
浙大帮、清华帮,谁会是AI时代的新C9
浙大帮、清华帮,谁会是AI时代的新C9开年以来,DeepSeek的梁文锋、Manus的肖弘,成为中国AI圈冉冉升起的新星。培养他们的母校浙江大学和华中科技大学也一并沾光。
来自主题: AI资讯
11121 点击 2025-03-13 10:19
 搜索
搜索
开年以来,DeepSeek的梁文锋、Manus的肖弘,成为中国AI圈冉冉升起的新星。培养他们的母校浙江大学和华中科技大学也一并沾光。

当地时间2月17日,埃隆·马斯克旗下人工智能公司xAI直播发布新一代人工智能大模型Grok 3,马斯克直接说这是“地表最聪明AI”。 而更吸引国内观众注意的,则是直播画面里的几张华人面孔。据统计,xAI创始团队四成是华人,其中还包括一位浙江大学毕业的张国栋。
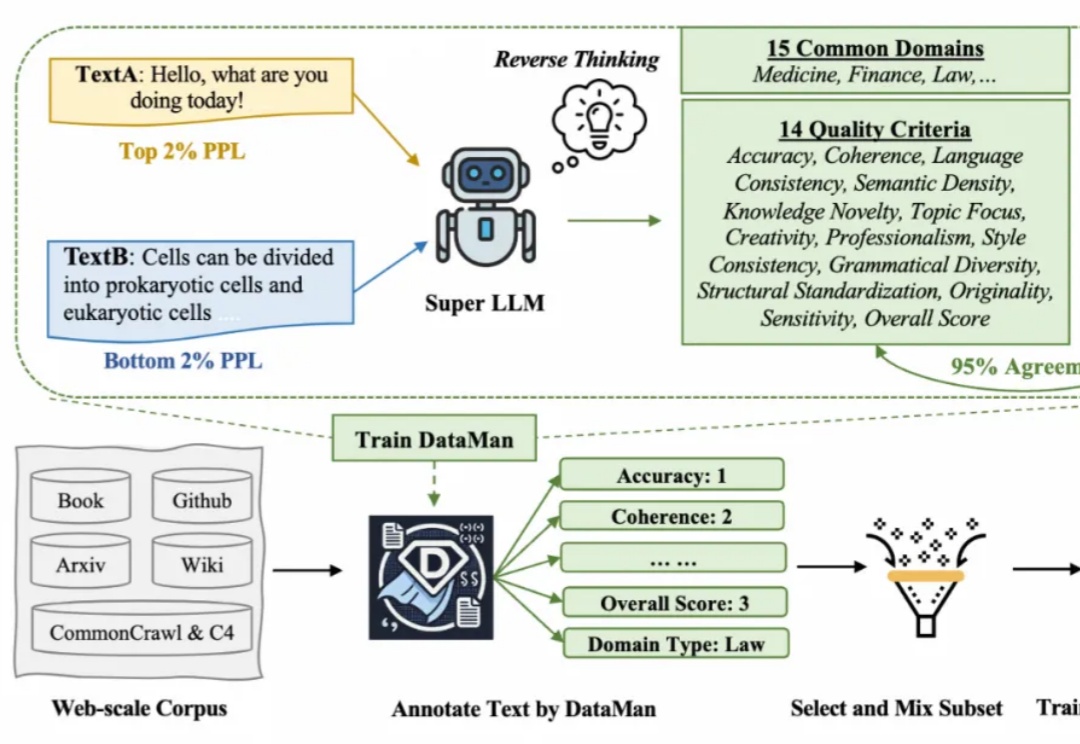
在 Scaling Law 背景下,预训练的数据选择变得越来越重要。然而现有的方法依赖于有限的启发式和人类的直觉,缺乏全面和明确的指导方针。在此背景下,该研究提出了一个数据管理器 DataMan,其可以从 14 个质量评估维度对 15 个常见应用领域的预训练数据进行全面质量评分和领域识别。

