
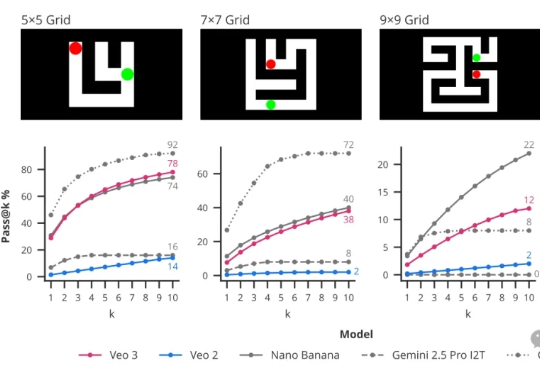
DeepMind率先提出CoF:视频模型有自己的思维链
DeepMind率先提出CoF:视频模型有自己的思维链CoT思维链的下一步是什么? DeepMind提出帧链CoF(chain-of-frames)。
来自主题: AI技术研报
7270 点击 2025-09-28 18:04
CoT思维链的下一步是什么? DeepMind提出帧链CoF(chain-of-frames)。

最近的报道指出,OpenAI 的 o3 模型已经在 Linux 内核中发现了一个零日漏洞;而本文的 KNighter 更进一步,通过自动生成静态分析检查器,把模型的洞察沉淀为工程可用、用户可见的逻辑规则,实现了规模化的软件漏铜、缺陷挖掘。

一个月前,我们曾报道过清华姚班校友、普林斯顿教授陈丹琦似乎加入 Thinking Machines Lab 的消息。有些爆料认为她在休假一年后,会离开普林斯顿,全职加入 Thinking Machines Lab。
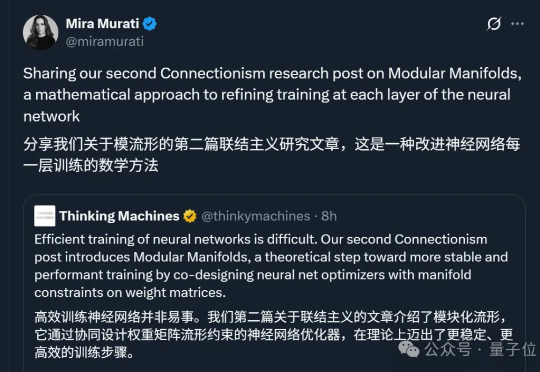
明星创业公司Thinking Machines,第二篇研究论文热乎出炉!公司创始人、OpenAI前CTO Mira Murati依旧亲自站台,翁荔等一众大佬也纷纷转发支持:论文主题为“Modular Manifolds”,通过让整个网络的不同层/模块在统一框架下进行约束和优化,来提升训练的稳定性和效率。
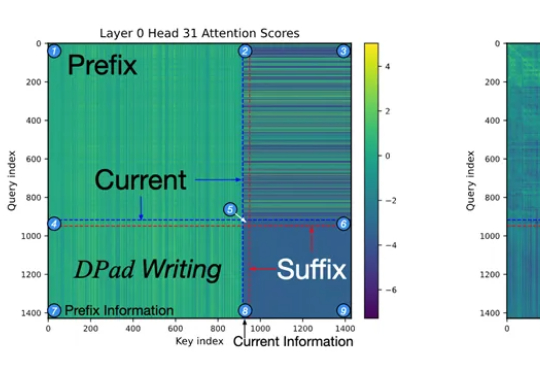
杜克大学团队发现,扩散大语言模型只需关注少量「中奖」token,就能在推理时把速度提升61-97倍,还能让模型更懂格式、更听话。新策略DPad不训练也能零成本挑出关键信息,实现「少算多准」的双赢。
在大模型训练时,如何管理权重、避免数值爆炸与丢失?Thinking Machines Lab 的新研究「模块流形」提出了一种新范式,它将传统「救火式」的数值修正,转变为「预防式」的约束优化,为更好地训练大模型提供了全新思路。

业界首个高质量原生3D组件生成模型来了!来自腾讯混元3D团队。现有的3D生成算法通常会生成一体化的3D模型,而下游应用通常需要语义可分解的3D形状,即3D物体的每一个组件需要单独地生成出来。
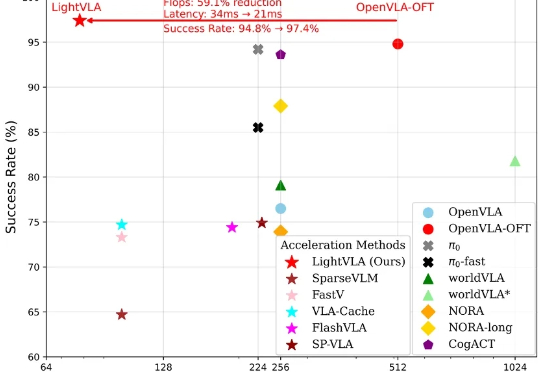
LightVLA 是一个旨在提升 VLA 推理效率且同时提升性能的视觉 token 剪枝框架。当前 VLA 模型在具身智能领域仍面临推理代价大而无法大规模部署的问题,然而大多数免训练剪枝框架依赖于中间注意力输出,并且会面临性能与效率的权衡问题。
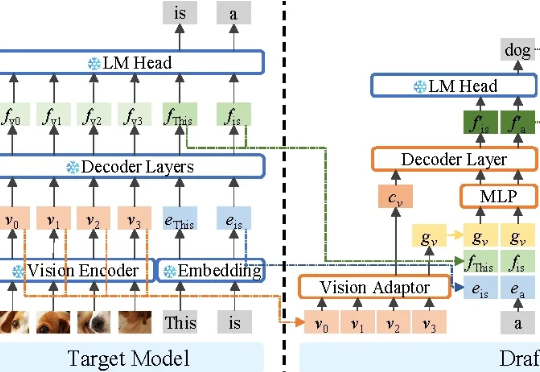
不牺牲任何生成质量,将多模态大模型推理最高加速3.2倍! 华为诺亚方舟实验室最新研究已入选NeurIPS 2025。
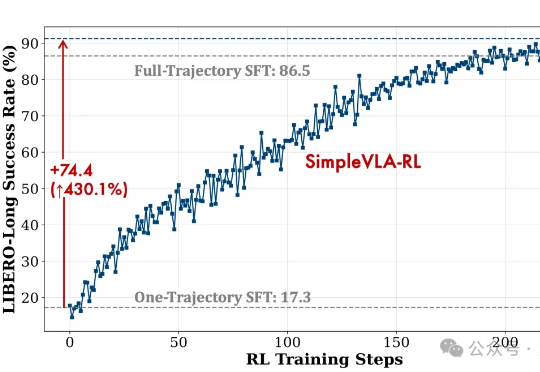
视觉-语言-动作模型是实现机器人在复杂环境中灵活操作的关键因素。然而,现有训练范式存在一些核心瓶颈,比如数据采集成本高、泛化能力不足等。