

华人一作!Meta等复刻AlphaZero神话,AI甩开人类自修成神
华人一作!Meta等复刻AlphaZero神话,AI甩开人类自修成神当模型学会「左右互搏」的那一刻,平庸的模仿时代结束了,真正的硅基编程奇迹刚刚开始。
来自主题: AI技术研报
10259 点击 2025-12-29 09:06
当模型学会「左右互搏」的那一刻,平庸的模仿时代结束了,真正的硅基编程奇迹刚刚开始。
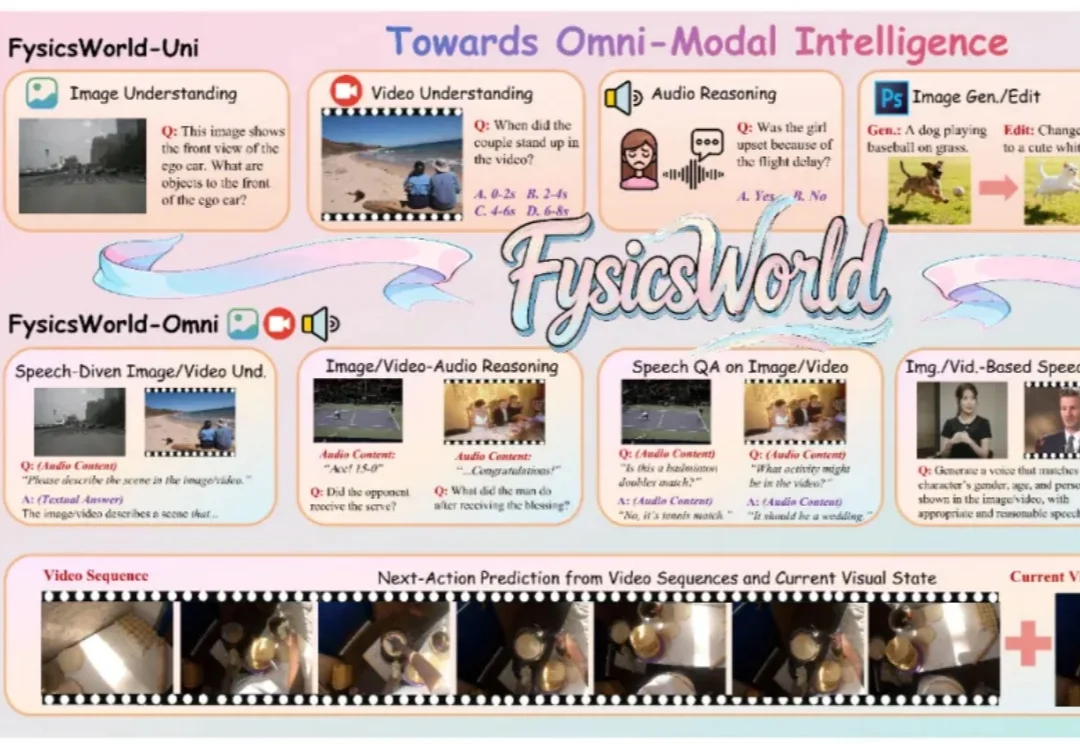
近年来,多模态大语言模型正在经历一场快速的范式转变,新兴研究聚焦于构建能够联合处理和生成跨语言、视觉、音频以及其他潜在感官模态信息的统一全模态大模型。此类模型的目标不仅是感知全模态内容,还要将视觉理解和生成整合到统一架构中,从而实现模态间的协同交互。
近日,部分L3级自动驾驶车型已经通过工信部批准正式上路,这标志着这我国自动驾驶产业的新阶段。
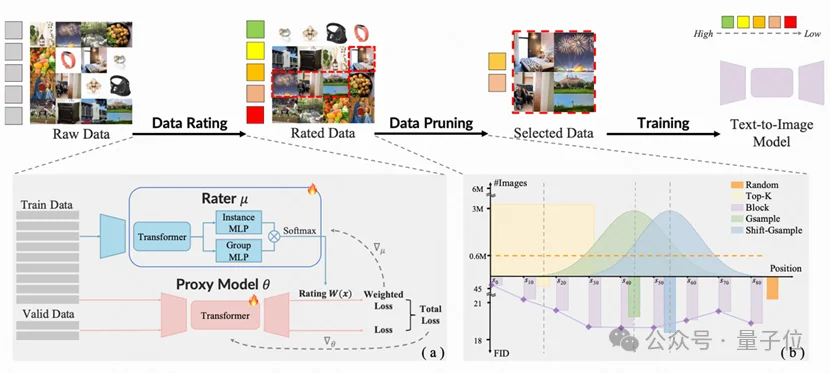
