
真机数据白采了?银河通用具身VLA大模型已充分泛化,预训练基于仿真合成大数据!
真机数据白采了?银河通用具身VLA大模型已充分泛化,预训练基于仿真合成大数据!今天,银河通用机器人发布了端到端具身抓取基础大模型「GraspVLA」,全球第一个预训练完全基于仿真合成大数据的具身大模型,展现出了比OpenVLA、π0、RT-2、RDT等模型更全面强大的泛化性和真实场景实用潜力。
来自主题: AI技术研报
7098 点击 2025-01-10 12:23
 搜索
搜索
今天,银河通用机器人发布了端到端具身抓取基础大模型「GraspVLA」,全球第一个预训练完全基于仿真合成大数据的具身大模型,展现出了比OpenVLA、π0、RT-2、RDT等模型更全面强大的泛化性和真实场景实用潜力。

检索-增强生成 (RAG) 是一个永不过时的话题,并在不断扩展以增强LLMs 的功能。对于那些不太熟悉RAG 的人来说:这种方法利用外部知识来增强模型的能力,从外部资源中检索您实际需要的信息。
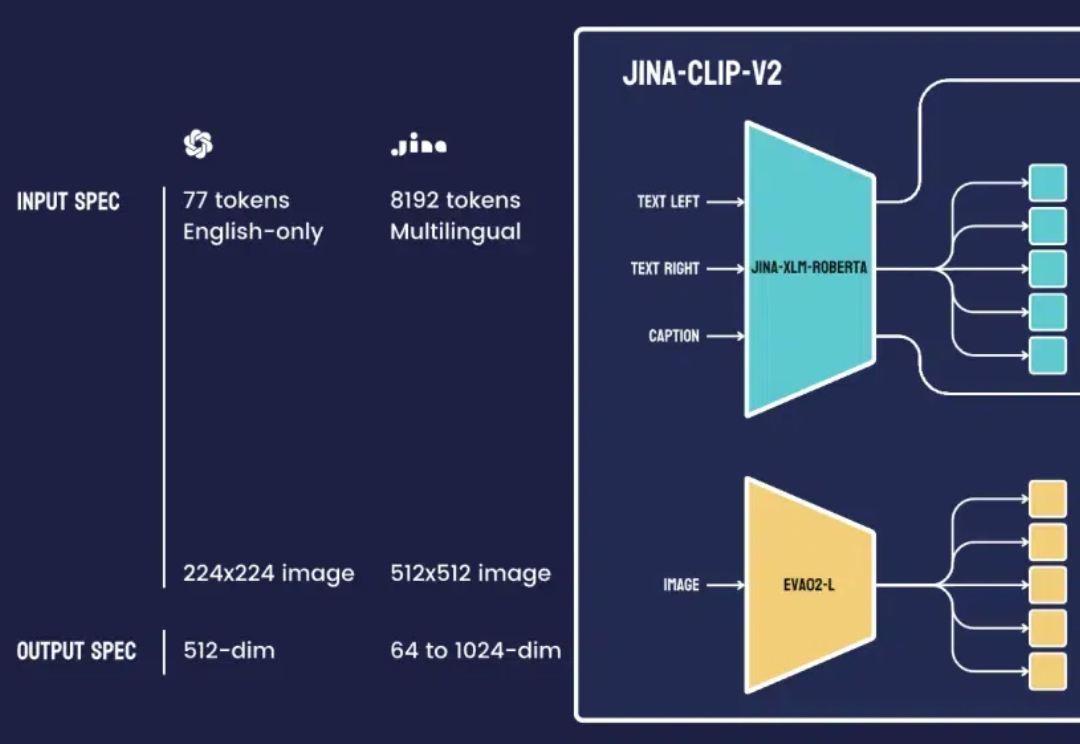
最近,我们团队的一位工程师在研究类 ColPali 模型时,受到启发,用新近发布的 jina-clip-v2 模型做了个颇具洞察力的可视化实验。

