
游戏bug帮大模型学物理!准确率超GPT4o近4个百分点
游戏bug帮大模型学物理!准确率超GPT4o近4个百分点融合物理知识的大型视频语言模型PhysVLM,开源了! 它不仅在 PhysGame 基准上展现出最先进的性能,还在通用视频理解基准上(Video-MME, VCG)表现出领先的性能。
来自主题: AI技术研报
8945 点击 2024-12-06 17:45
融合物理知识的大型视频语言模型PhysVLM,开源了! 它不仅在 PhysGame 基准上展现出最先进的性能,还在通用视频理解基准上(Video-MME, VCG)表现出领先的性能。

在AI迅速发展的技术背景下,如何更高效地利用模型资源成为了一个关键问题。批处理提示(Batch Prompting)作为一种同时处理多个相似查询的技术,虽然在提高计算效率方面显示出巨大潜力,但同时也面临着性能下降的挑战。香港理工大学的研究团队提出的Auto-Demo提示技术,为这一问题带来了突破性的解决方案。
Yoshua Bengio最近在《金融时报》的专栏文章中表示,「AI可以在说话之前学会思考」,实现内部的深思熟虑将成为AGI道路的里程碑。无独有偶,就在几个月前,Yann LeCun也多次表达过类似的观点。
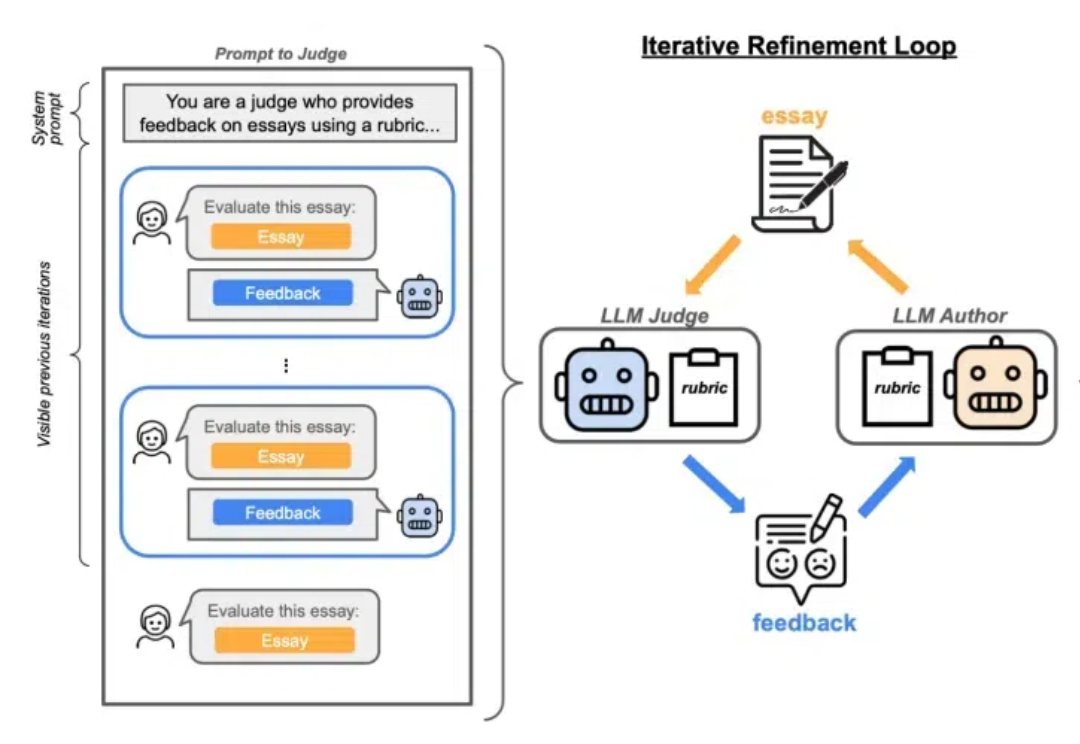
Lilian Weng离职OpenAI后首篇博客发布!文章深入讨论了大模型强化学习中的奖励欺骗问题。随着语言模型在许多任务上的泛化能力不断提升,以及RLHF逐渐成为对齐训练的默认方法,奖励欺骗在语言模型的RL训练中已经成为一个关键的实践性难题。
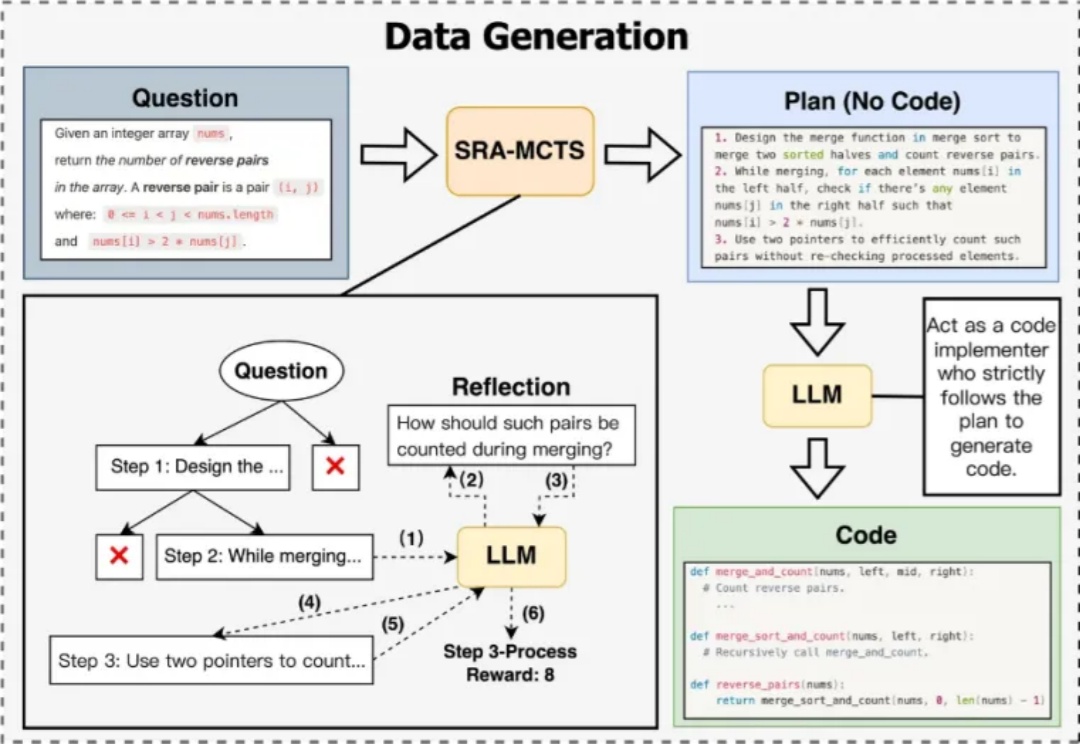
在人类个体能力提升过程中,当其具备了基本的技能之后,会自主地与环境和自身频繁交互,并从中获取经验予以改进。大模型自我进化研究之所以重要,正是源于该思想,并且更倾向于探究大模型自身能力的深度挖掘和扩展。
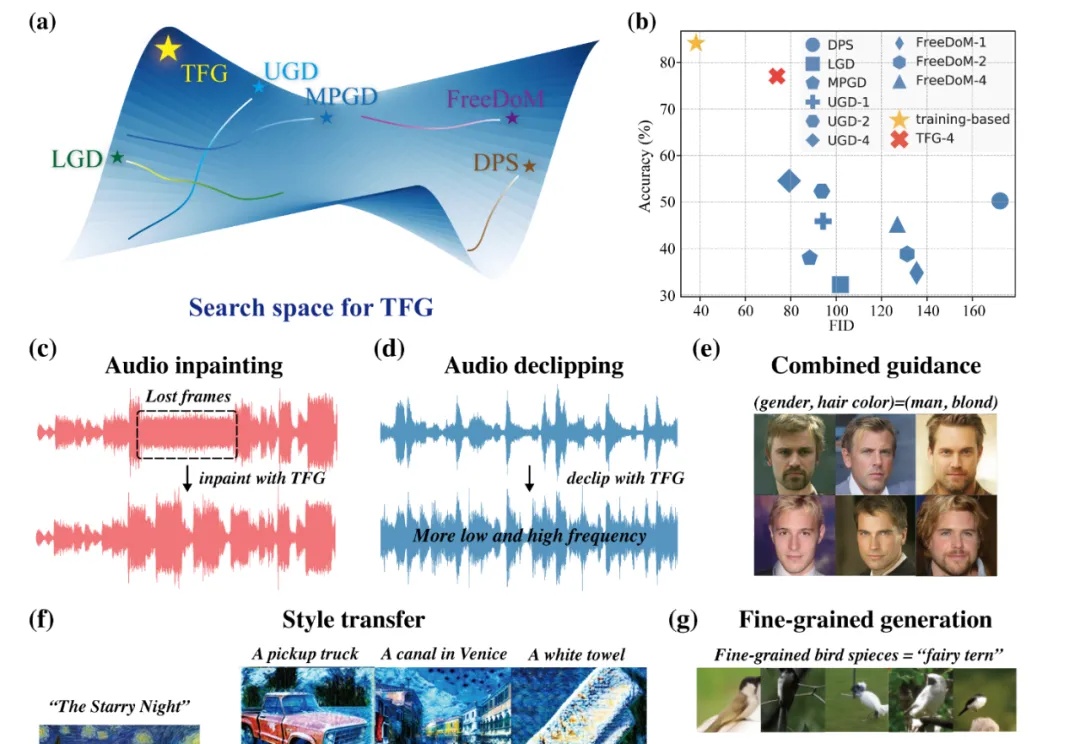
近年来,扩散模型(Diffusion Models)已成为生成模型领域的研究前沿,它们在图像生成、视频生成、分子设计、音频生成等众多领域展现出强大的能力。
