Meta新注意力机制突破Transformer上限,还用上了OpenAI的开源技术
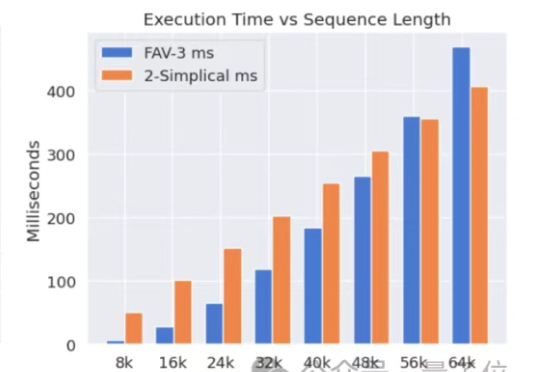
Meta新注意力机制突破Transformer上限,还用上了OpenAI的开源技术Meta挖走OpenAI大批员工后,又用OpenAI的技术搞出新突破。新架构名为2-Simplicial Transformer,重点是通过修改标准注意力,让Transformer能更高效地利用训练数据,以突破当前大模型发展的数据瓶颈。
来自主题: AI技术研报
8068 点击 2025-07-08 12:01
 搜索
搜索
Meta挖走OpenAI大批员工后,又用OpenAI的技术搞出新突破。新架构名为2-Simplicial Transformer,重点是通过修改标准注意力,让Transformer能更高效地利用训练数据,以突破当前大模型发展的数据瓶颈。
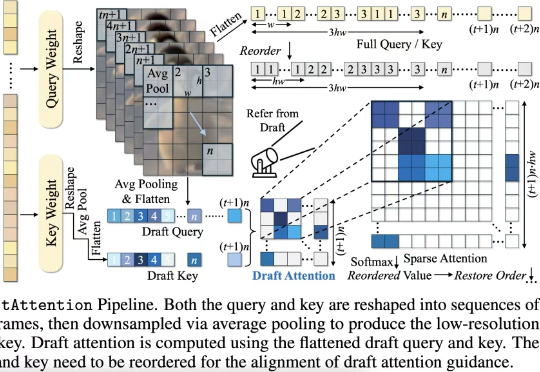
在高质量视频生成任务中,扩散模型(Diffusion Models)已经成为主流。然而,随着视频长度和分辨率的提升,Diffusion Transformer(DiT)模型中的注意力机制计算量急剧增加,成为推理效率的最大瓶颈。
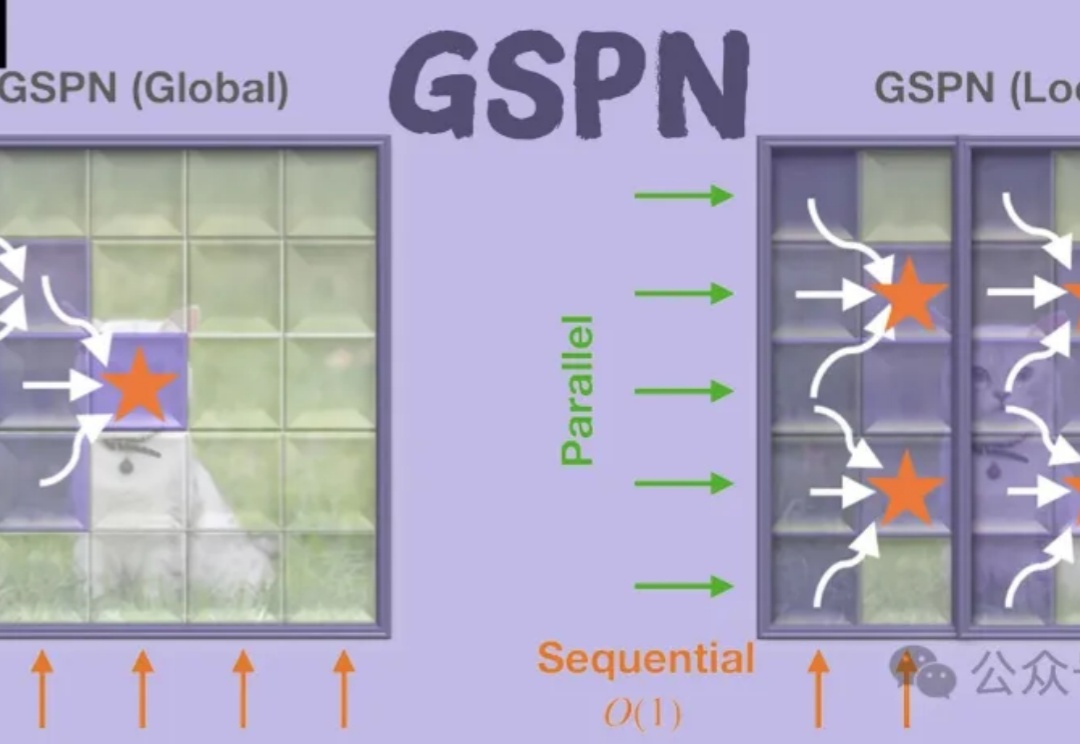
GSPN是一种新型视觉注意力机制,通过线性扫描和稳定性-上下文条件,高效处理图像空间结构,显著降低计算复杂度。通过线性扫描方法建立像素间的密集连接,并利用稳定性-上下文条件确保稳定的长距离上下文传播,将计算复杂度显著降低至√N量级。

未来AI路线图曝光!谷歌发明了Transformer,但在路线图中承认:现有注意力机制无法实现「无限上下文」,这意味着下一代AI架构,必须「从头重写」。Transformer的时代,真的要终结了吗?在未来,谷歌到底有何打算?

