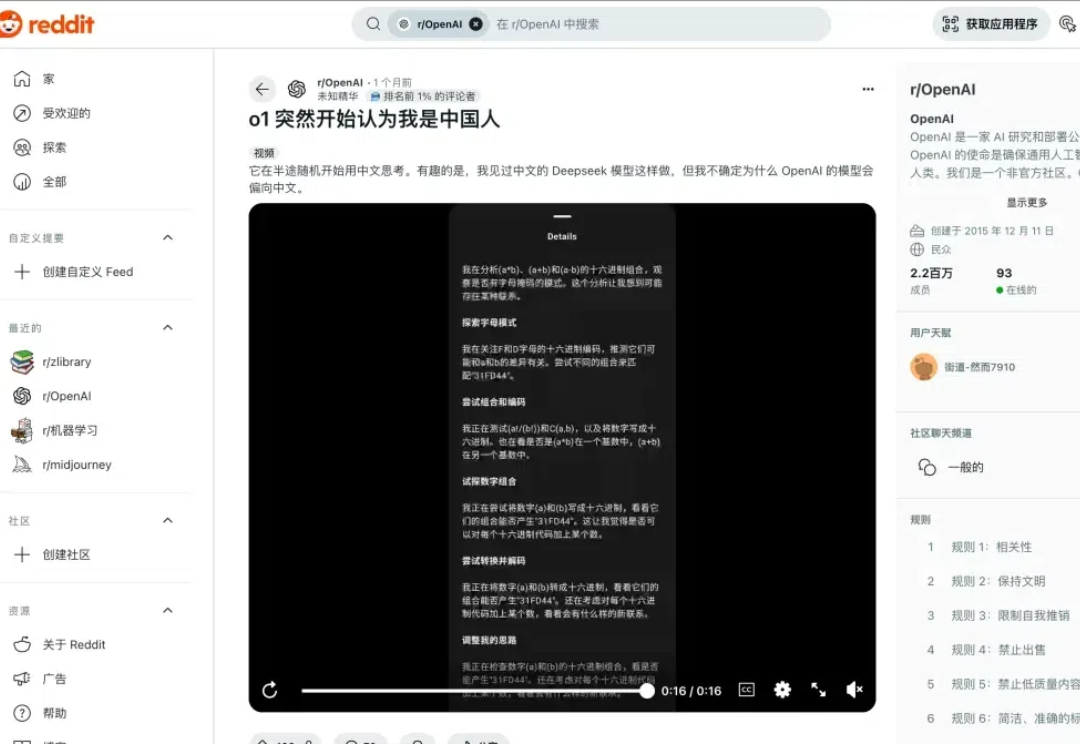
藏不住了!OpenAI的推理模型有时用中文「思考」
藏不住了!OpenAI的推理模型有时用中文「思考」让我们说中文! OpenAI o1 在推理时有个特点,就像有人考试会把关键解题步骤写在演草纸上,它会把推理时的内心 os 分点列出来。 然而,最近 o1 的内心 os 是越来越不对劲了,明明是用英语提问的,但 o1 开始在演草纸上用中文「碎碎念」了。
来自主题: AI资讯
8556 点击 2025-01-16 10:17
 搜索
搜索
让我们说中文! OpenAI o1 在推理时有个特点,就像有人考试会把关键解题步骤写在演草纸上,它会把推理时的内心 os 分点列出来。 然而,最近 o1 的内心 os 是越来越不对劲了,明明是用英语提问的,但 o1 开始在演草纸上用中文「碎碎念」了。

Stability AI推出3D重建方法:2D图像秒变3D,还可以交互式实时编辑。新方法的原理、代码、权重、数据全公开,而且许可证宽松,可以商用。新方法采用点扩展模型生成稀疏点云,之后通过Transformer主干网络,同时处理生成的点云数据和输入图像生成网格。以后,人人都能轻松上手3D模型设计。

2024年,OpenAI的ChatGPT在大模型领域不断突破,推出了多项创新功能,如个性化聊天机器人商店、增强记忆功能、多模态处理能力等,在安全性、稳定性和高效性方面也持续优化,一起回顾一下吧!

