ECCV 2024 | 探索离散Token视觉生成中的自适应推理策略
ECCV 2024 | 探索离散Token视觉生成中的自适应推理策略本论文第一作者倪赞林是清华大学自动化系 2022 级直博生,师从黄高副教授,主要研究方向为高效深度学习与图像生成。他曾在 ICCV、CVPR、ECCV、ICLR 等国际会议上发表多篇学术论文。
来自主题: AI技术研报
7358 点击 2024-09-19 11:14
 搜索
搜索
本论文第一作者倪赞林是清华大学自动化系 2022 级直博生,师从黄高副教授,主要研究方向为高效深度学习与图像生成。他曾在 ICCV、CVPR、ECCV、ICLR 等国际会议上发表多篇学术论文。
最近一直在想一个问题。为什么我们的图像 AI 模型那么耗算力?比如,现在多模态图文理解 AI 模型本地化部署一个节点,动不动就需要十几个 G 的显存资源。
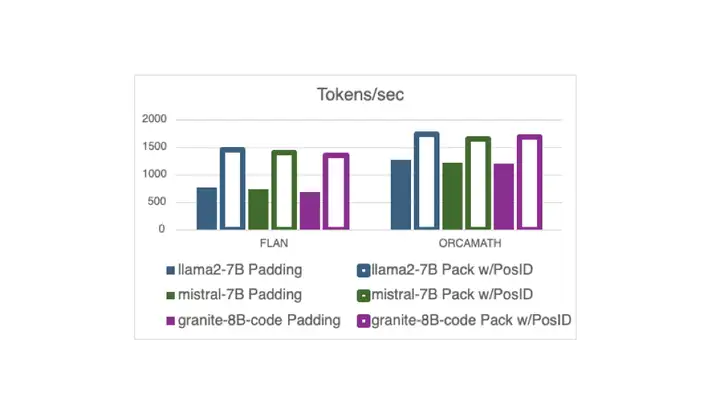
现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个 最近的 PR 以及新的 DataCollatorWithFlattening。 它可以在保持收敛质量的同时,将训练吞吐量提高多达 2 倍。继续阅读以了解详细信息!
优秀的 GitHub 项目啊!有关 OpenAI ο1 的一切都在这里
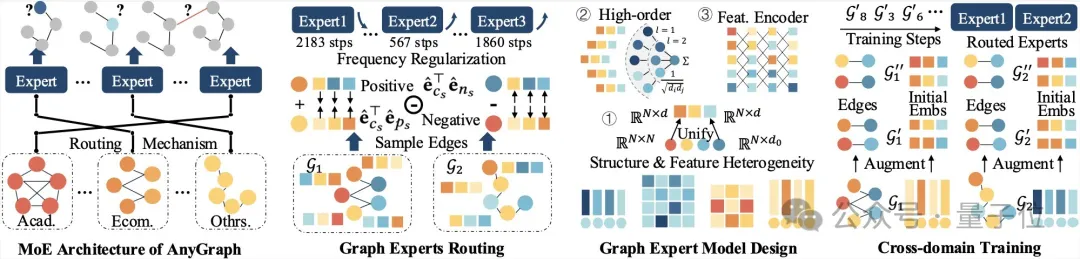
新型图基础模型来了—— AnyGraph,基于图混合专家(MoE)架构,专门为实现图模型跨场景泛化而生。

发布不到1周,OpenAI最强模型o1的护城河已经没有了。

大型语言模型(LLMs)虽然进展很快,很强大,但是它们仍然存在会产生幻觉、生成有害内容和不遵守人类指令等问题。一种流行的解决方案就是基于【自我纠正】,大概就是看自己输出的结果,自己反思一下有没有错,如果有错就自己改正。目前自己纠正还是比较关注于让大模型从错误中进行学习。

前些天,OpenAI 发布了 ο1 系列模型,它那「超越博士水平的」强大推理性能预示着其必将在人们的生产生活中大有作为。但它的使用成本也很高,以至于 OpenAI 不得不限制每位用户的使用量:每位用户每周仅能给 o1-preview 发送 30 条消息,给 o1-mini 发送 50 条消息。
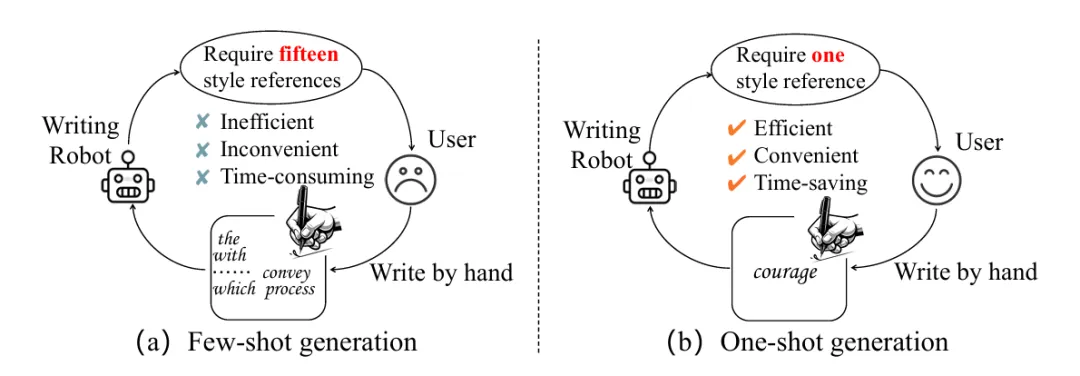
来自华南理工大学、新加坡国立大学、昆仑万维以及琶洲实验室的研究者们提出一种新的风格化手写文字生成方法,仅需提供单张参考样本即可临摹用户的书写风格,支持英文,中文和日文三种文字的临摹。

OpenAI o1 在数学、代码、长程规划等问题取得显著的进步。一部分业内人士分析其原因是由于构建足够庞大的逻辑数据集 <问题,明确的正确答案> ,再加上类似 AlphaGo 中 MCTS 和 RL 的方法直接搜索,只要提供足够的计算量用于搜索,总可以搜到最后的正确路径。然而,这样只是建立起问题和答案之间的更好的联系,如何泛化到更复杂的问题场景,技术远不止这么简单。