由香港大学丁凯欣领导,联合华南理工大学周洋以及快手科技Kling团队共同完成的这项研究,开发出了一个名为“炼金师”(Alchemist)的AI系统。它就像一位挑剔的大厨,能从海量图片数据中精准挑选出最有价值的一半。
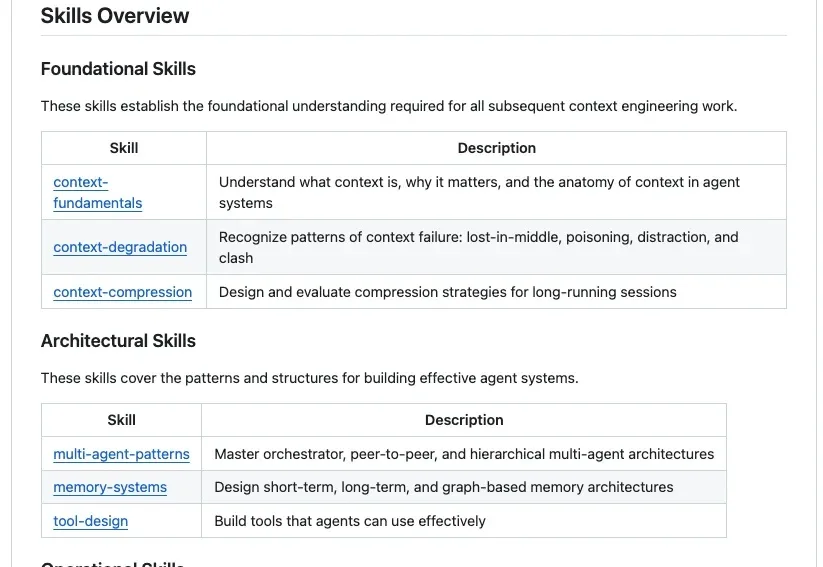
GitHub上最近出现了一个非常火的项目Agent-Skills-for-Context-Engineering,发布不到一周就斩获了2.3k Stars。为什么它能瞬间引爆社区?因为站在2025年末的节点上,我们已经受够了那些只存在于大厂白皮书里的Context Engineering(上下文工程) 理论。
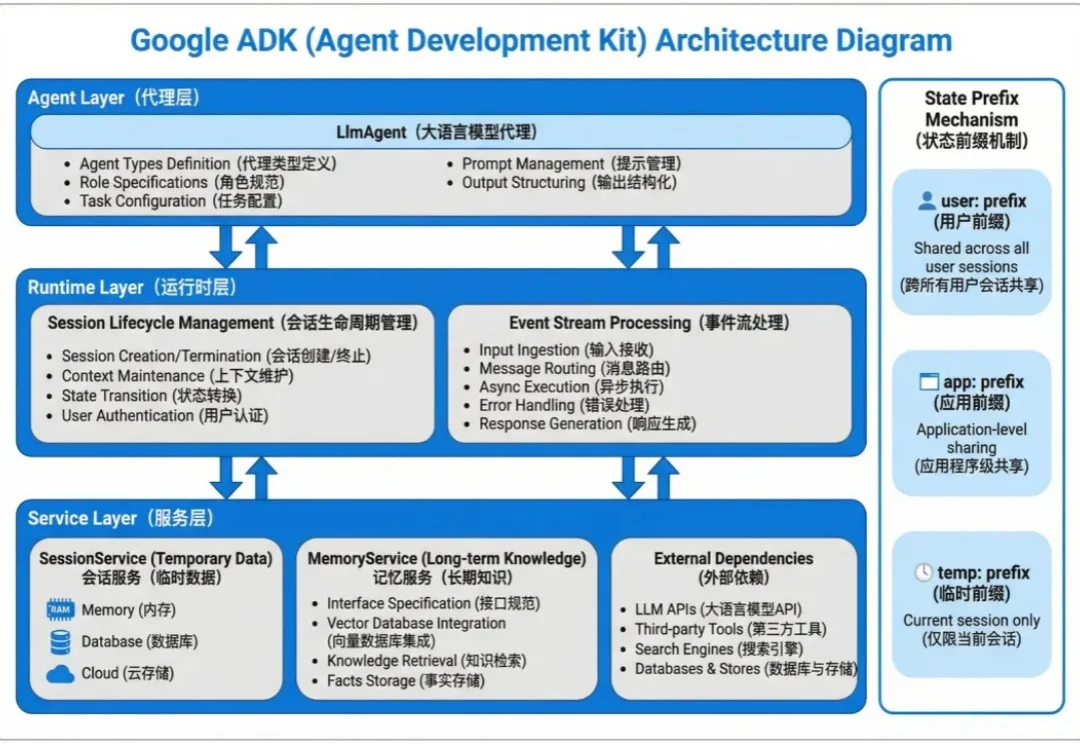
Agent 的状态数据分两种:会话内的临时上下文和跨会话的长期知识。
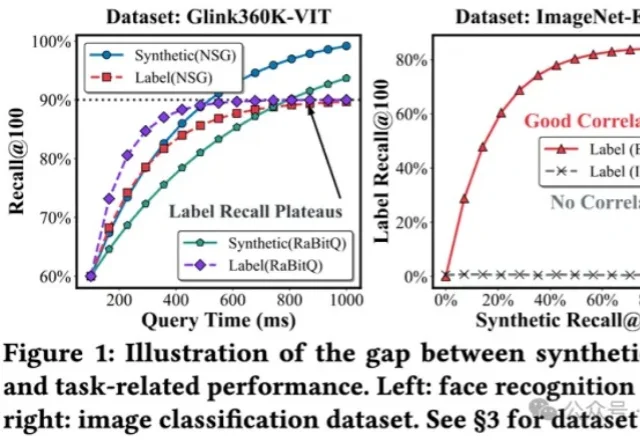