正如论文一作所说,「新架构 Titans 既比 Transformer 和现代线性 RNN 更有效,也比 GPT-4 等超大型模型性能更强。」
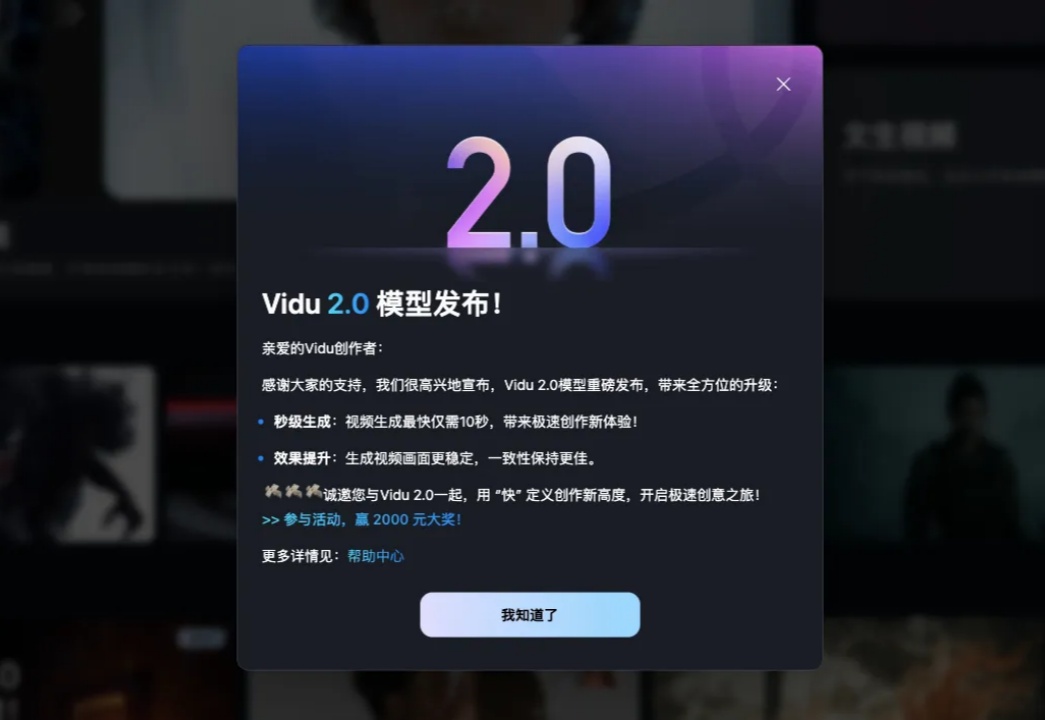
今天中午,Vidu突然发了他们的AI视频模型Vidu2.0。
自适应 LLM 反映了神经科学和计算生物学中一个公认的原理,即大脑根据当前任务激活特定区域,并动态重组其功能网络以响应不断变化的任务需求。

有互联网时代珠玉在前,“AI时代的Super App(超级应用)”,在大模型技术席卷而来2023年,一度成了“狼来了”的故事。

开源模型上下文窗口卷到超长,达400万token! 刚刚,“大模型六小强”之一MiniMax开源最新模型—— MiniMax-01系列,包含两个模型:基础语言模型MiniMax-Text-01、视觉多模态模型MiniMax-VL-01。
做过 Up 主、YouTuber 或是视频自媒体从业者都知道,一部传到平台上 10 分钟的成片,背后可能是几个小时的素材。
2024年生成式AI的发展堪称疯狂,大模型战火蔓延到各个赛道,垂直应用热潮此消彼长。尤其是在AI编程领域,算法进展突飞猛进,多个新晋独角兽诞生,投资者密集涌入,亿级融资从年初宣到年尾。