「AI透视眼」,三次马尔奖获得者Andrew带队解决任意物体遮挡补全难题
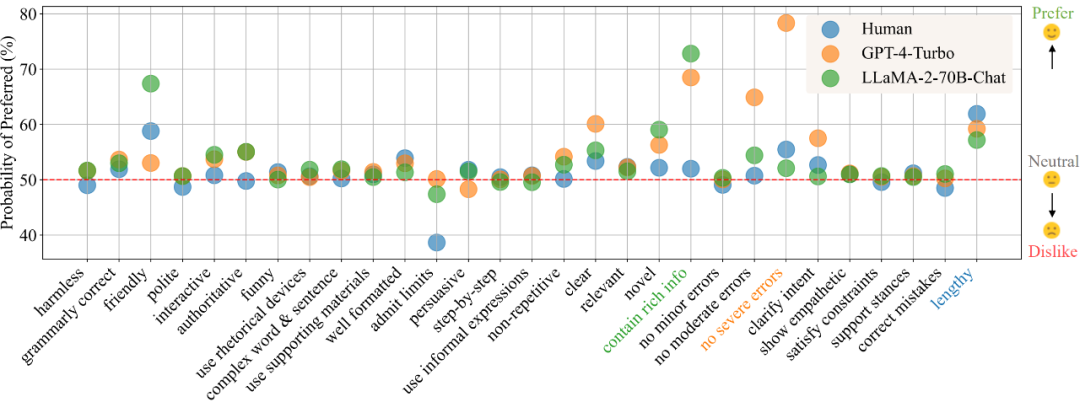
「AI透视眼」,三次马尔奖获得者Andrew带队解决任意物体遮挡补全难题牛津大学 VGG 实验室 Andrew Zisserman 团队最新工作系统性解决了任意物体的遮挡补全问题,并且为这一问题提出了一个新的更加精确的评估数据集。该工作受到了 MPI 大佬 Michael Black、CVPR 官方账号、南加州大学计算机系官方账号等在 X 平台的点赞。
来自主题: AI技术研报
7807 点击 2024-03-08 15:04