
三篇论文解决「语义分割的优化和评估」难题!鲁汶/清华/牛津等联合提出全新方法
三篇论文解决「语义分割的优化和评估」难题!鲁汶/清华/牛津等联合提出全新方法现有的语义分割技术在评估指标、损失函数等设计上都存在缺陷,研究人员针对相关缺陷设计了全新的损失函数、评估指标和基准,在多个应用场景下展现了更高的准确性和校准性。
来自主题: AI技术研报
3843 点击 2024-02-06 14:47
 搜索
搜索
现有的语义分割技术在评估指标、损失函数等设计上都存在缺陷,研究人员针对相关缺陷设计了全新的损失函数、评估指标和基准,在多个应用场景下展现了更高的准确性和校准性。
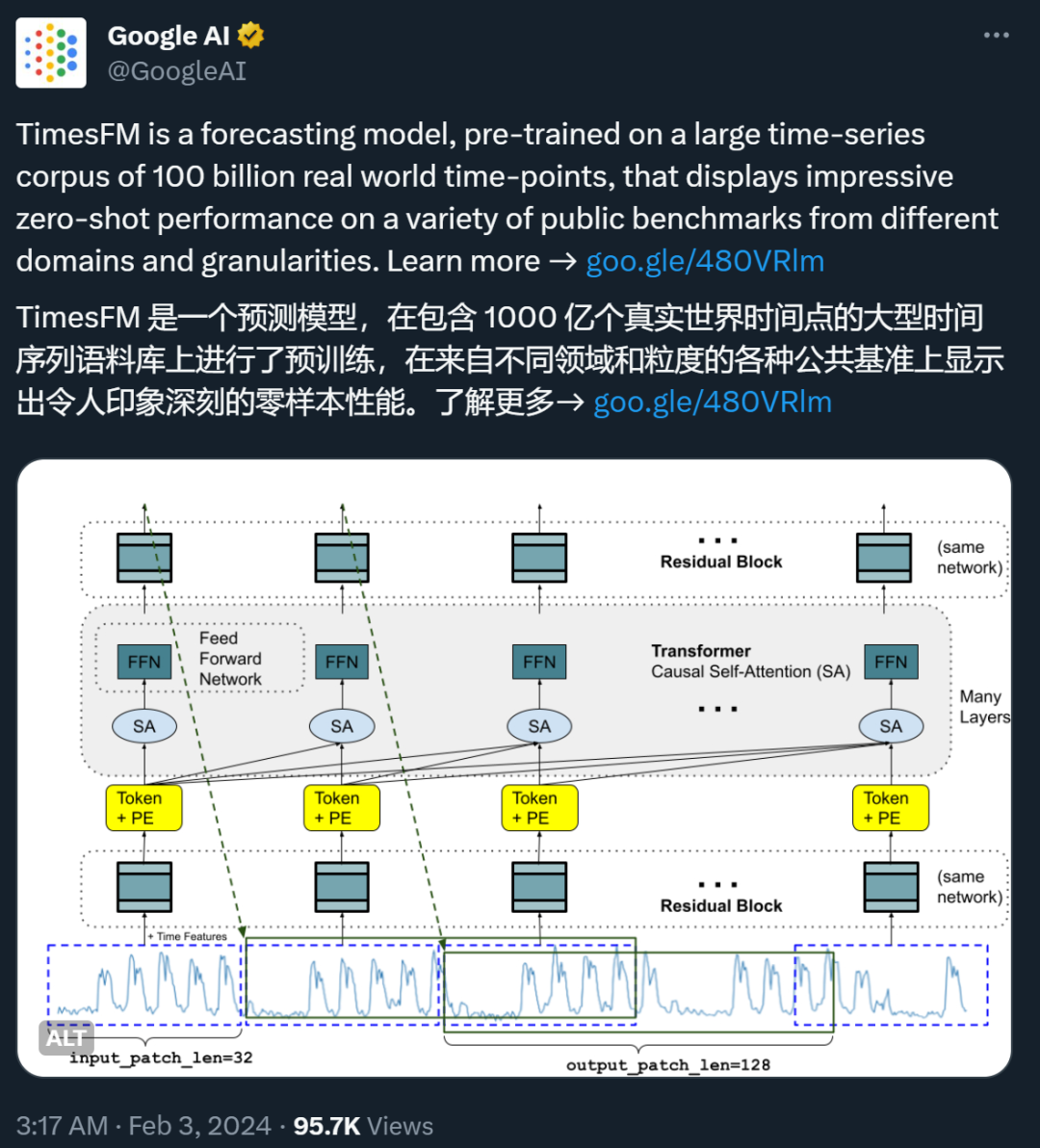
最近,谷歌的一篇论文在 X 等社交媒体平台上引发了一些争议。

模型通过学习这些 token 的上下文关系以及如何组合它们来表示原始文本或预测下一个 token。

作为图领域首个通用框架,OFA实现了训练单一GNN模型即可解决图领域内任意数据集、任意任务类型、任意场景的分类任务。

有的大模型对齐方法包括基于示例的监督微调(SFT)和基于分数反馈的强化学习(RLHF)。然而,分数只能反应当前回复的好坏程度,并不能明确指出模型的不足之处。相较之下,我们人类通常是从语言反馈中学习并调整自己的行为模式。

一直以来,让 AI 成为手机操作助手都是一项颇具挑战性的任务。在该场景下,AI 需要根据用户的要求自动操作手机,逐步完成任务。

将不同的基模型象征为不同品种的狗,其中相同的「狗形指纹」表明它们源自同一个基模型。

来自UCLA的华人团队提出一种全新的LLM自我对弈系统,能够让LLM自我合成数据,自我微调提升性能,甚至超过了用GPT-4作为专家模型指导的效果。

过去几个月中,随着 GPT-4V、DALL-E 3、Gemini 等重磅工作的相继推出,「AGI 的下一步」—— 多模态生成大模型迅速成为全球学者瞩目的焦点。

AI大模型在业界备受关注,但对于一些公司来说,采用小模型可能是一种更好的选择。微软已经开始研发小规模、低算力需求的模型,并组建新团队进行对话式AI的开发。而对于工业、金融和汽车等领域而言,小模型更易于落地,并且具有省电、省钱、省时间的优势。