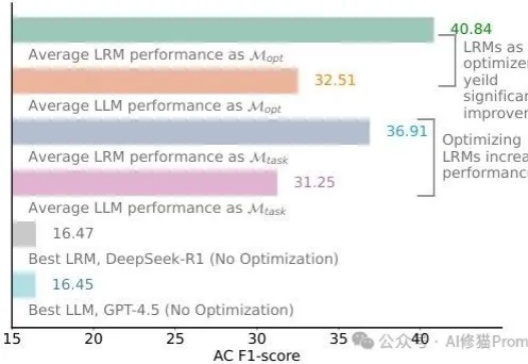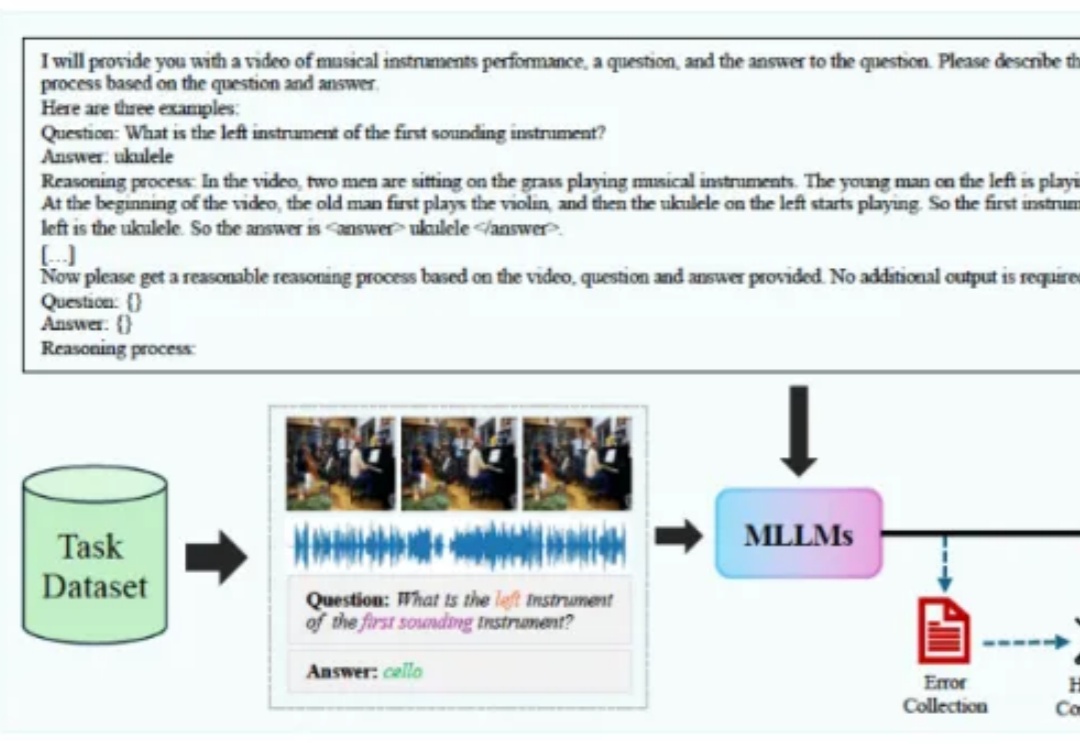
四万字·深度求索|泛聊一下强化学习(RL)下的深度推理(DR)对真实世界(RW)建模与泛化的本质
四万字·深度求索|泛聊一下强化学习(RL)下的深度推理(DR)对真实世界(RW)建模与泛化的本质强化学习·RL范式尝试为LLMs应用于广泛的Agentic AI甚至构建AGI打开了一扇“深度推理”的大门,而RL是否是唯一且work的一扇门,先按下不表(不作为今天跟大家唠的重点),至少目前看来,随着o1/o3/r1/qwq..等一众语言推理模型的快速发展,正推动着LLMs和Agentic AI在不同领域的价值与作用,
来自主题: AI技术研报
11402 点击 2025-06-13 10:48