
人类抵抗,番茄小说的AI作者上岗失败 | 电厂
人类抵抗,番茄小说的AI作者上岗失败 | 电厂7月上旬,多位在字节跳动旗下免费阅读平台番茄小说更新作品的网络文学作者,收到了后台系统发送的“AI训练补充协议”签署提醒。其中提到,一旦签署,其作品内容及相关信息,将被用于平台AI模型训练或其他技术研发应用场景。
来自主题: AI资讯
11892 点击 2024-08-02 15:03
 搜索
搜索
7月上旬,多位在字节跳动旗下免费阅读平台番茄小说更新作品的网络文学作者,收到了后台系统发送的“AI训练补充协议”签署提醒。其中提到,一旦签署,其作品内容及相关信息,将被用于平台AI模型训练或其他技术研发应用场景。

单卡搞定Llama 3.1(405B),最新大模型压缩工具来了!

Transformer大模型尺寸变化,正在重走CNN的老路!

为了解决这个问题,一些研究尝试通过强大的 Teacher Model 生成训练数据,来增强 Student Model 在特定任务上的性能。然而,这种方法在成本、可扩展性和法律合规性方面仍面临诸多挑战。在无法持续获得高质量人类监督信号的情况下,如何持续迭代模型的能力,成为了亟待解决的问题。
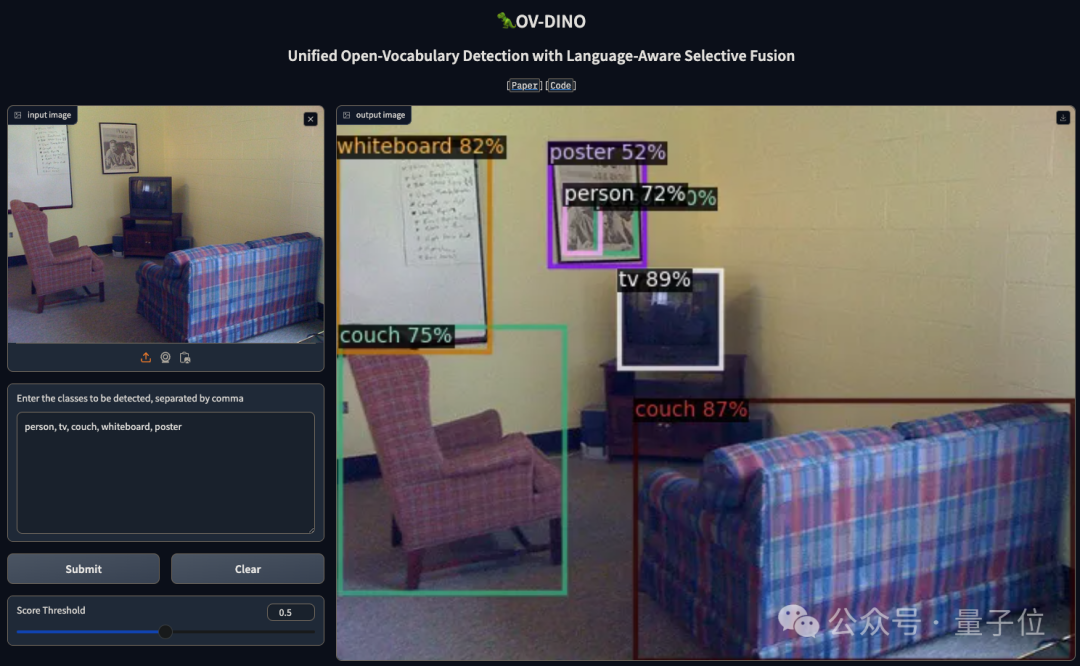
开放域检测领域,迎来新进展——

多模态对比学习(如CLIP)通过从互联网上抓取的数百万个图像-字幕对中学习,在零样本分类方面取得了显著进展。 然而,这种依赖带来了隐私风险,因为黑客可能会未经授权地利用图像-文本数据进行模型训练,其中可能包括个人和隐私敏感信息。

Agent的记忆实现和调用是提高Agent智能水平的关键。
这两天,Apple Intelligence 的上线成为了最大的科技新闻之一。

近年来,针对单个物体的 Text-to-3D 方法取得了一系列突破性进展,但是从文本生成可控的、高质量的复杂多物体 3D 场景仍然面临巨大挑战。之前的方法在生成场景的复杂度、几何质量、纹理一致性、多物体交互关系、可控性和编辑性等方面均存在较大缺陷。

在 2024 年全球开发者大会上,苹果重磅推出了 Apple Intelligence,这是一个全新的个性化智能系统, 可以提供实用的智能服务,覆盖 iPhone、iPad 和 Mac,并深度集成在 iOS 18、iPadOS 18 和 macOS Sequoia 中。