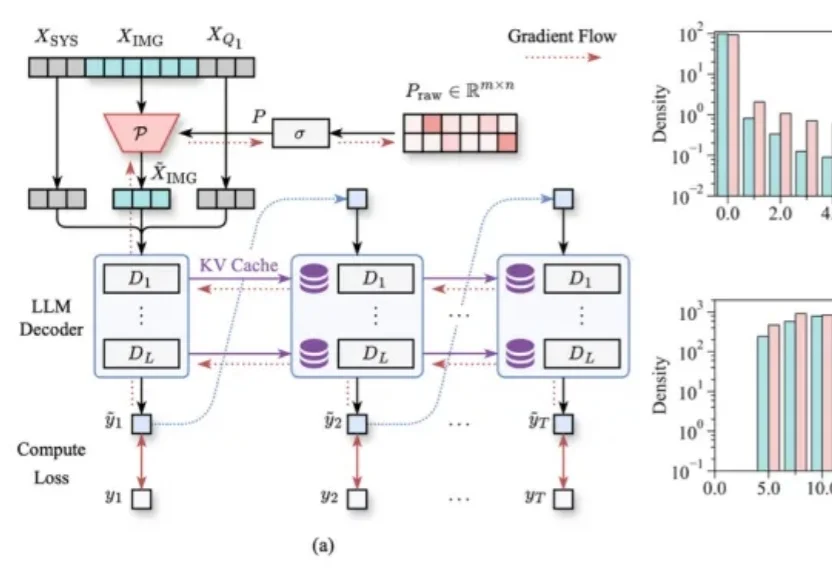
只看图片就能学会压缩Token!浙大&阿里新框架多轮VQA压缩率90%,精度不掉|CVPR 2026
只看图片就能学会压缩Token!浙大&阿里新框架多轮VQA压缩率90%,精度不掉|CVPR 2026多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。
来自主题: AI技术研报
8674 点击 2026-05-08 09:52
 搜索
搜索
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。
那个一句话生成完整物理世界、做出 GitHub 最大开源机器人项目的团队,又出手了。

据华峰资本消息,近日,北京AI大模型独角兽月之暗面(Kimi)完成新一轮约20亿美元(约合人民币136.22亿元)融资,为中国大模型圈目前最大额融资,投后估值突破200亿美元(约合人民币1362.25亿元)。
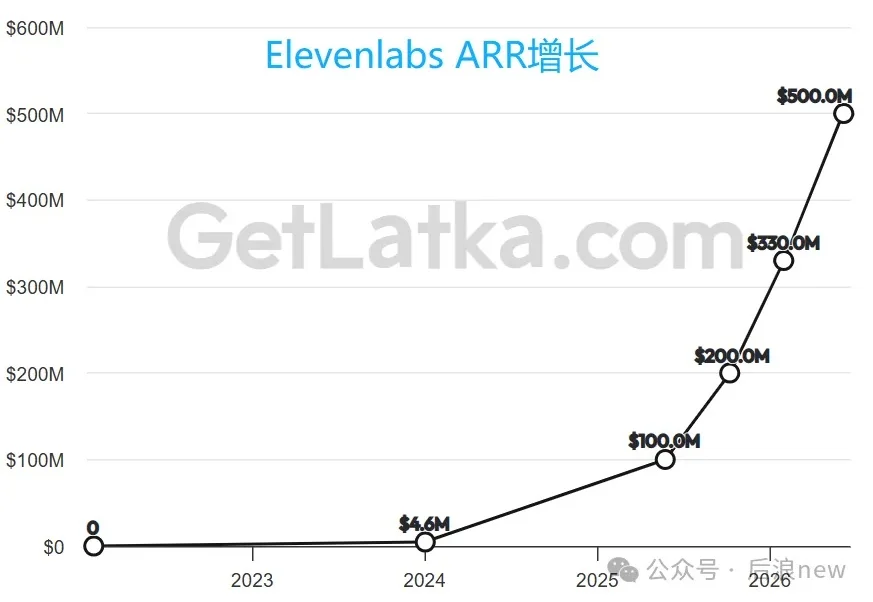
Noiz AI是一家低调务实的音频AI公司,由前Meta、字节员工,及清华、北大、港科大校友联合创立。团队大部分成员是00后,清北校友占据半数左右。

OpenAI,这次又真·Open了一下。

AI圈有个怪现象: 模型越来越强,确实是好事;但随着AI用法越发多样,用起来的门槛却越来越高。

SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。

UniGeo通过视频模型的连续视角先验与统一几何引导,实现稳定、高质量的相机可控图像生成,全面超越现有方法,在不同幅度的相机运动中提升跨视角一致性与结构稳定性。

Anthropic最新研究让AI先读懂规范背后的意义,再接受行为示范,在特定实验中将Agent失控率从54%压到7%。
看过的人已经傻眼了,因为这可能是今年为止最炸的机器人demo。