全球空间智能第一股来了!来自中国,来自杭州。2月14日,空间智能独角兽群核科技正式向港交所递交招股说明书,启动IPO进程,冲击“全球空间智能第一股”,摩根大通、建银国际为联席保荐人。
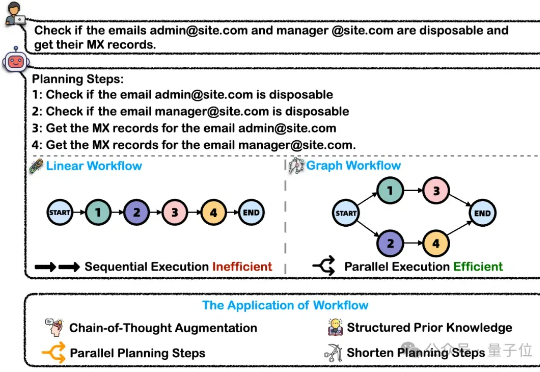
在处理这类复杂任务的过程中,大模型智能体将问题分解为可执行的工作流(Workflow)是关键的一步。然而,这一核心能力目前缺乏完善的评测基准。为解决上述问题,浙大通义联合发布WorfBench——一个涵盖多场景和复杂图结构工作流的统一基准,以及WorfEval——一套系统性评估协议,通过子序列和子图匹配算法精准量化大模型生成工作流的能力。

梁文锋,一个出生于广东五线城市的80后,父亲是一名小学老师。尽管家境平凡,他却凭借卓越的才智和不懈的努力,书写了一段非凡的人生篇章。自小便对数学和计算机科学展现出浓厚兴趣的梁文锋,17岁那年以优异的成绩考入了浙江大学,主修软件工程,专攻人工智能方向。大学期间,他不仅学业优异,还积极参与科研项目,为自己的未来奠定了坚实的基础。