本文深入剖析 MiniCPM4 采用的稀疏注意力结构 InfLLM v2。作为新一代基于 Transformer 架构的语言模型,MiniCPM4 在处理长序列时展现出令人瞩目的效率提升。传统Transformer的稠密注意力机制在面对长上下文时面临着计算开销迅速上升的趋势,这在实际应用中造成了难以逾越的性能瓶颈。
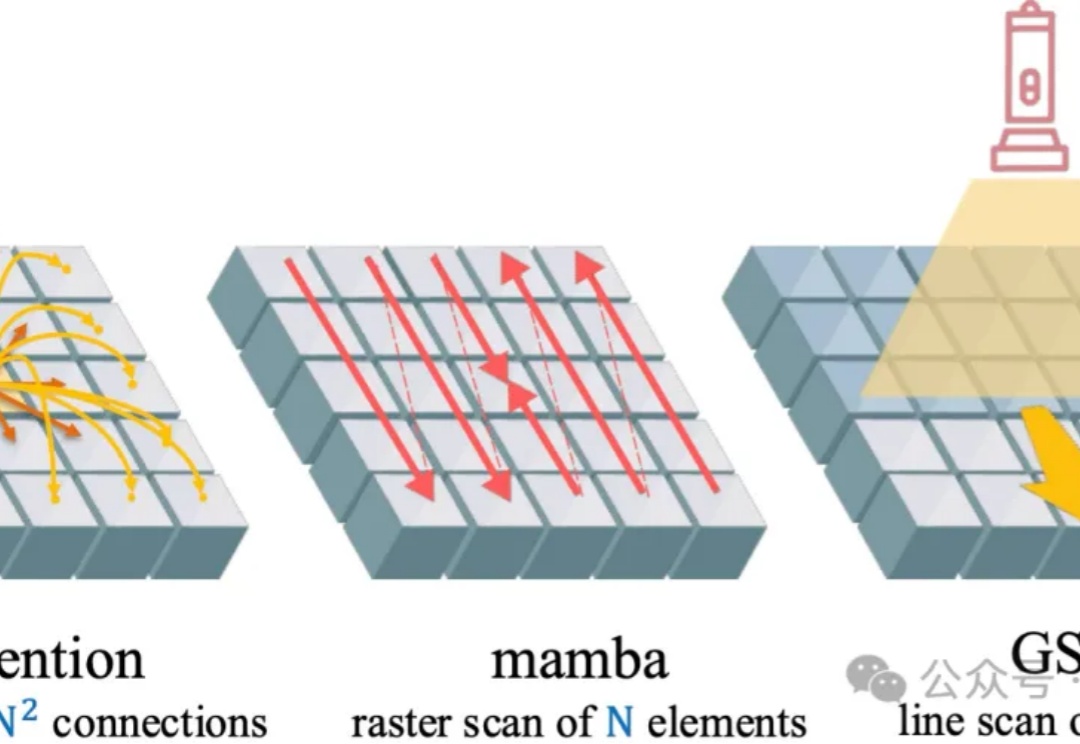
视觉注意力机制,又有新突破,来自香港大学和英伟达。
在大语言模型蓬勃发展的背景下,Transformer 架构依然是不可替代的核心组件。尽管其自注意力机制存在计算复杂度为二次方的问题,成为众多研究试图突破的重点
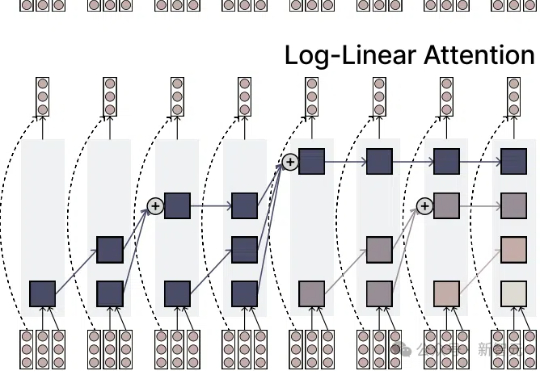
注意力机制的「平方枷锁」,再次被撬开!一招Fenwick树分段,用掩码矩阵,让注意力焕发对数级效率。更厉害的是,它无缝对接线性注意力家族,Mamba-2、DeltaNet 全员提速,跑分全面开花。长序列处理迈入log时代!
曾撼动Transformer统治地位的Mamba作者之一Tri Dao,刚刚带来新作——提出两种专为推理“量身定制”的注意力机制。

研究者针对 few-shot 图像编辑提出一个新的自回归模型结构 ——InstaManip,并创新性地提出分组自注意力机制(group self-attention),在此任务上取得了优异的效果。