
突发!姚顺雨后,清华95后庞天宇加入腾讯,任混元「主任研究员」
突发!姚顺雨后,清华95后庞天宇加入腾讯,任混元「主任研究员」继OpenAI大神姚顺雨之后,腾讯AI再添猛将!95后清华「天骄」庞天宇,正式入职腾讯,出任混元首席研究科学家,负责多模态强化学习。腾讯的大模型「梦之队」版图,正在极速扩张。
来自主题: AI资讯
10234 点击 2026-01-30 22:54
 搜索
搜索
继OpenAI大神姚顺雨之后,腾讯AI再添猛将!95后清华「天骄」庞天宇,正式入职腾讯,出任混元首席研究科学家,负责多模态强化学习。腾讯的大模型「梦之队」版图,正在极速扩张。

清华校友创业,美团腾讯持股。
今天,清华大学 THUNLP 实验室、东北大学 NEUIR 实验室、OpenBMB 、面壁智能与 AI9Stars 联合发布 UltraRAG 3.0 ,针对上述痛点,为科研工作者与开发者打造更懂开发者的技术框架,具备 3 大核心优势:

这篇新论文提出了一种非常简单的新激活层 Derf(Dynamic erf),让「无归一化(Normalization-Free)」的 Transformer 不仅能稳定训练,还在多个设置下性能超过了带 LayerNorm 的标准 Transformer。
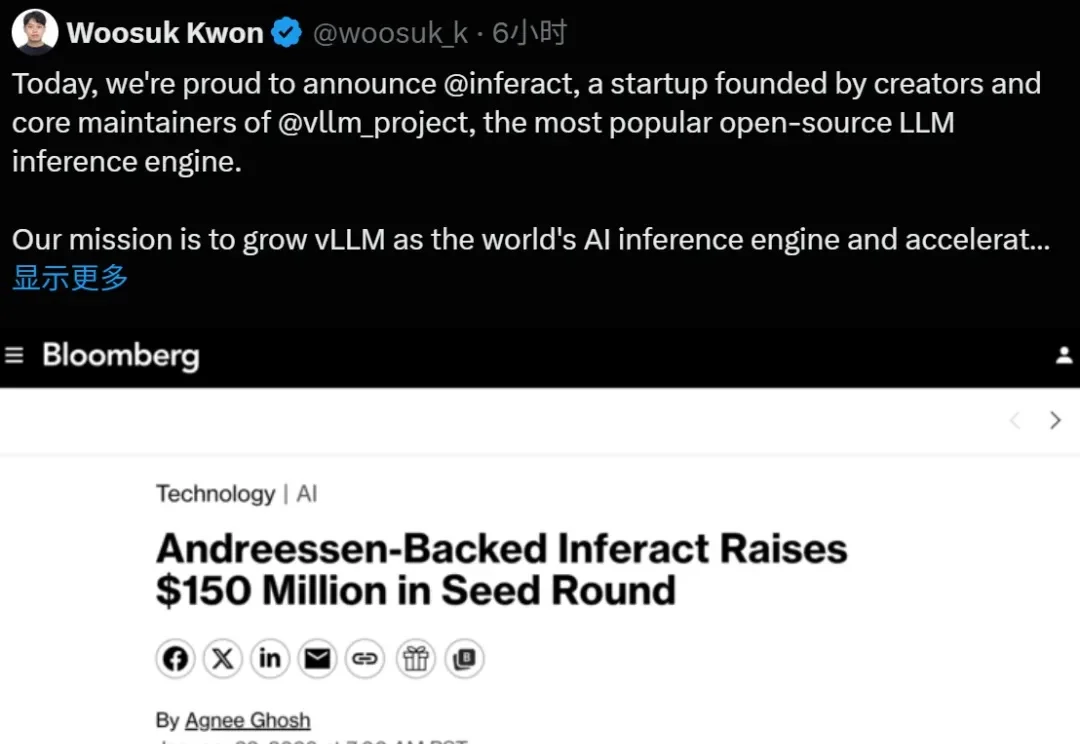
大模型推理的基石 vLLM,现在成为创业公司了。
如何让机器人同时具备“本能反应”与复杂运动能力?
