
AI助手集体免费,微软OpenAI谷歌火力全开!Gemini 18万次代码补全白送
AI助手集体免费,微软OpenAI谷歌火力全开!Gemini 18万次代码补全白送谷歌Gemini 2.0代码助手免费,每月18万次代码补全,支持超大上下文窗口。微软Copilot语音与深度思考功能,同样免费!OpenAI也免费推出了GPT-4o mini高级语音模式。
来自主题: AI资讯
8940 点击 2025-02-27 16:42
 搜索
搜索
谷歌Gemini 2.0代码助手免费,每月18万次代码补全,支持超大上下文窗口。微软Copilot语音与深度思考功能,同样免费!OpenAI也免费推出了GPT-4o mini高级语音模式。
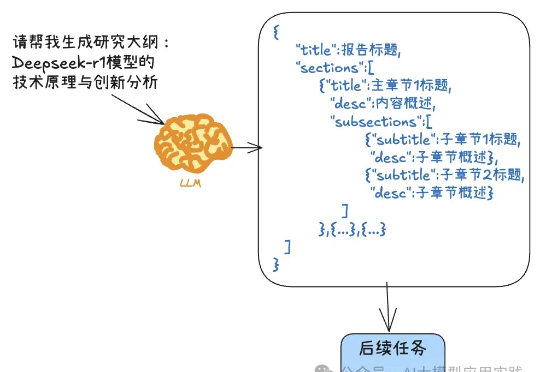
DeepSeek-R1这样的推理模型有着强大的深度思考能力,但也有着一些不同于通用模型的特点与用法,比如不支持函数调用,不支持结构化输出,o1甚至不支持系统提示(System Prompt)等。尽管这和它们的使用场景有关,但有时也会带来不便。今天我们就来说说结构化输出这个常见的问题。

当 DeepSeek 在春节期间爆火,所有人都在猜测国内 AI 厂商将会如何跟进时,腾讯元宝上周宣布接入满血版 DeepSeek R1,APPSO 体验后彻底告别了「服务器繁忙」。而就在刚刚,腾讯元宝正式推出自研的 Hunyuan T1 快速深度思考模型,给了我们两种深度思考模型的选择,APPSO 也提前体验了这款模型,第一时间给大家送上使用指南。
凌晨的时候,使用deepseek深度思考+联网搜索做了一个AI产品卡片,展示效果很惊艳,如下是做了几个关于AI教育智能硬件产品的特性图,放几个看看效果。我们需要深度思考+联网搜索的能力,需要根据关键词去检索到详细的信息源,因此联网搜索必不可少,然后根据如上搜索整合的信息让deepseek自适应地根据内容进行排版,选择不同地风格,呈现不同地样式。

今年爆火的国产AI应用DeepSeek化身最火爆的赛博算命师,各种东西方玄学,如《三命通会》、《滴天髓》、《渊海子平》这些你压根没听过的书籍,只需要它“深度思考”几秒钟就能手到擒来。
DeepSeek-R1因其游刃有余的用户需求响应能力,尤其是其独特的“深度思考(DeepThink)”模式及卓越的推理能力,在这个春天绝响全球。为了让更多领域的用户切实便捷地开展体验,超算互联网平台第一时间上线了DeepSeek Chatbot可视化界面功能。
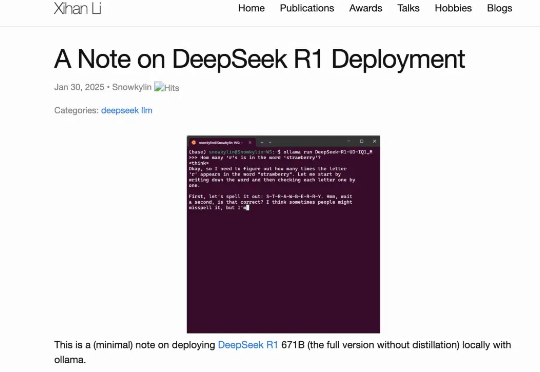
过年这几天,DeepSeek 算是彻底破圈了,火遍大江南北,火到人尽皆知。虽然网络版和 APP 版已经足够好用,但把模型部署到本地,才能真正实现独家定制,让 DeepSeek R1 的深度思考「以你为主,为你所用」。

2月1日,就在OpenAI上新o3-mini推理模型同时,DeepSeek深度思考和联网搜索功能被爆暂时停止服务。一天之后,经字母榜实测,目前DeepSeek深度思考服务已恢复正常,但联网搜索仍提示“由于技术原因,暂不可用”。
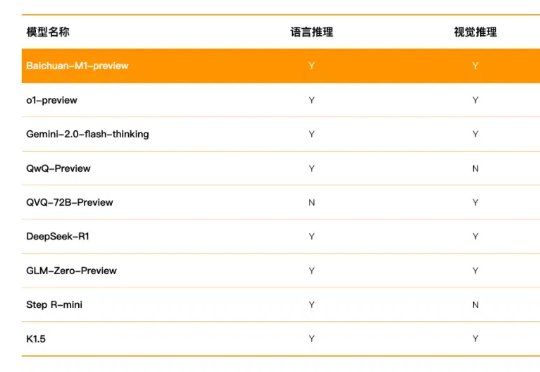
就在本周,Kimi 的新模型打开了强化学习 Scaling 新范式,DeepSeek R1 用开源的方式「接班了 OpenAI」,谷歌则把 Gemini 2.0 Flash Thinking 的上下文长度延伸到了 1M。1 月 24 日上午,百川智能重磅发布了国内首个全场景深度思考模型,把这一轮军备竞赛推向了高潮。

刚刚发布的豆包大模型1.5,不仅多模态能力全面提升,霸榜多个基准;更难得的是,它在训练过程中从未使用过任何其他模型生成的数据,坚决不走蒸馏「捷径」。