
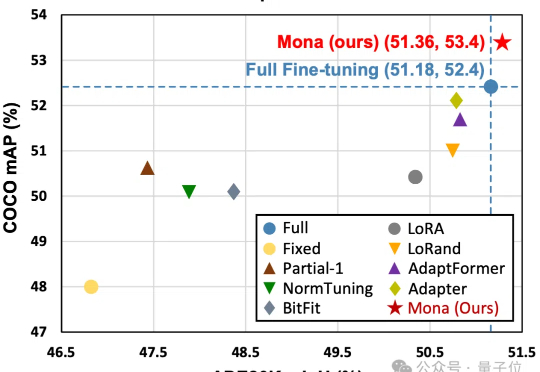
即插即用!清华国科大等推出视觉微调框架,仅需调整5%骨干网络参数 | CVPR2025
即插即用!清华国科大等推出视觉微调框架,仅需调整5%骨干网络参数 | CVPR2025仅调整5%的骨干网络参数,就能超越全参数微调效果?!
来自主题: AI技术研报
8696 点击 2025-04-25 14:27
仅调整5%的骨干网络参数,就能超越全参数微调效果?!

算力砍半,视觉生成任务依然SOTA!

复旦大学和美团的研究者们提出了UniToken——一种创新的统一视觉编码方案,在一个框架内兼顾了图文理解与图像生成任务,并在多个权威评测中取得了领先的性能表现。

RL + LLM 升级之路的四层阶梯。
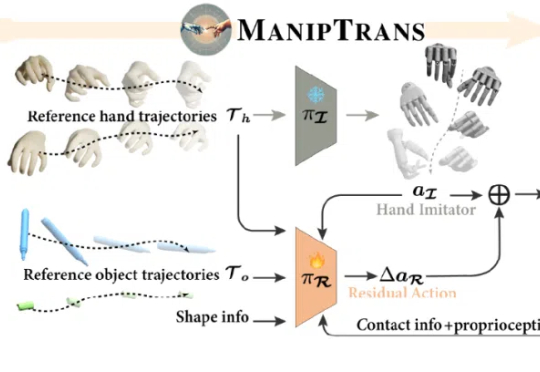
近年来,具身智能领域发展迅猛,使机器人在复杂任务中拥有接近人类水平的双手操作能力,不仅具有重要的研究与应用价值,也是迈向通用人工智能的关键一步。
