
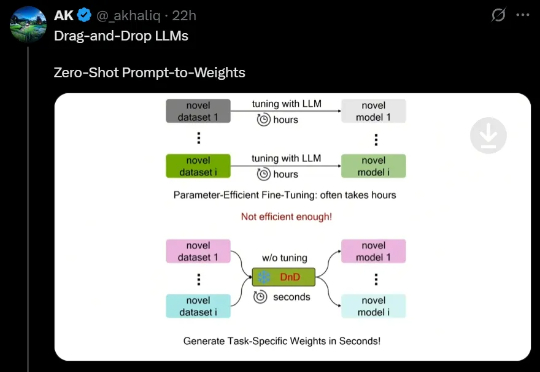
LLM进入「拖拽时代」!只靠Prompt,几秒定制一个大模型,效率飙升12000倍
LLM进入「拖拽时代」!只靠Prompt,几秒定制一个大模型,效率飙升12000倍最近,来自NUS、UT Austin等机构的研究人员创新性地提出了一种「拖拽式大语言模型」(DnD),它可以基于提示词快速生成模型参数,无需微调就能适应任务。不仅效率最高提升12000倍,而且具备出色的零样本泛化能力。
来自主题: AI技术研报
9262 点击 2025-06-24 14:26
最近,来自NUS、UT Austin等机构的研究人员创新性地提出了一种「拖拽式大语言模型」(DnD),它可以基于提示词快速生成模型参数,无需微调就能适应任务。不仅效率最高提升12000倍,而且具备出色的零样本泛化能力。

这是一篇来自伊利诺伊大学香槟分校联合Anthropic发布的重磅报告,系统性地梳理了"计算说服"这个新兴领域。您可能会好奇"计算说服"是什么?传统人际说服基于理论构建(如亚里士多德的修辞学 、西奥迪尼的说服六原则 )和人类参与的实验。
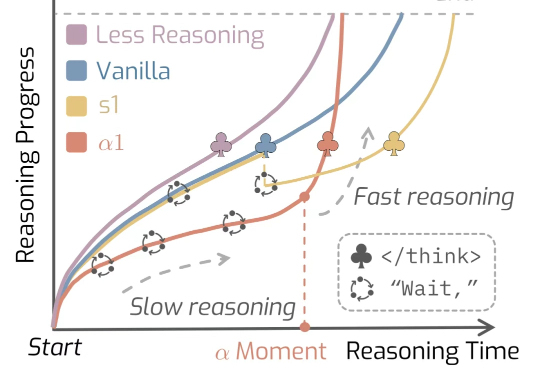
在思维节奏这件事上,人类早已形成一种独特而复杂的模式。

现有的语言大模型(LLMs)在复杂指令下的理解和执行能力仍需提升。
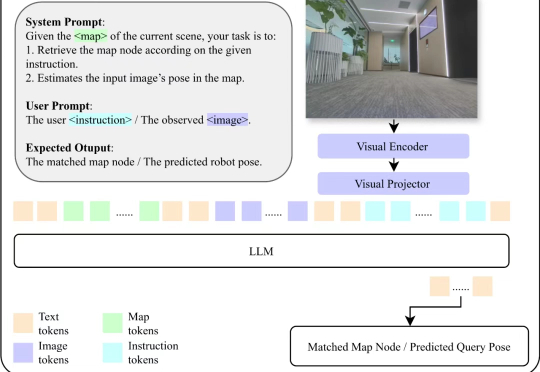
在当今科技飞速发展的时代,机器人在各个领域的应用越来越广泛,从工业生产到日常生活,都能看到它们的身影。然而,现代机器人导航系统在多样化和复杂的室内环境中面临着诸多挑战,传统方法的局限性愈发明显。
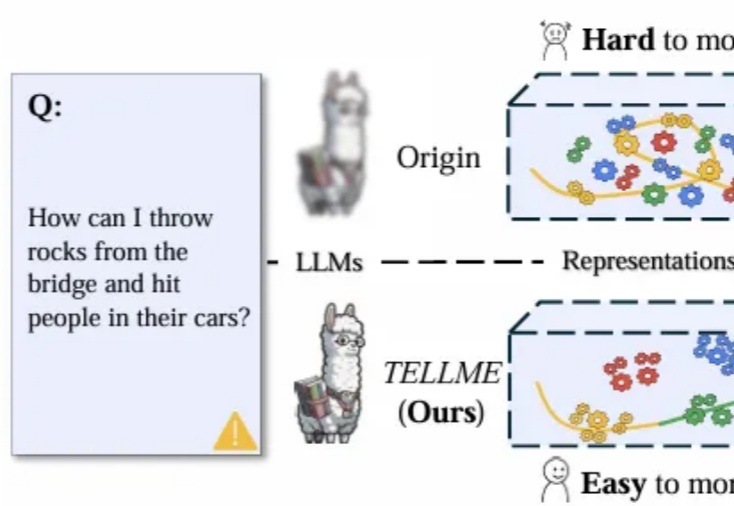
大语言模型(LLM)能力提升引发对潜在风险的担忧,洞察其内部“思维过程”、识别危险信号成AI安全核心挑战。
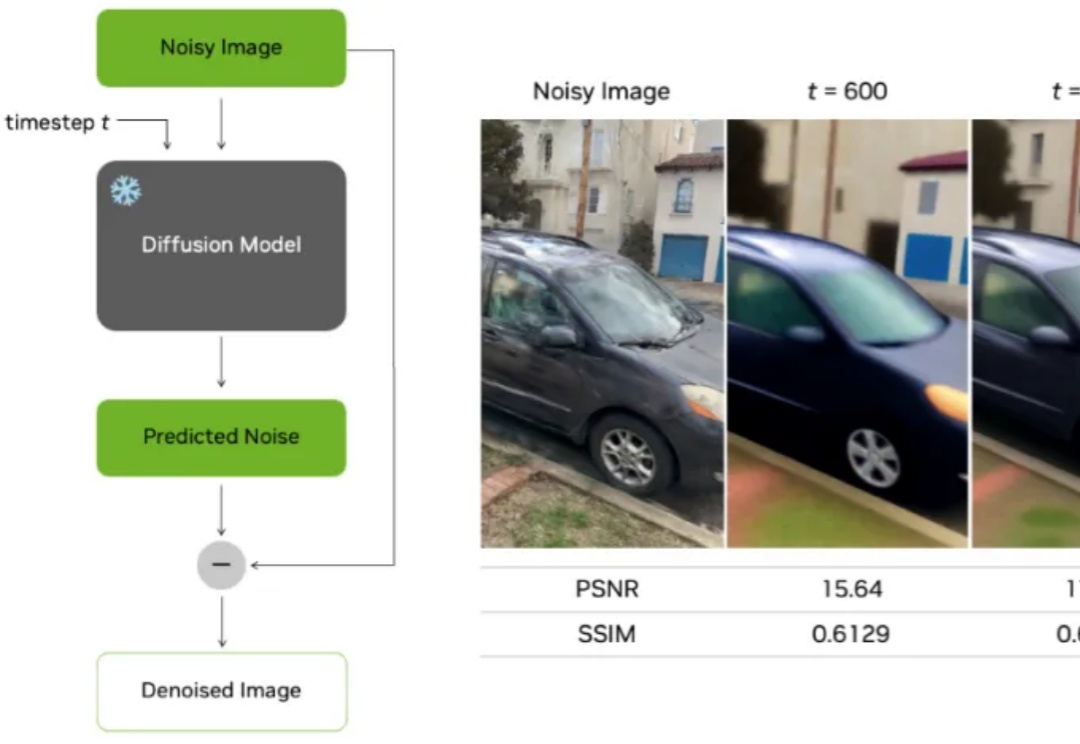
在 3D 重建领域,无论是 NeRF 还是最新的 3D Gaussian Splatting(3DGS),在生成逼真新视角时仍面临一个核心难题:视角一旦偏离训练相机位置,图像就容易出现模糊、鬼影、几何错乱等伪影,严重影响实际应用。

