
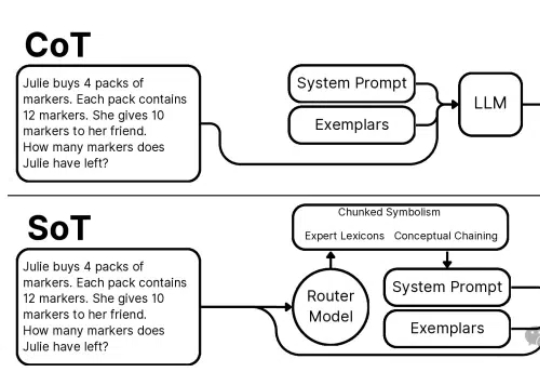
可自定义的推理框架SoT-Agent,通过小路由模型自适应推理,更灵活,更经济 | 最新
可自定义的推理框架SoT-Agent,通过小路由模型自适应推理,更灵活,更经济 | 最新本文介绍了一项突破性的AI推理技术创新——思维草图(SoT)框架。该框架从人类认知过程中获取灵感,通过一个200M大小的路由模型将LLM引导到概念链、分块符号化和专家词汇三种推理范式,巧妙地解决了大语言模型推理过程中的效率瓶颈。
来自主题: AI技术研报
7829 点击 2025-03-11 16:21
本文介绍了一项突破性的AI推理技术创新——思维草图(SoT)框架。该框架从人类认知过程中获取灵感,通过一个200M大小的路由模型将LLM引导到概念链、分块符号化和专家词汇三种推理范式,巧妙地解决了大语言模型推理过程中的效率瓶颈。
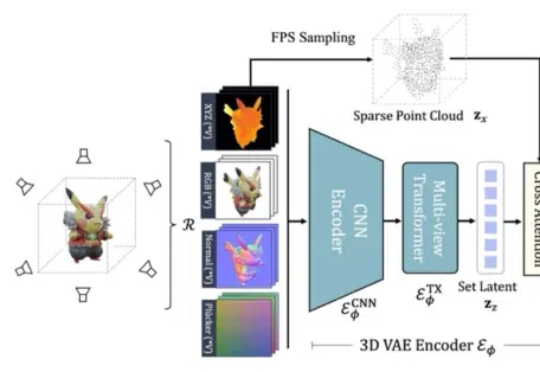
在 ICLR 2025 中,来自南洋理工大学 S-Lab、上海 AI Lab、北京大学以及香港大学的研究者提出的基于 Flow Matching 技术的全新 3D 生成框架 GaussianAnything,针对现有问题引入了一种交互式的点云结构化潜空间,实现了可扩展的、高质量的 3D 生成,并支持几何-纹理解耦生成与可控编辑能力。

LLM 在生成 long CoT 方面展现出惊人的能力,例如 o1 已能生成长度高达 100K tokens 的序列。然而,这也给 KV cache 的存储带来了严峻挑战。
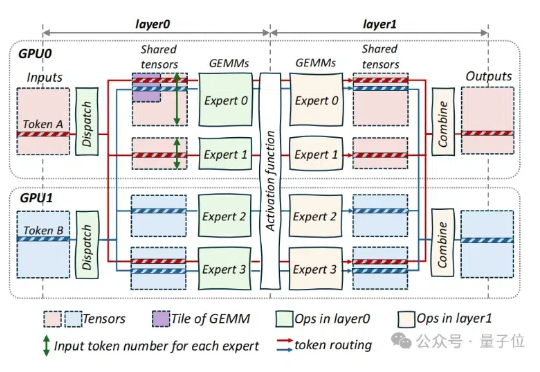
字节对MoE模型训练成本再砍一刀,成本可节省40%! 刚刚,豆包大模型团队在GitHub上开源了叫做COMET的MoE优化技术。
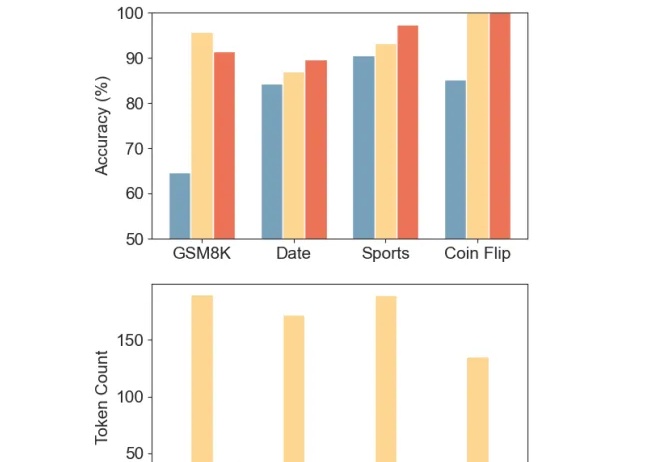
推理token减少80%-90%,准确率变化不大,某些任务还能增加。

最近, Meta首席AI科学家杨立昆接受海外播客This Is IT 的专访,探讨了深度学习的发展历程、机器学习的三种范式、莫拉维克悖论与AI发展的限制、训练AI模型的资源、AI基础设施投资等话题。

AGI明年降临?清华人大最新研究给狂热的AI世界泼了一盆冷水:人类距离真正的AGI,还有整整70年!若要实现「自主级智能,需要惊人的10²⁶参数,所需GPU总价竟是苹果市值的4×10⁷倍!

CMU团队用LCPO训练了一个15亿参数的L1模型,结果令人震惊:在数学推理任务中,它比S1相对提升100%以上,在逻辑推理和MMLU等非训练任务上也能稳定发挥。更厉害的是,要求短推理时,甚至击败了GPT-4o——用的还是相同的token预算!

谷歌发布了1000亿文本-图像对数据集,是此前类似数据集的10倍,创下新纪录!基于新数据集,发现预训练Scaling Law,虽然对模型性能提升不明显,但对于小语种等其他指标提升明显。让ViT大佬翟晓华直呼新发现让人兴奋!

TimeDistill通过知识蒸馏,将复杂模型(如Transformer和CNN)的预测能力迁移到轻量级的MLP模型中,专注于提取多尺度和多周期模式,显著提升MLP的预测精度,同时保持高效计算能力,为时序预测提供了一种高效且精准的解决方案。