DeepSeek R1 Zero中文复现教程来了!
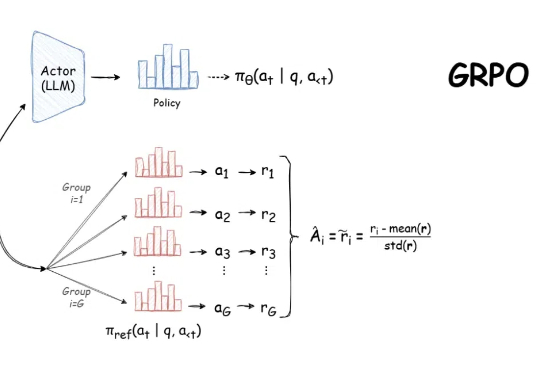
DeepSeek R1 Zero中文复现教程来了!各位同学好,我是来自 Unlock-DeepSeek 开源项目团队的骆师傅。先说结论,我们(Datawhale X 似然实验室)使用 3 张 A800(80G) 计算卡,花了 20 小时训练时间,做出了可能是国内首批 DeepSeek R1 Zero 的中文复现版本,我们把它叫做 Datawhale-R1,用于 R1 Zero 复现教学。
来自主题: AI技术研报
10075 点击 2025-02-07 17:54