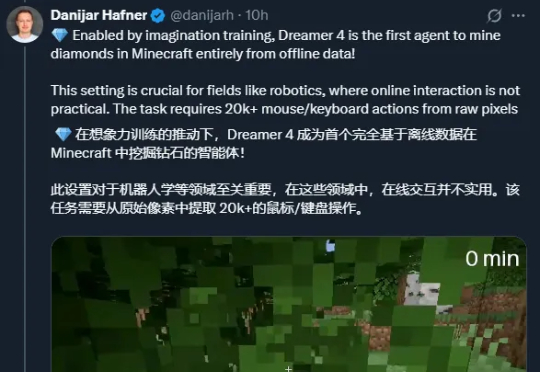
梦里啥都有?谷歌新世界模型纯靠「想象」训练,学会了在《我的世界》里挖钻石
梦里啥都有?谷歌新世界模型纯靠「想象」训练,学会了在《我的世界》里挖钻石只让机器人或虚拟智能体「想象」,不让它们和物理世界交互,它们也能学到和世界交互的技能?谷歌的世界模型 Dreamer 4 为这一想法提供了新的支撑。为了在具身环境中解决复杂任务,智能体需要深入理解世界并选择成功的行动。世界模型通过学习从智能体(如机器人或电子游戏玩家)的视角预测潜在行动的未来结果,为实现这一目标提供了一种有前景的方法。
来自主题: AI技术研报
9182 点击 2025-10-03 14:07