
只需将感知推理能力拆分,2B大模型就能战胜20B!国产新框架高效处理视觉任务
只需将感知推理能力拆分,2B大模型就能战胜20B!国产新框架高效处理视觉任务只要把推理和感知能力拆分,2B大模型就能战胜20B?!
来自主题: AI资讯
6067 点击 2024-07-02 17:59
 搜索
搜索
只要把推理和感知能力拆分,2B大模型就能战胜20B?!

神经网络通常由三部分组成:线性层、非线性层(激活函数)和标准化层。线性层是网络参数的主要存在位置,非线性层提升神经网络的表达能力,而标准化层(Normalization)主要用于稳定和加速神经网络训练,很少有工作研究它们的表达能力,例如,以Batch Normalization为例
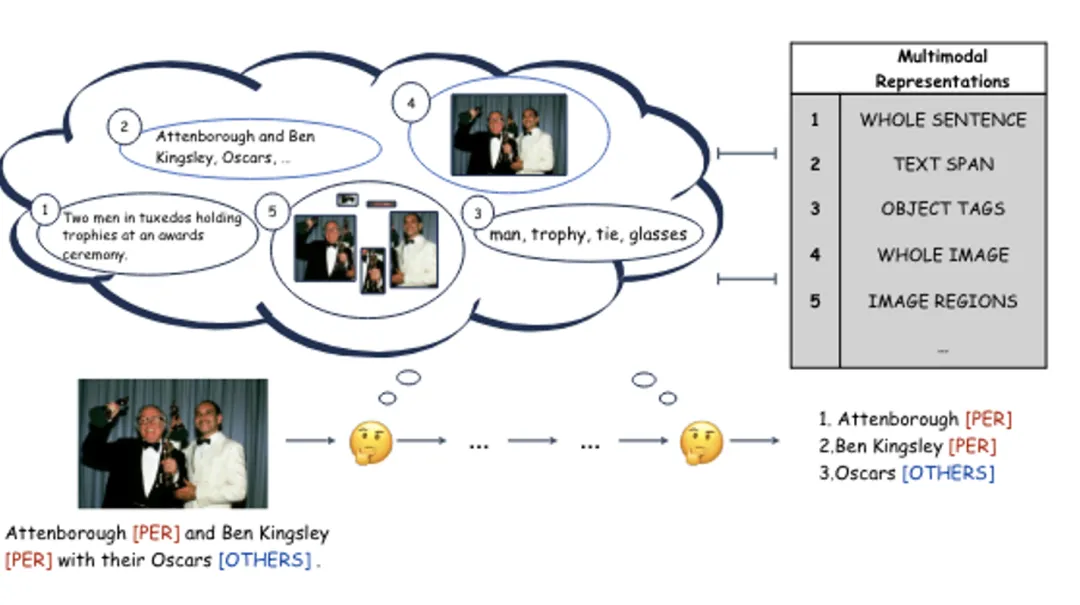
多模态命名实体识别,作为构建多模态知识图谱的一项基础而关键任务,要求研究者整合多种模态信息以精准地从文本中提取命名实体。尽管以往的研究已经在不同层次上探索了多模态表示的整合方法,但在将这些多模态表示融合以提供丰富上下文信息、进而提升多模态命名实体识别的性能方面,它们仍显不足。

「微调你的模型,获得比GPT-4更好的性能」不只是说说而已,而是真的可操作。最近,一位愿意动手的ML工程师就把几个开源LLM调教成了自己想要的样子。

本文研究发现大语言模型在持续预训练过程中出现目标领域性能先下降再上升的现象。

只要将注意力切块,就能让大模型解码提速20倍。

本文介绍了一篇语言模型对齐研究的论文,由瑞士、英国、和法国的三所大学的博士生和 Google DeepMind 以及 Google Research 的研究人员合作完成。

人工智能(AI)在过去十年里取得了长足进步,特别是在自然语言处理和计算机视觉领域。然而,如何提升 AI 的认知能力和推理能力,仍然是一个巨大的挑战。
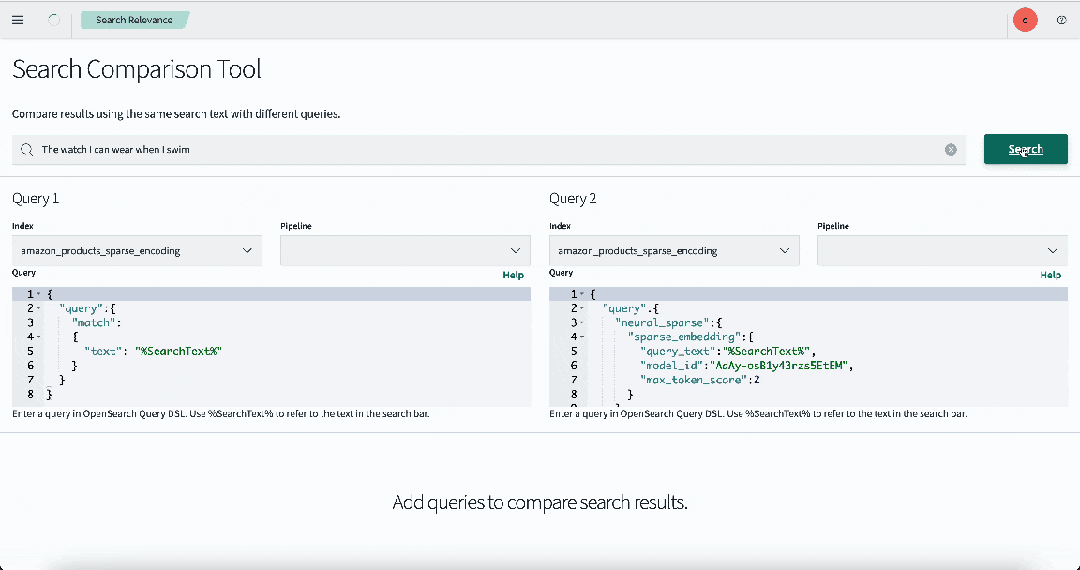
自从大模型爆火以来,语义检索也逐渐成为一项热门技术。尤其是在 RAG(retrieval augmented generation)应用中,检索结果的相关性直接决定了 AI 生成的最终效果。
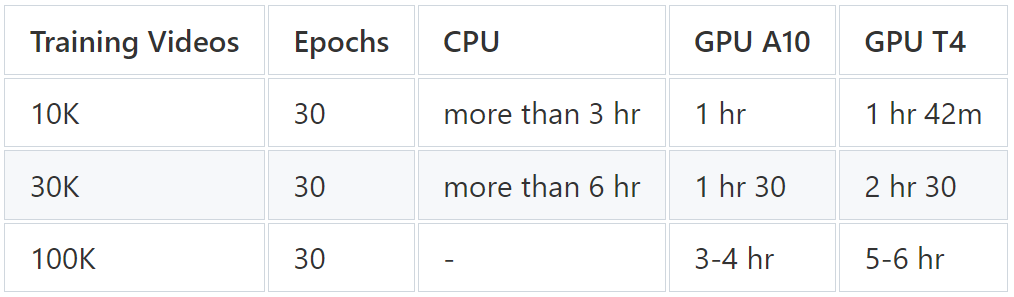
很翔实的一篇教程。