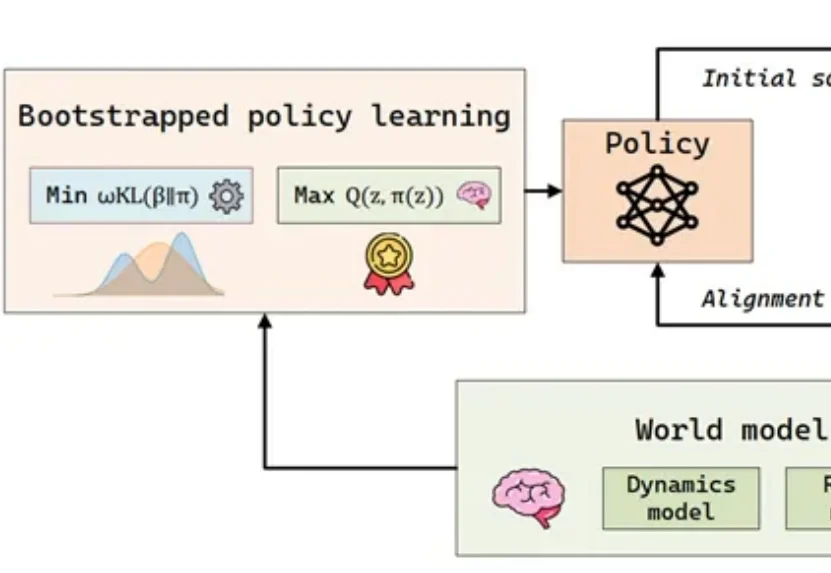
在具身智能(Embodied AI)的快速发展中,样本效率已成为制约智能体从实验室环境走向复杂开放世界的瓶颈问题。
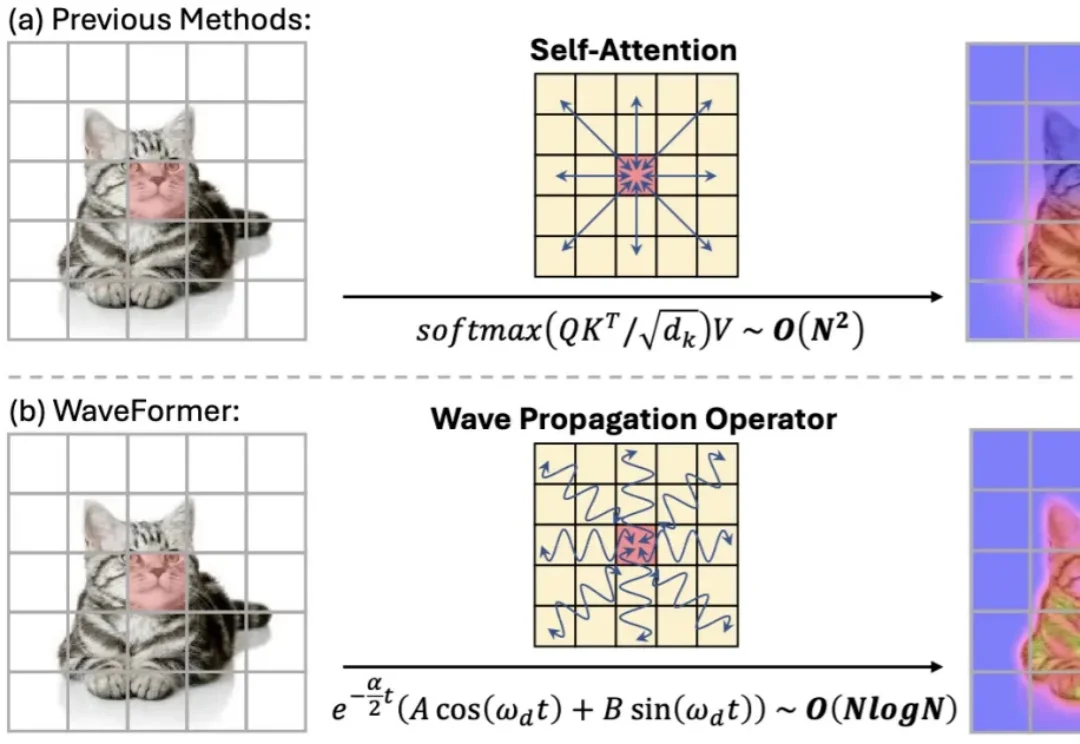
“全局交互” 几乎等同于 self-attention:每个 token 都能和所有 token 对话,效果强,但代价也直观 —— 复杂度随 token 数平方增长,分辨率一高就吃不消。现有方法大多从 “相似度匹配” 出发(attention),或从 “扩散 / 传导” 出发(热方程类方法)。但热方程本质上是一个强低通滤波器:随着传播时间增加,高频细节(边缘、纹理)会迅速消失,导致特征过平滑。