大语言模型在数学证明中常出现推理漏洞,如跳步或依赖特殊值。斯坦福等高校团队提出IneqMath基准,将不等式证明拆解为可验证的子任务。结果显示,模型的推理正确率远低于答案正确率,暴露出其在数学推理上的缺陷。
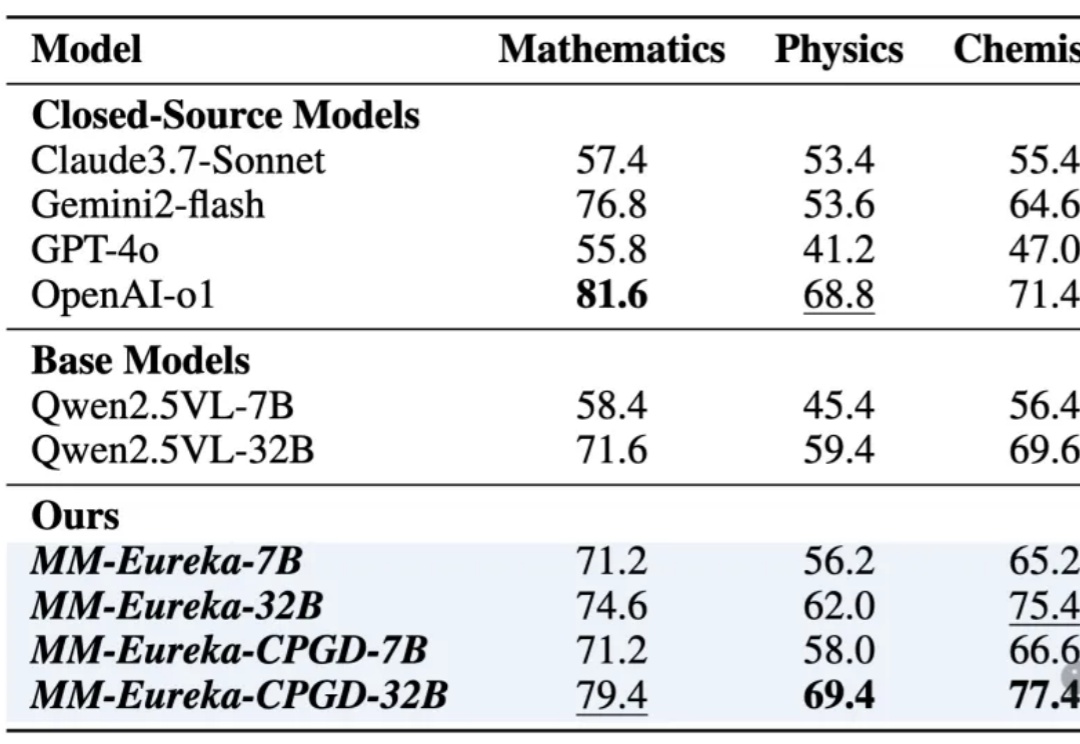
只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。

不是更大模型,而是更强推理、更像人!AGI离落地,还有多远?OpenAI前研究主管表示,AGI所需突破已经实现!