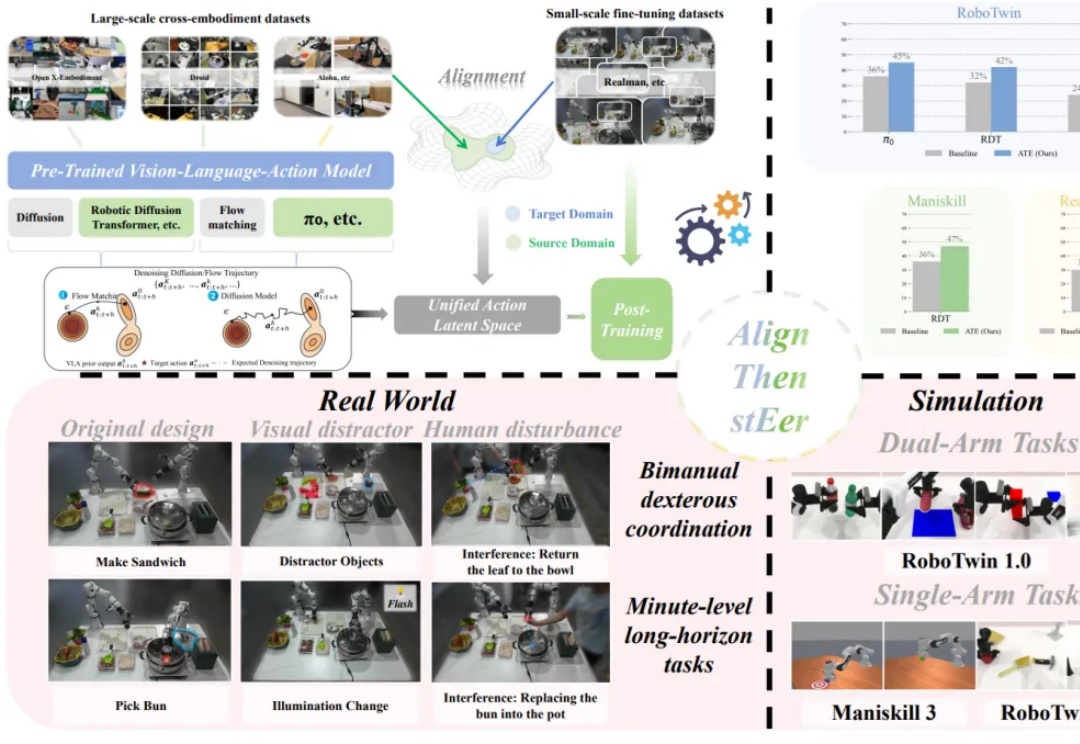
RL 将如何提高具身大模型 VLA 泛化性?清华大学团队NeurIPS 2025文章分析 RL 与 SFT 泛化性差异
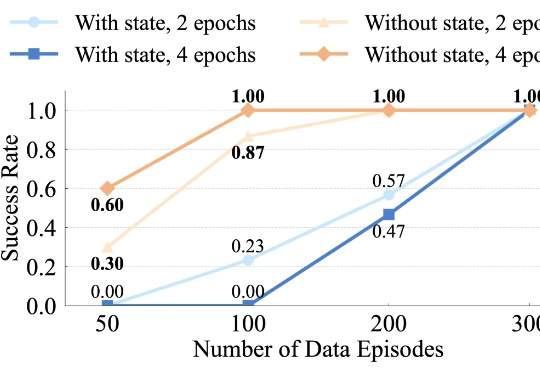
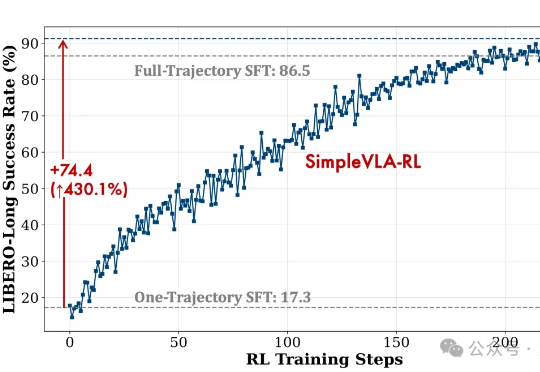
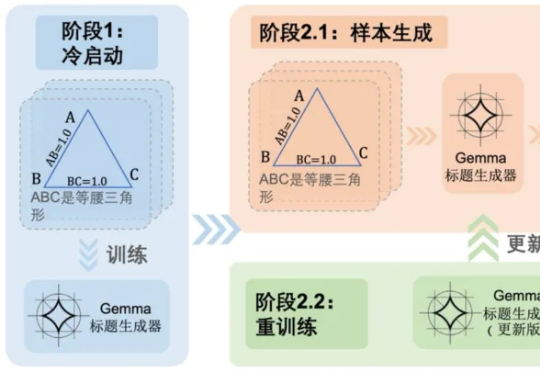
RL 将如何提高具身大模型 VLA 泛化性?清华大学团队NeurIPS 2025文章分析 RL 与 SFT 泛化性差异在具身智能领域,视觉 - 语言 - 动作(VLA)大模型正展现出巨大潜力,但仍面临一个关键挑战:当前主流的有监督微调(SFT)训练方式,往往让模型在遇到新环境或任务时容易出错,难以真正做到类人般的泛化
来自主题: AI技术研报
10091 点击 2025-10-13 10:28