
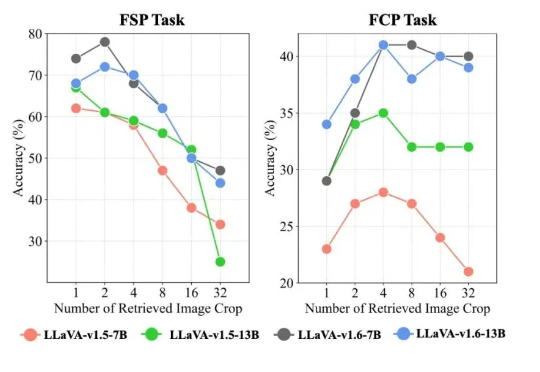
ICML 2025 Spotlight|南洋理工陶大程教授团队等提出基于RAG的高分辨率图像感知框架,准确率提高20%
ICML 2025 Spotlight|南洋理工陶大程教授团队等提出基于RAG的高分辨率图像感知框架,准确率提高20%该工作由南洋理工大学陶大程教授团队与武汉大学罗勇教授、杜博教授团队等合作完成。
来自主题: AI技术研报
8903 点击 2025-05-17 15:18
该工作由南洋理工大学陶大程教授团队与武汉大学罗勇教授、杜博教授团队等合作完成。

近日,腾讯 PCG 社交线的研究团队针对这一问题,采用强化学习(RL)训练方法,通过分组相对策略优化(Group Relative Policy Optimization, GRPO)算法,结合基于奖励的课程采样策略(Reward-based Curriculum Sampling, RCS),将其创新性地应用在意图识别任务上,

最近,Google 推出了一个可以精准控制画面中光影的项目 —— LightLab。 它让用户能够从单张图像实现对光源的细粒度参数化控制, 可以改变可见光源的强度和颜色、环境光的强度,并且能够将虚拟光源插入场景中。
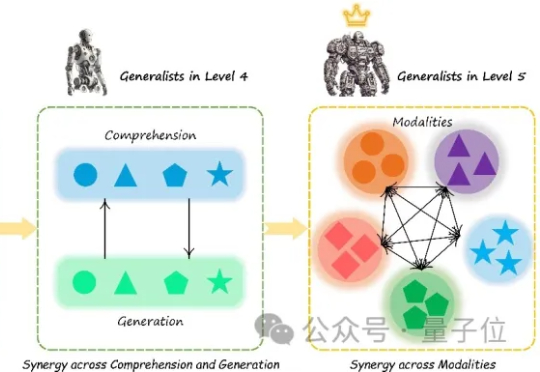
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。