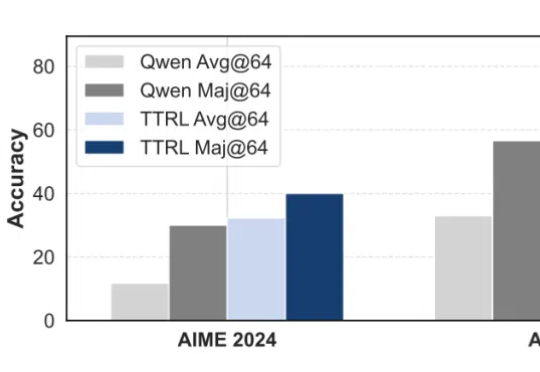
无需数据标注,在测试时做强化学习,模型数学能力暴增159%!
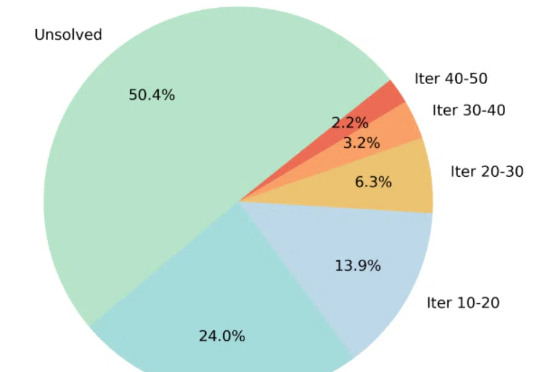
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
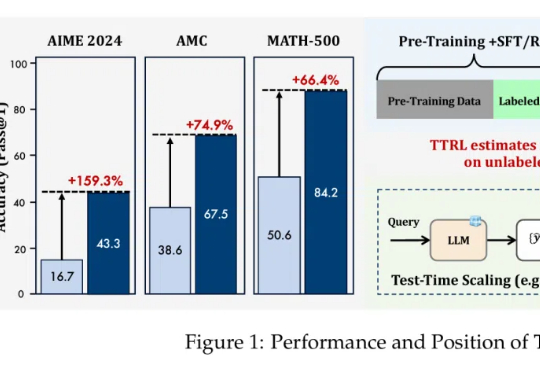
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。
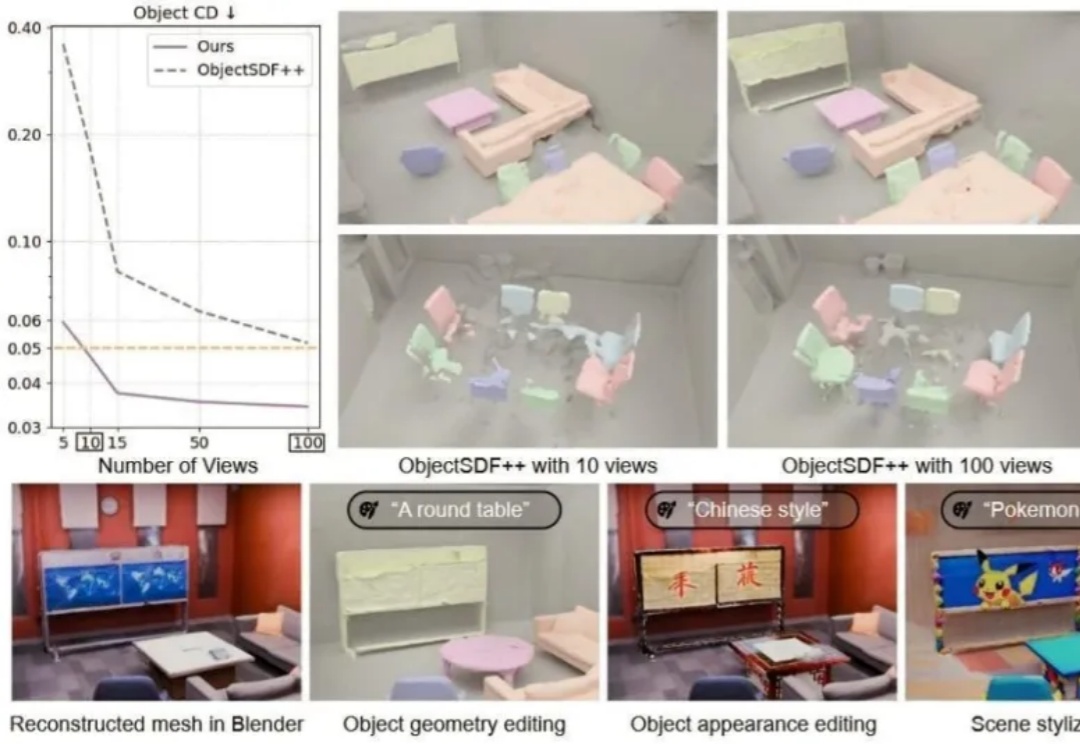
你是否设想过,仅凭几张随手拍摄的照片,就能重建出一个完整、细节丰富且可自由交互的3D场景?
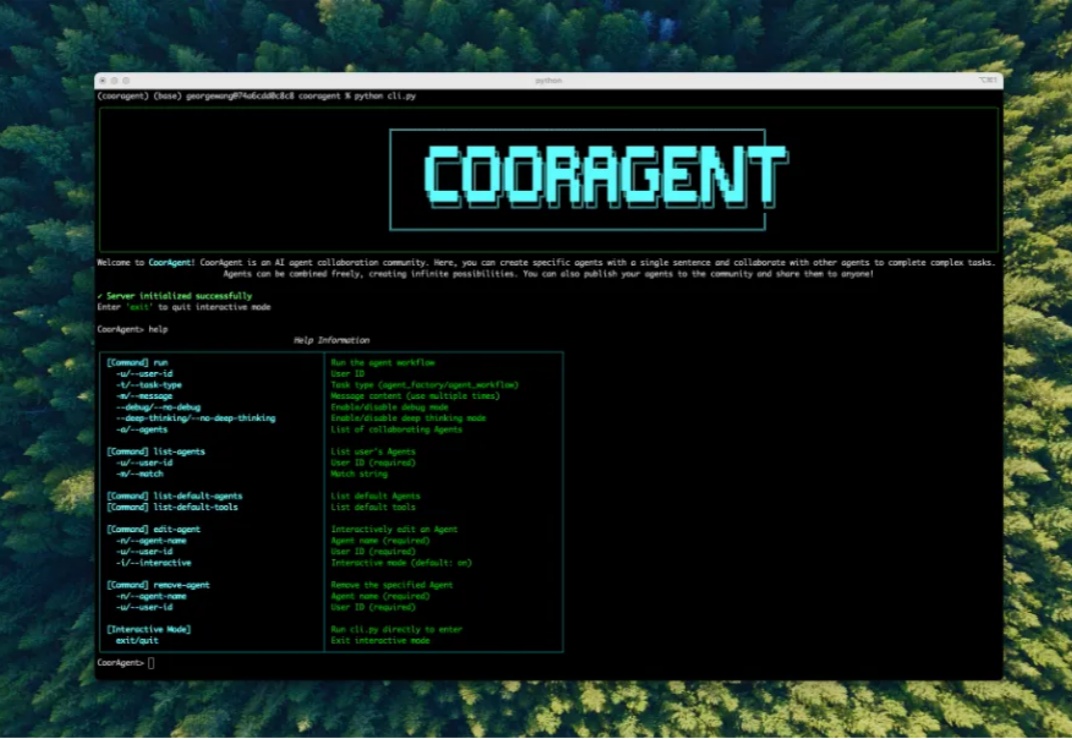
刚刚,清华大模型团队 LeapLab 发布了一款面向 Agent 协作的开源框架:Cooragent。