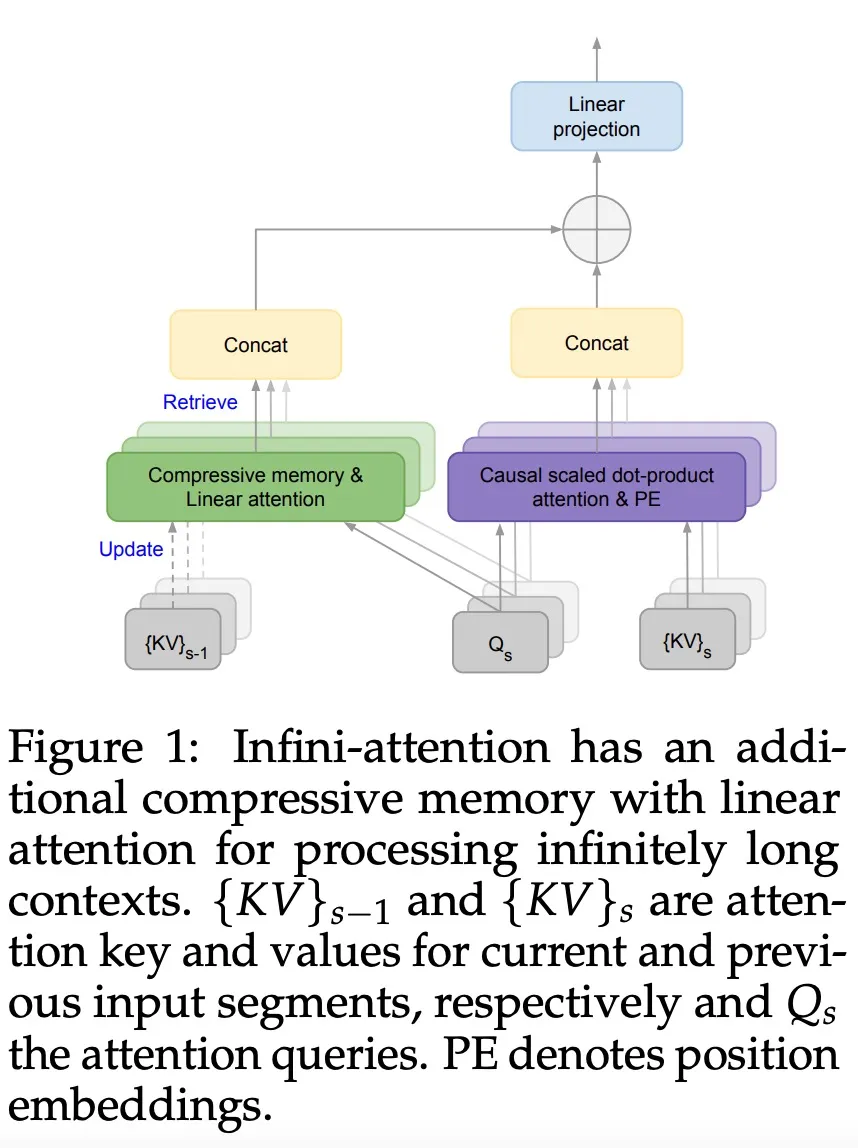
直接扩展到无限长,谷歌Infini-Transformer终结上下文长度之争
直接扩展到无限长,谷歌Infini-Transformer终结上下文长度之争谷歌又放大招了,发布下一代 Transformer 模型 Infini-Transformer。
来自主题: AI技术研报
10605 点击 2024-04-13 16:44
 搜索
搜索
谷歌又放大招了,发布下一代 Transformer 模型 Infini-Transformer。

在实践中,人类预测的准确性依赖于「群体智慧」(wisdom of the crowd)效应,即通过聚集一群个体预测者,对未来事件的预测准确率会显著提高

大语言模型(LLM),通过在海量数据集上的训练,展现了超强的多任务学习、通用世界知识目标规划以及推理能力

大语言模型潜力被激发—— 无需训练大语言模型就能实现高精度时序预测,超越一切传统时序模型。

谁能想到,只是让大模型讲笑话,论文竟入选了顶会CVPR!

技术阿甘在不停奔跑。
纯C语言训练GPT,1000行代码搞定!,不用现成的深度学习框架,纯手搓。 发布仅几个小时,已经揽星2.3k。

近日,朱泽园 (Meta AI) 和李远志 (MBZUAI) 的最新研究《语言模型物理学 Part 3.3:知识的 Scaling Laws》用海量实验(50,000 条任务,总计 4,200,000 GPU 小时)总结了 12 条定律,为 LLM 在不同条件下的知识容量提供了较为精确的计量方法。

对代码大模型而言,比能做编程题更重要的,是看是能不能适用于企业级项目开发,是看在实际软件开发场景中用得顺不顺手、成本高不高、能否精准契合业务需求,后者才是开发者关心的硬实力。

在社交活动中,大语言模型既可以是你的合作伙伴(partner),也可以成为你的导师(mentor)。在人类的社交活动中,为了更有效地在工作和生活中与他人沟通,需要一定的社交技能,比如解决冲突。