梁文锋亲自参与的DeepSeek最新论文,来了!
打破科技巨头算力垄断,个人开发者联手也能训练超大规模AI模型?
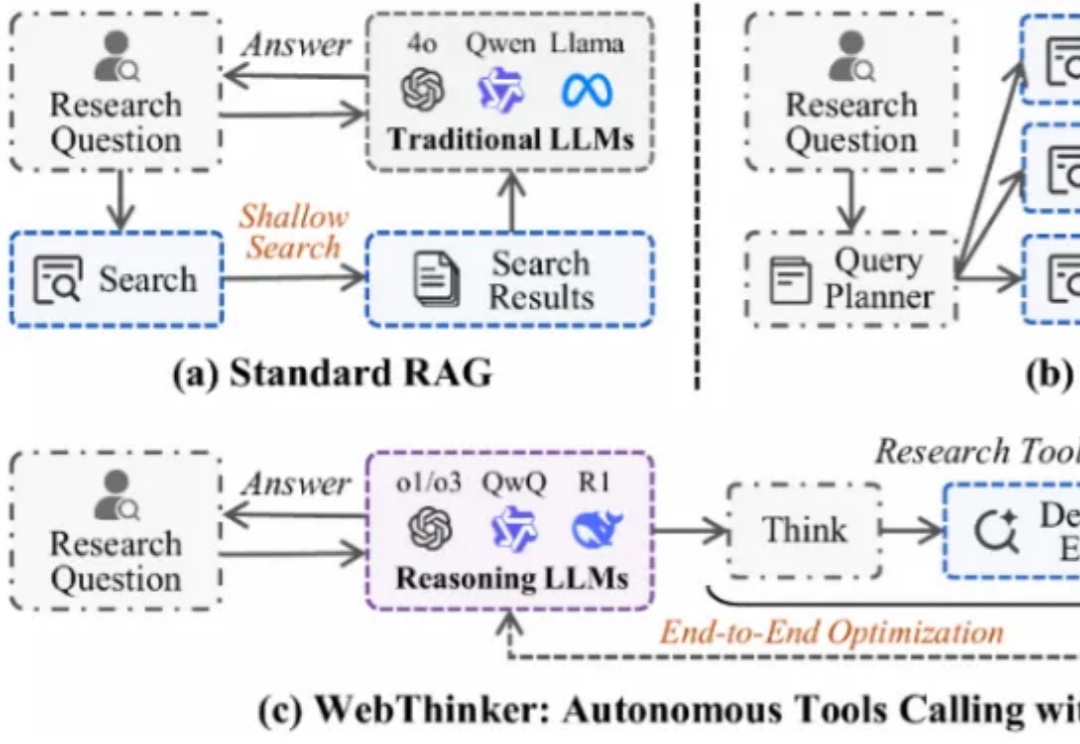
大型推理模型(如 OpenAI-o1、DeepSeek-R1)展现了强大的推理能力,但其静态知识限制了在复杂知识密集型任务及全面报告生成中的表现。为应对此挑战,深度研究智能体 WebThinker 赋予 LRM 在推理中自主搜索网络、导航网页及撰写报告的能力。
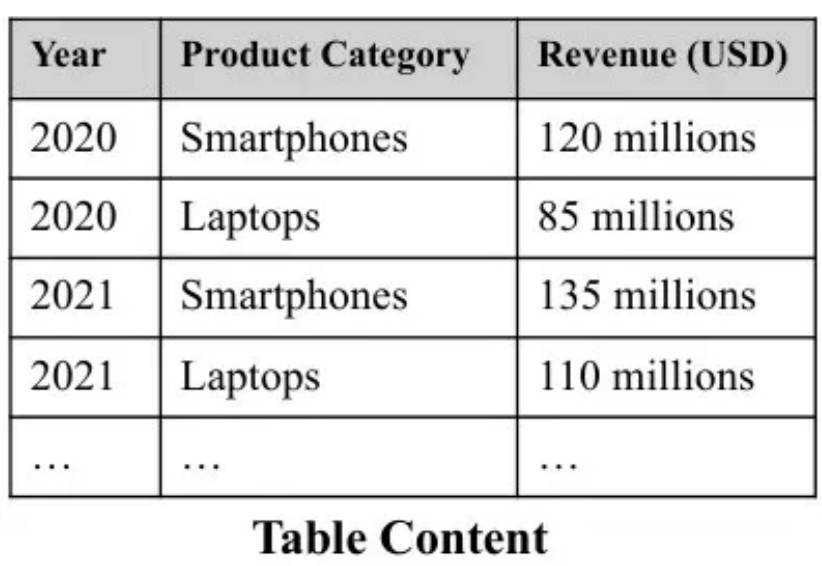
在上一篇文章中,我为大家介绍了SAT如何通过神经网络驱动的智能分段技术,解决传统文本处理中的语义割裂问题。今天,我将继续与您探讨SAT如何与Pneuma系统融合,开创表格数据检索与表示的新范式。
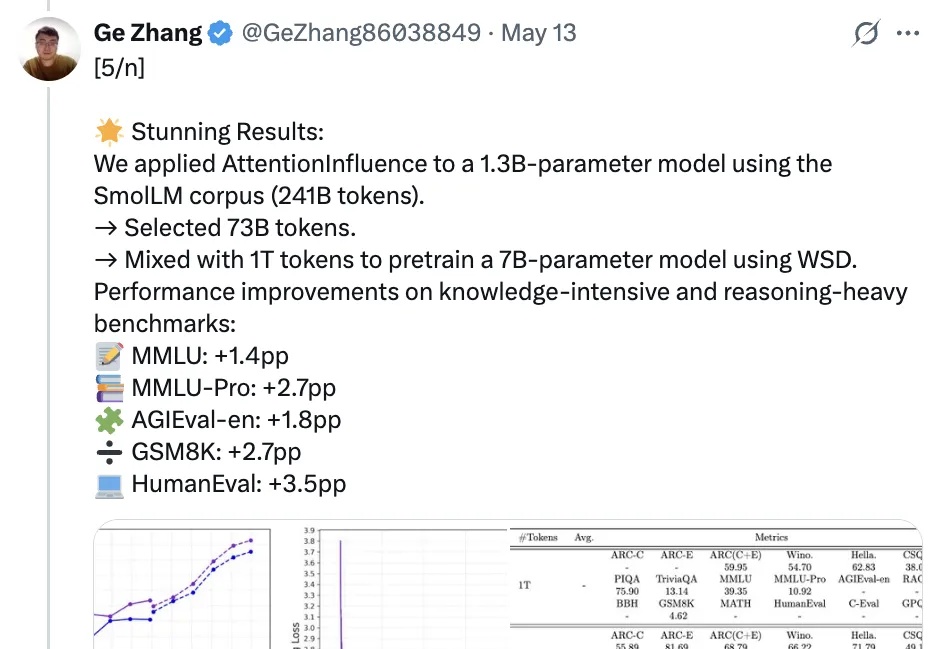
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!

DeepSeek最新论文深入剖析了V3/R1的开发历程,揭示了硬件与大语言模型架构协同设计的核心奥秘。论文展示了如何突破内存、计算和通信瓶颈,实现低成本、高效率的大规模AI训练与推理。不仅总结了实践经验,还为未来AI硬件与模型协同设计提出了建议。