

天下苦SaaS已久,企业级AI得靠「结果」说话
天下苦SaaS已久,企业级AI得靠「结果」说话天下苦SaaS已久。
来自主题: AI资讯
10343 点击 2025-12-22 16:39
天下苦SaaS已久。

浙江大学ReLER团队开源ContextGen框架,攻克多实例图像生成中布局与身份协同控制难题。基于Diffusion Transformer架构,通过双重注意力机制,实现布局精准锚定与身份高保真隔离,在基准测试中超越开源SOTA模型,对标GPT-4o等闭源系统,为定制化AI图像生成带来新突破。
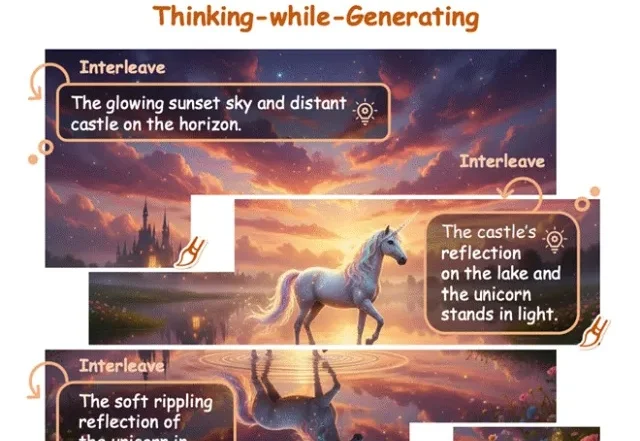
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。

长期以来,具身智能系统主要依赖「感知 - 行动」的反应式回路,缺乏对未来的预测能力。而世界模型的引入,让智能体拥有了「想象」未来的能力。

还记得之前非常火的雪宝Olaf机器人吗?

