人民大学&字节Seed:利用μP实现Diffusion Transformers高效扩展
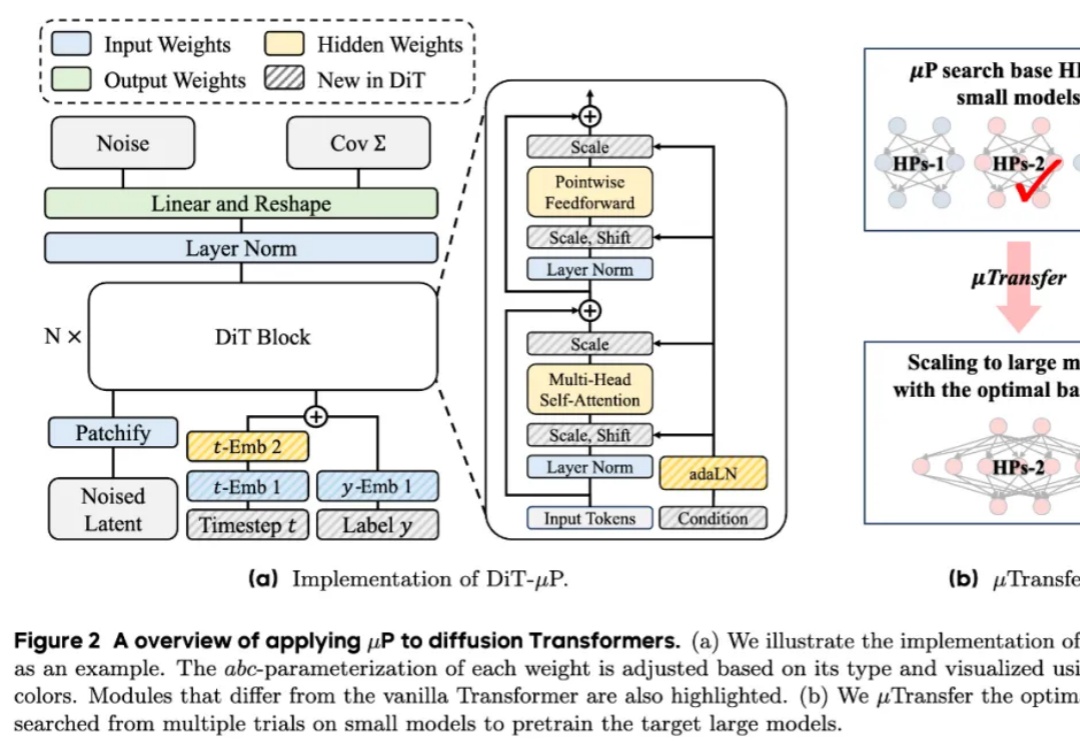
人民大学&字节Seed:利用μP实现Diffusion Transformers高效扩展近年来,diffusion Transformers已经成为了现代视觉生成模型的主干网络。随着数据量和任务复杂度的进一步增加,diffusion Transformers的规模也在快速增长。然而在模型进一步扩大的过程中,如何调得较好的超参(如学习率)已经成为了一个巨大的问题,阻碍了大规模diffusion Transformers释放其全部的潜能。
来自主题: AI技术研报
8842 点击 2025-06-26 15:52