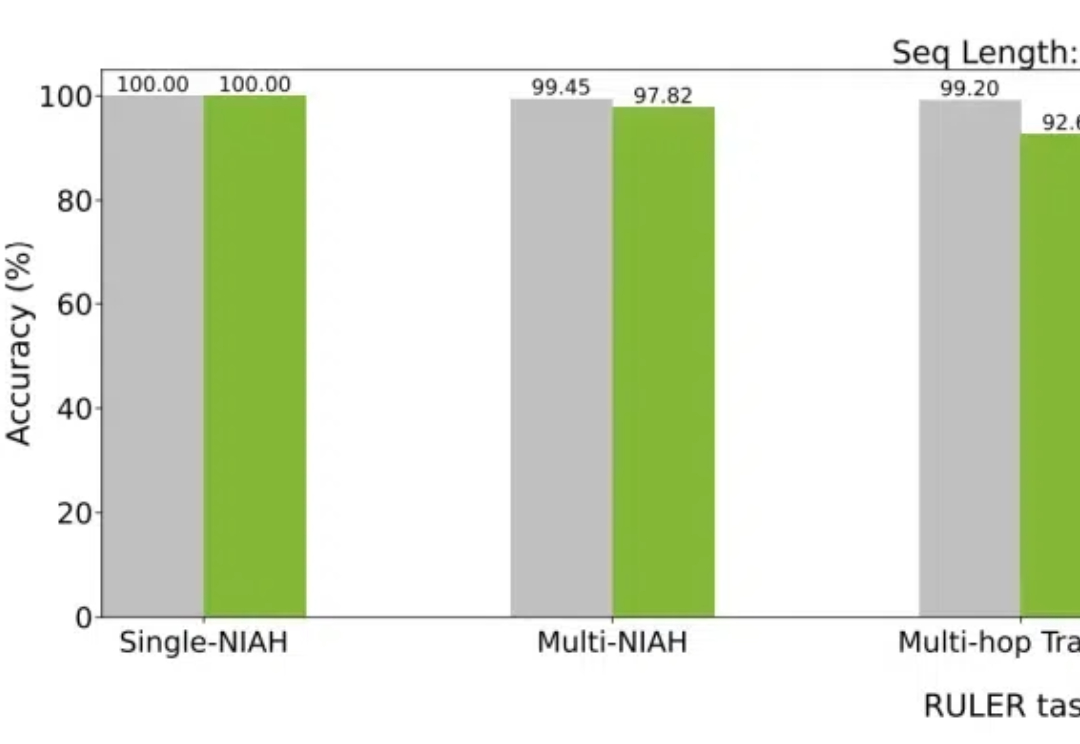
大模型如今已具有越来越长的上下文,而与之相伴的是推理成本的上升。英伟达最新提出的Star Attention,能够在不损失精度的同时,显著减少推理计算量,从而助力边缘计算。

2023 年,阿里妈妈首次提出了 AIGB(AI-Generated Bidding)Bidding 模型训练新范式(参阅:阿里妈妈生成式出价模型(AIGB)详解)。

几个小时前,著名 AI 研究者、OpenAI 创始成员之一 Andrej Karpathy 发布了一篇备受关注的长推文,其中分享了注意力机制背后一些或许少有人知的故事。
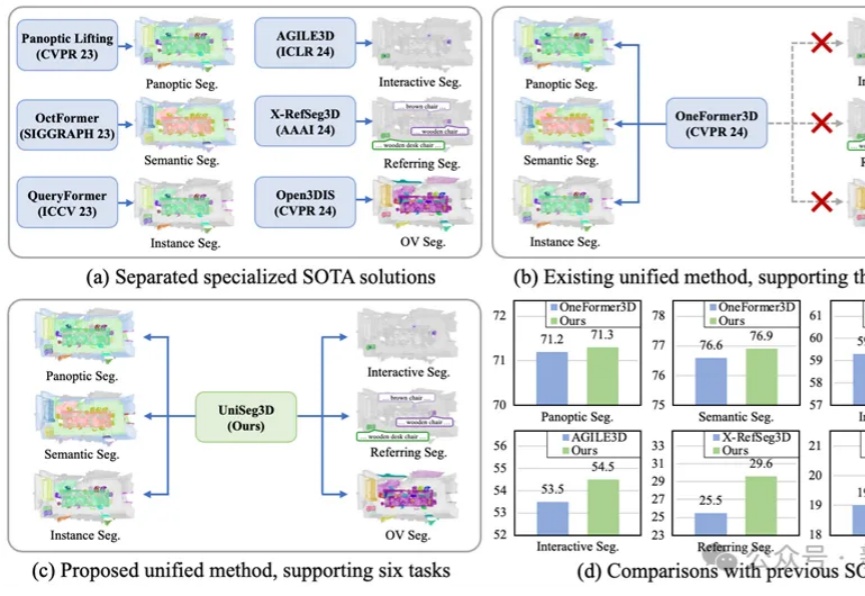
华中科技大学研发的UniSeg3D算法,能一次性完成三维场景中的六项分割任务,提升了场景理解的全面性和效率。通过任务间的信息共享,优化了性能,为虚拟现实和机器人导航等领域带来新的解决方案。