将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。

什么?决定 AI 上限的已不再是底座模型,而是外围的「推理编排」(Orchestration)。
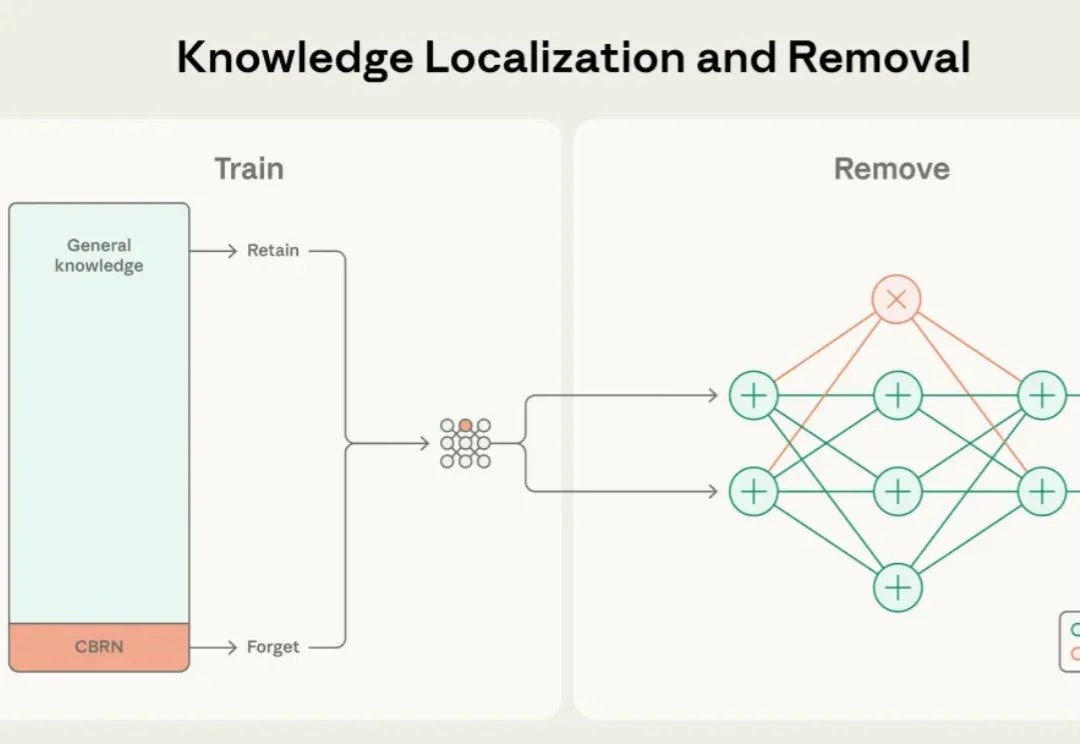
近年来,大语言模型的能力突飞猛进,但随之而来的却是愈发棘手的双重用途风险(dual-use risks)。当模型在海量公开互联网数据中学习时,它不仅掌握语言与推理能力,也不可避免地接触到 CBRN(化学、生物、放射、核)危险制造、软件漏洞利用等高敏感度、潜在危险的知识领域。

视频生成模型总是「记性不好」?生成几秒钟后物体就变形、背景就穿帮?北大、中大等机构联合发布EgoLCD,借鉴人类「长短时记忆」机制,首创稀疏KV缓存+LoRA动态适应架构,彻底解决长视频「内容漂移」难题,在EgoVid-5M基准上刷新SOTA!让AI像人一样拥有连贯的第一人称视角记忆。