清华姚班、普林斯顿博士、前 OpenAI 核心成员、27 岁、首席 AI 科学家……当这些标签堆砌在一个人身上时,你很难不感受到一种来自智商层面的压迫感。
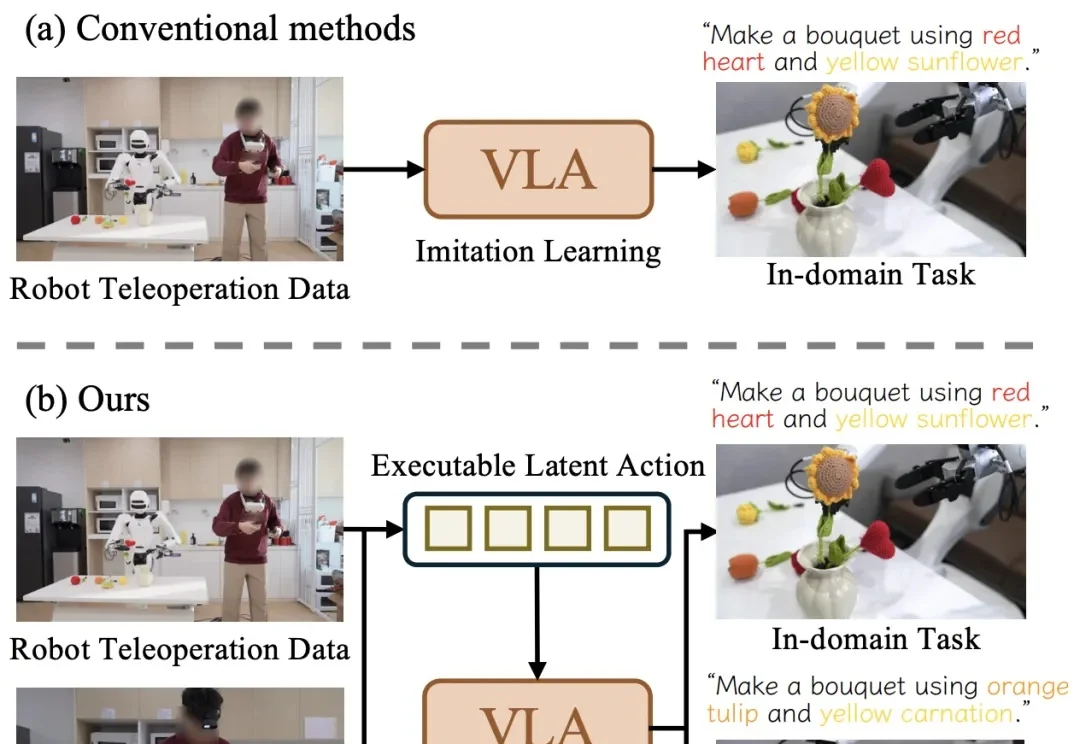
近日,清华大学与星尘智能、港大、MIT 联合提出基于对比学习的隐空间动作预训练(Contrastive Latent Action Pretraining, CLAP)框架。这个框架能够将视频中提纯的运动空间与机器人的动作空间进行对齐,也就是说,机器人能够直接从视频中学习技能!