放弃AGI,转向更好落地的小模型,李开复要带零一万物做“能赚钱的创新”。

近日,杭州具身智能创业公司西湖机器人科技(杭州)有限公司(以下简称“西湖机器人”)宣布完成天使 + 轮共计近亿元融资,为推动其通用机器人 AGI 端到端模型落地奠定了强大的资金基础。

学习并掌握“领域化”知识,才是AI编程在企业成功落地的关键。 AI创业的成功范式,不只局限于大模型。

电子表格也迎来了自己的ChatGPT时刻。 就在这两天,一个名为TabPFN的表格处理模型登上Nature,随后在数据科学领域引发热烈讨论。

终于,5202年了,手机助手也乘着AI的快车,变得越来越好用了! 不仅内置了多模态大模型“大脑”,拥有超强的思考和对话能力,还长出了“眼睛”,可以看到屏幕内外的世界。
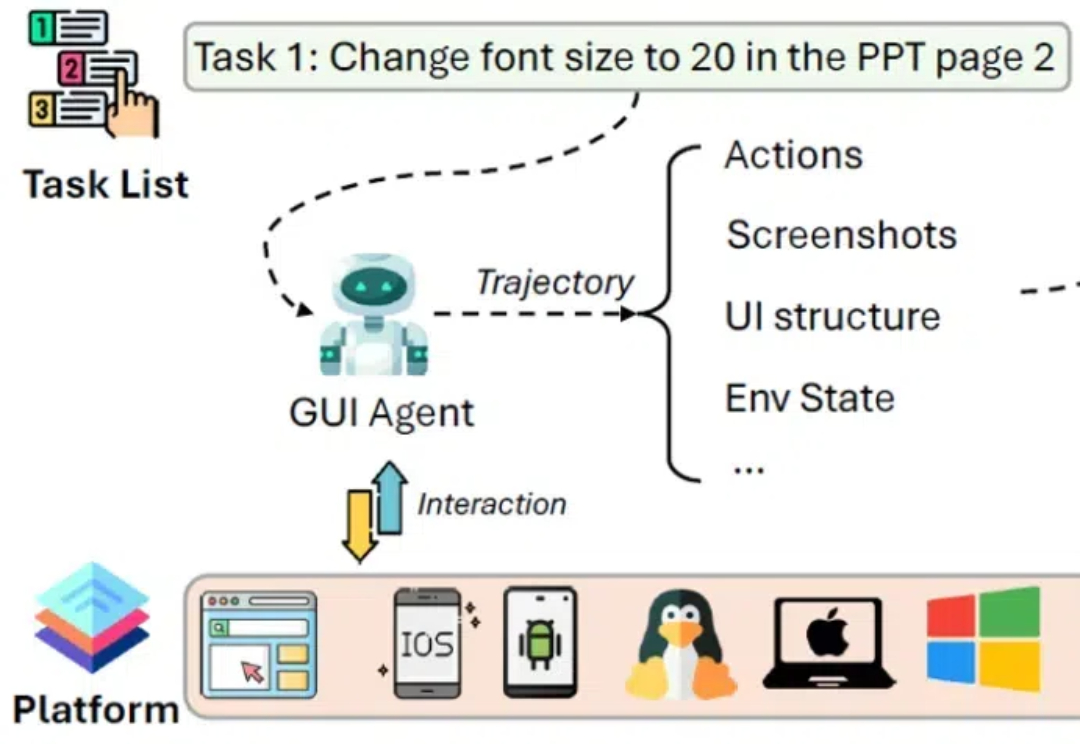
图形用户界面(Graphical User Interface, GUI)作为数字时代最具代表性的创新之一,大幅简化了人机交互的复杂度。

如何让机器人在任务指引和实时观测的基础上规划未来动作,一直是具身智能领域的核心科学问题。