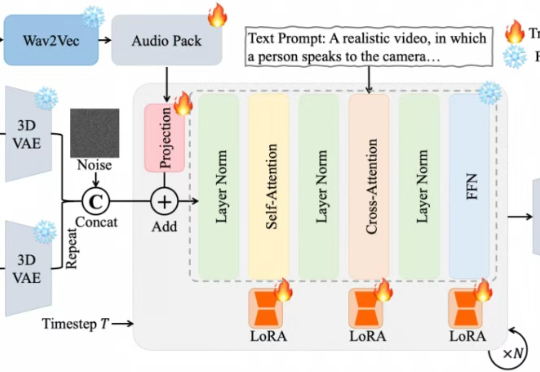
近期,夸克技术团队和浙江大学联合开源了OmniAvatar,这是一个创新的音频驱动全身视频生成模型,只需要输入一张图片和一段音频,OmniAvatar即可生成相应视频,且显著提升了画面中人物的唇形同步细节和全身动作的流畅性。此外,还可通过提示词进一步精准控制人物姿势、情绪、场景等要素。

6月30日,OpenAI支持的Chai Discovery推出Chai-2,这款多模态生成模型展现出强大的抗体设计能力,一经发布便引起巨大轰动。