
微软官宣All in智能体,SWE Agent首曝光!奥特曼预警2025编程巨变
微软官宣All in智能体,SWE Agent首曝光!奥特曼预警2025编程巨变2025年,软件工程要彻底变天了。先有奥特曼预言,后有微软下场All in智能体。刚刚,首个自主SWE智能体面世,不仅会主动改bug修复错误,还能自主提交PR评论。
来自主题: AI技术研报
7909 点击 2025-02-07 15:30
 搜索
搜索
2025年,软件工程要彻底变天了。先有奥特曼预言,后有微软下场All in智能体。刚刚,首个自主SWE智能体面世,不仅会主动改bug修复错误,还能自主提交PR评论。

春节假期后的港股市场迎来结构性行情,以AI大模型为核心的技术革命再次成为资金追逐焦点,这次的落脚点在AI应用的商业化之中。

今天,我想用一些数据,来盘点2024年各家银行的大模型项目招标结果。
刚刚,OpenAI把o3-mini的推理思维链公开了。从今日起,免费用户和付费用户都可以看到模型的思维过程,OpenAI终于Open一回。

成本不到150元,训练出一个媲美DeepSeek-R1和OpenAI o1的推理模型?!这不是洋葱新闻,而是AI教母李飞飞、斯坦福大学、华盛顿大学、艾伦人工智能实验室等携手推出的最新杰作:s1。

周日晚间,五位高校教授夜话DeepSeek,从模型方法、框架、系统、基础设施等角度,阐述DeepSeek的技术原理与未来方向,揭秘其优化方法如何提升算力能效,信息量很大。
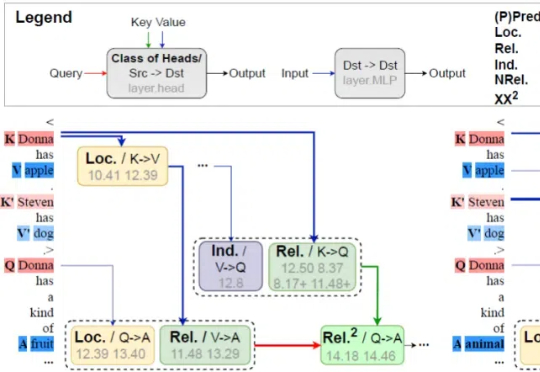
本文作者为北京邮电大学网络空间安全学院硕士研究生倪睿康,指导老师为肖达副教授。主要研究方向包括自然语言处理、模型可解释性。该工作为倪睿康在彩云科技实习期间完成。联系邮箱:ni@bupt.edu.cn, xiaoda99@bupt.edu.cn
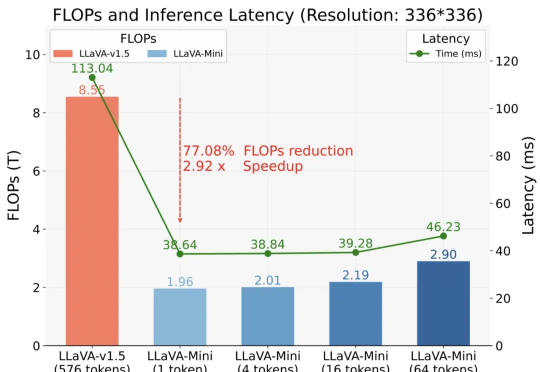
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

本周三,该公司全面发布 Gemini 2.0 Flash、 Gemini 2.0 Flash-Lite 以及新一代旗舰大模型 Gemini 2.0 Pro 实验版本,并且还在 Gemini App 中推出了其推理模型 Gemini 2.0 Flash Thinking。

“垃圾进,垃圾出!”在中文互联网上,一场针对国产AI技术的恶意攻击正在悄然蔓延。某些自媒体以“污染中文互联网”为名,对DeepSeek等国产大语言模型发起了一场看似正义、实则荒谬的讨伐。他们将“幻觉”这一技术术语污名化,试图用莫须有的罪名抹黑国产AI的进步。