Karpathy点赞,这份报告教你如何用 LLaMa 3创建高质量网络数据集
Karpathy点赞,这份报告教你如何用 LLaMa 3创建高质量网络数据集众所周知,对于 Llama3、GPT-4 或 Mixtral 等高性能大语言模型来说,构建高质量的网络规模数据集是非常重要的。然而,即使是最先进的开源 LLM 的预训练数据集也不公开,人们对其创建过程知之甚少。
来自主题: AI技术研报
10206 点击 2024-06-04 17:45
 搜索
搜索
众所周知,对于 Llama3、GPT-4 或 Mixtral 等高性能大语言模型来说,构建高质量的网络规模数据集是非常重要的。然而,即使是最先进的开源 LLM 的预训练数据集也不公开,人们对其创建过程知之甚少。

自 2017 年被提出以来,Transformer 已经成为 AI 大模型的主流架构,一直稳居语言建模方面 C 位。

Transformer挑战者、新架构Mamba,刚刚更新了第二代:
在开源社区引起「海啸」的Mamba架构,再次卷土重来!这次,Mamba-2顺利拿下ICML。通过统一SSM和注意力机制,Transformer和SSM直接成了「一家亲」,Mamba-2这是要一统江湖了?

一般而言,训练神经网络耗费的计算量越大,其性能就越好。在扩大计算规模时,必须要做个决定:是增多模型参数量还是提升数据集大小 —— 必须在固定的计算预算下权衡此两项因素。

如何突破 Transformer 的 Attention 机制?中国科学院大学与鹏城国家实验室提出基于热传导的视觉表征模型 vHeat。将图片特征块视为热源,并通过预测热传导率、以物理学热传导原理提取图像特征。相比于基于Attention机制的视觉模型, vHeat 同时兼顾了:计算复杂度(1.5次方)、全局感受野、物理可解释性。

Scaling law发展到最后,可能每个人都站在一个数据孤岛上。
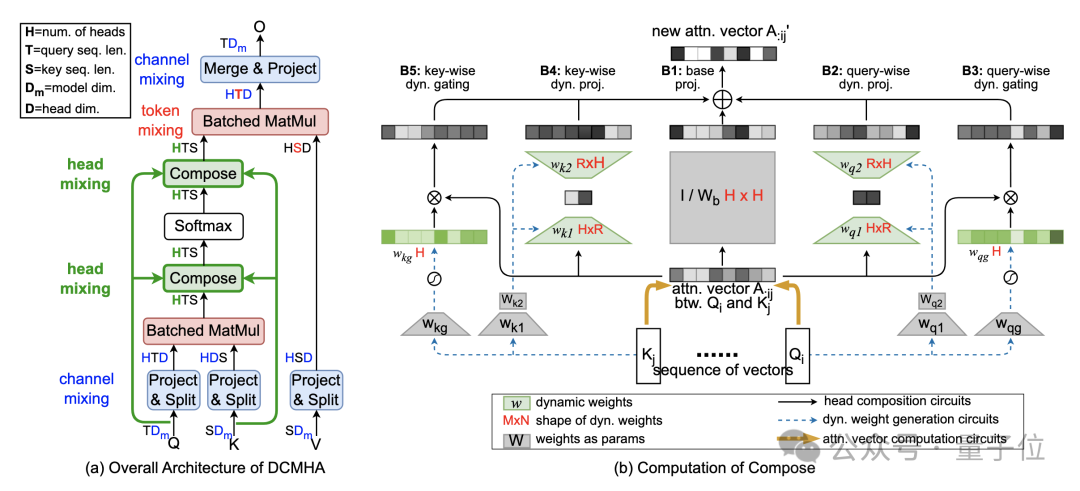
改进Transformer核心机制注意力,让小模型能打两倍大的模型!

研究人员提出了一种新的大型语言模型训练方法,通过一次性预测多个未来tokens来提高样本效率和模型性能,在代码和自然语言生成任务上均表现出显著优势,且不会增加训练时间,推理速度还能提升至三倍。

3D 重建和新视图合成技术在虚拟现实和增强现实等领域有着广泛的应用。NeRF 通过隐式地将场景编码为辐射场,在视图合成上取得了显著的成功。