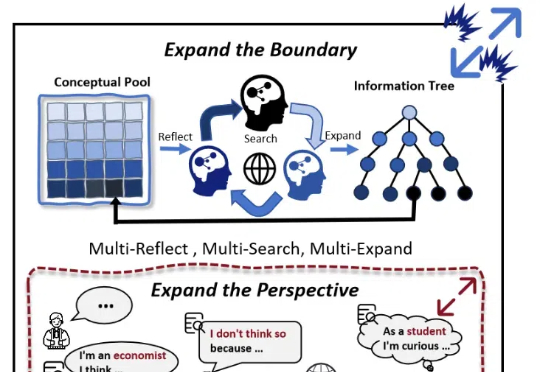
随着大模型(LLMs)的发展,AI 写作取得了较大进展。然而,现有的方法大多依赖检索知识增强生成(RAG)和角色扮演等技术,其在信息的深度挖掘方面仍存在不足,较难突破已有知识边界,导致生成的内容缺乏深度和原创性。
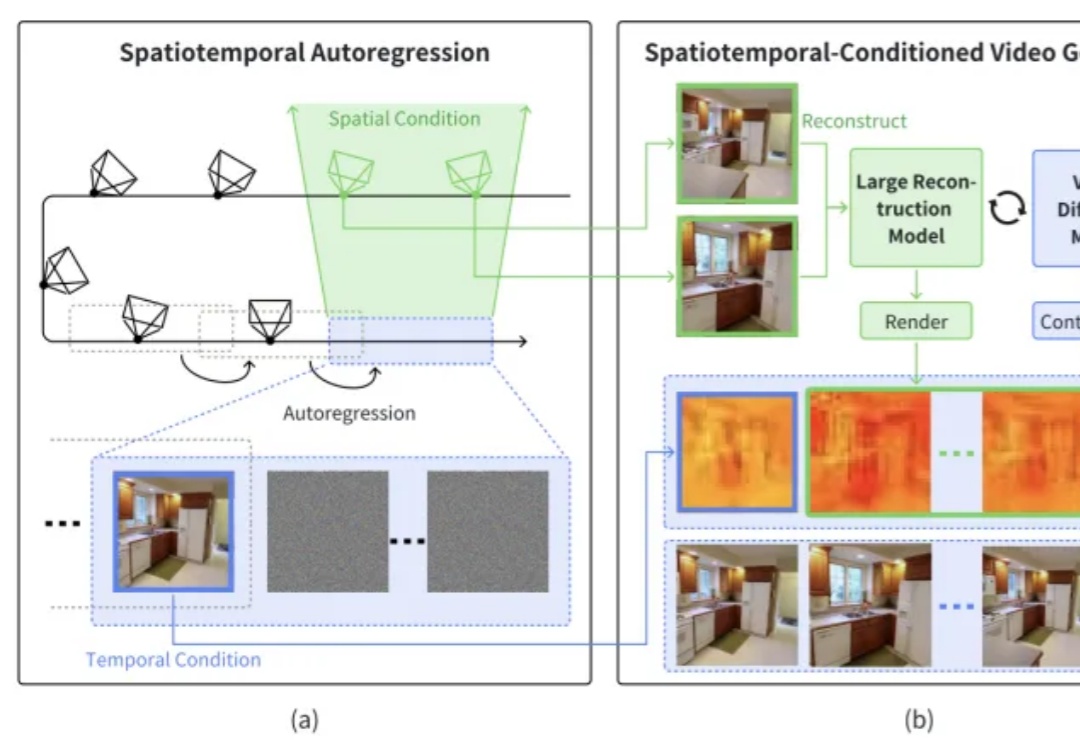
本文介绍了一篇由浙江大学章国锋教授和商汤科技研究团队联合撰写的论文《StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation》。
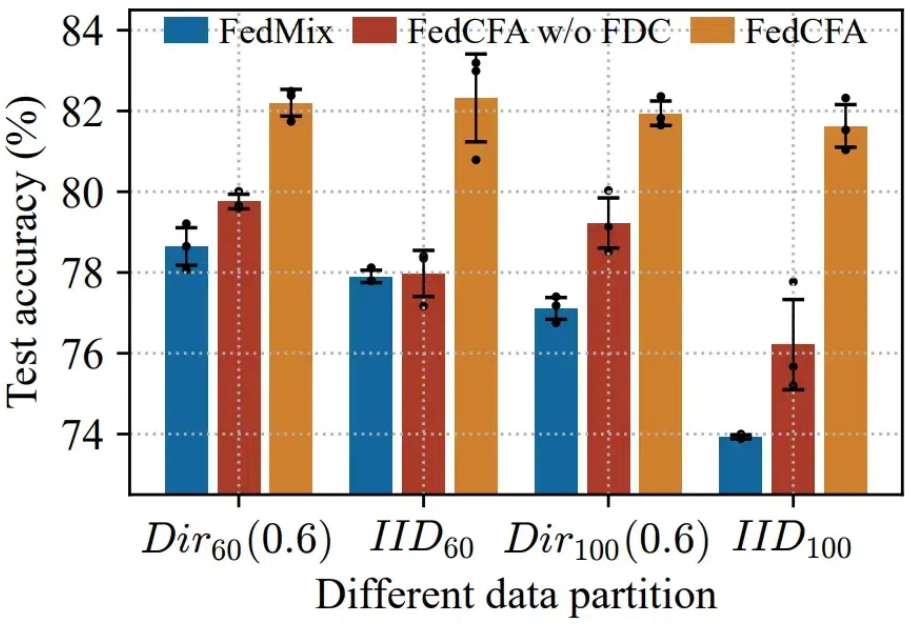
本地训练的客户模型忽视了全局数据中明显的更广泛的模式,聚合的全局模型可能无法准确反映所有客户端的数据分布,甚至可能出现「辛普森悖论」—— 多端各自数据分布趋势相近,但与多端全局数据分布趋势相悖。
在人工智能领域,具有挑战性的模拟环境对于推动多智能体强化学习(MARL)领域的发展至关重要。在合作式多智能体强化学习环境中,大多数算法均通过星际争霸多智能体挑战(SMAC)作为实验环境来验证算法的收敛和样本利用率。