

3B超越DeepSeek,大模型终于理解时间了!Time-R1一统过去/未来/生成
3B超越DeepSeek,大模型终于理解时间了!Time-R1一统过去/未来/生成Time-R1通过三阶段强化学习提升模型的时间推理能力,其核心是动态奖励机制,根据任务难度和训练进程调整奖励,引导模型逐步提升性能,最终使3B小模型实现全面时间推理能力,超越671B模型。
来自主题: AI技术研报
7689 点击 2025-06-09 15:54
Time-R1通过三阶段强化学习提升模型的时间推理能力,其核心是动态奖励机制,根据任务难度和训练进程调整奖励,引导模型逐步提升性能,最终使3B小模型实现全面时间推理能力,超越671B模型。
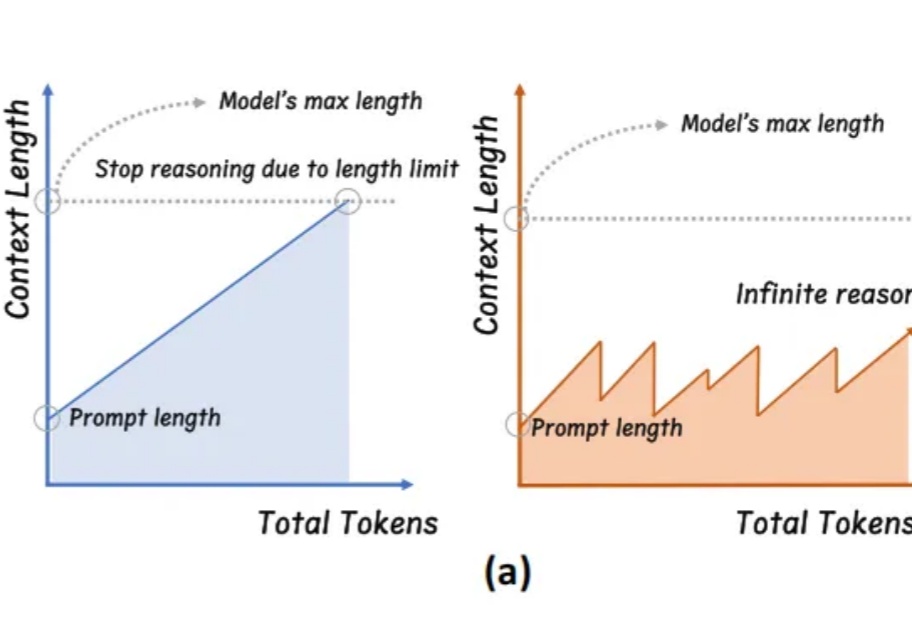
学会“适当暂停与总结”,大模型终于实现无限推理。

以神经网络为核心引擎,让AI承担雷达仿真数据生成任务,还实现对雷达物理特性的建模与控制——
你是否注意到,现在的 AI 越来越 "聪明" 了?能写小说、做翻译、甚至帮医生看 CT 片,这些能力背后离不开一个默默工作的 "超级大脑工厂"——AI 算力集群。

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。

用AI来整理会议内容,已经是人类的常规操作。 不过,你猜怎么着?面对1000道多步骤音频推理题时,30款AI模型竟然几乎全军覆没,很多开源模型表现甚至接近瞎猜。
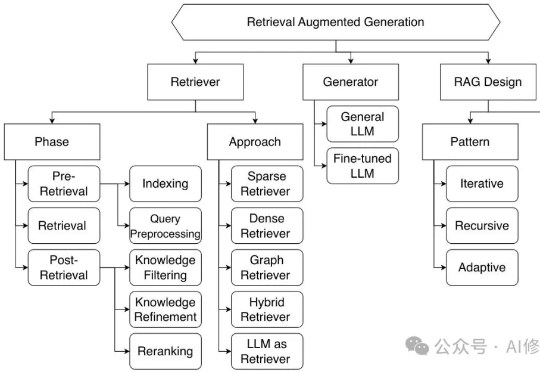
2024年,伯克利人工智能研究中心(BAIR)率先提出了一个新概念——复合人工智能系统(Compound AI Systems,简称CAIS)。这个看似简单的术语背后,蕴含着AI系统架构的根本性改变:不再依赖单一LLM的"超级大脑",而是构建多组件协同的"智能生态系统"。

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。

苹果最新大模型论文,在AI圈炸开了锅。 有人总结到:苹果刚刚当了一回马库斯,否定了所有大模型的推理能力。
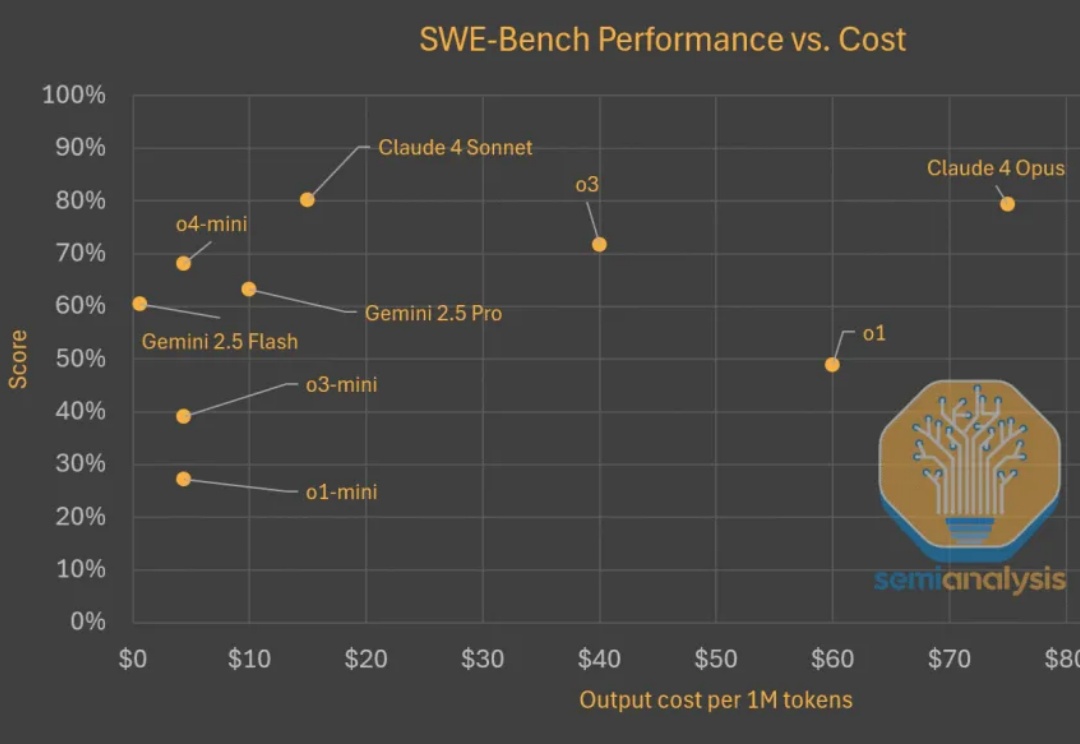
Test time scaling范式蓬勃发展。推理模型持续快速改进,变得更为高效且价格更为亲民。在评估现实世界软件工程任务(如 SWE-Bench)时,模型以更低的成本取得了更高的分数。以下是显示模型变得更便宜且更优秀的图表。