2025年底,最令人印象深刻的AI圈大事莫过于Gemini 3 Flash的发布。
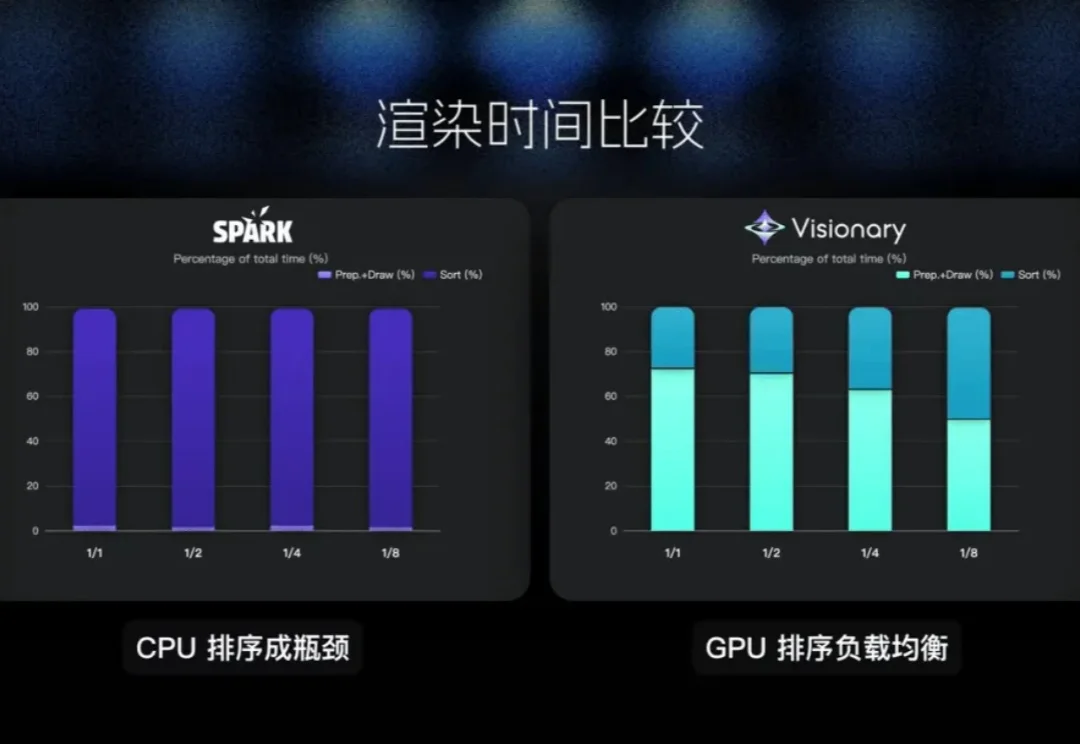
在李飞飞团队 WorldLabs 推出 Marble、引爆「世界模型(World Model)」热潮之后,一个现实问题逐渐浮出水面:世界模型的可视化与交互,依然严重受限于底层 Web 端渲染能力。
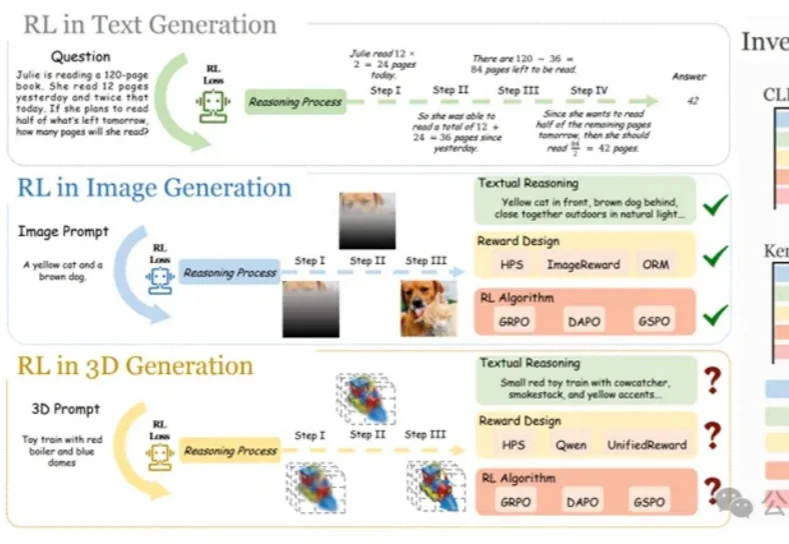
在大语言模型和文生图领域,强化学习(RL)已成为提升模型思维链与生成质量的关键方法。
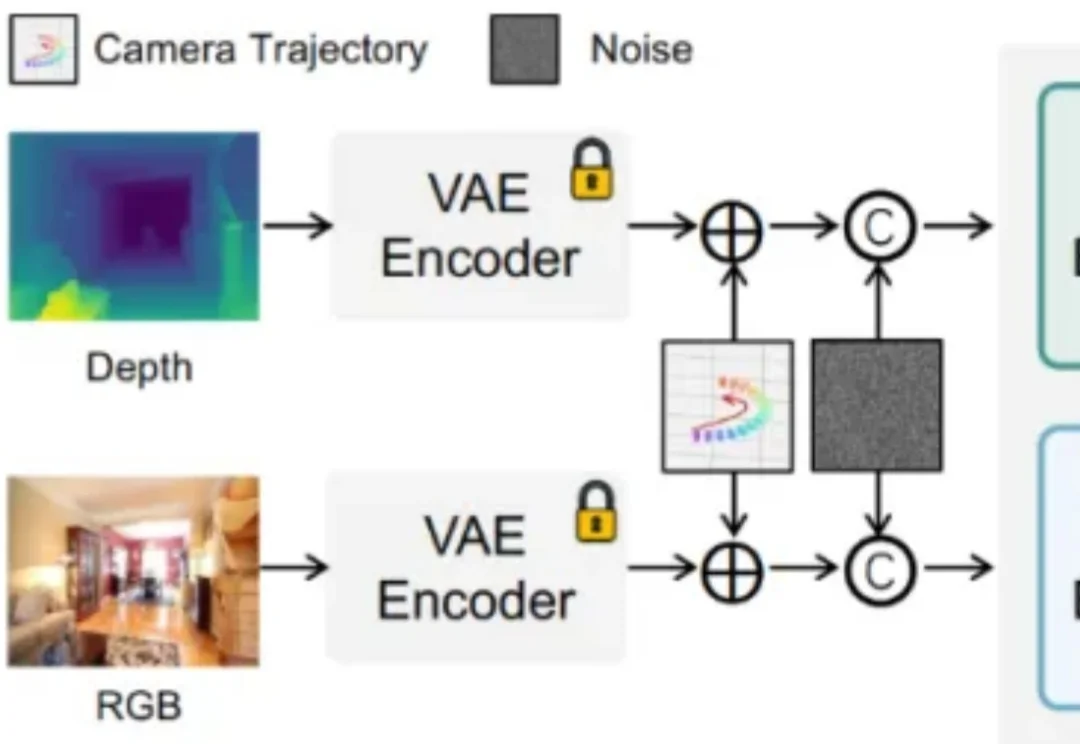
你的生成模型真的「懂几何」吗?还是只是在假装对齐相机轨迹?

尽管扩散模型在单图像生成上已经日渐成熟,但当任务升级为高度定制化的多实例图像生成(Multi-Instance Image Generation, MIG)时,挑战随之显现: