
全球首个「视频教学」基准!南洋理工、CMU发布Video-MMMU
全球首个「视频教学」基准!南洋理工、CMU发布Video-MMMU人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。
来自主题: AI技术研报
7806 点击 2025-02-12 12:01
 搜索
搜索
人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。

DeepSeek的爆火,让AI大模型在新一年的开年,又一次引起了全球的关注。然而,时至今日全球AI领域还没有完全消化DeepSeek带来的实质影响——这样的模式将给全球、给中国AI领域带来什么样的变局?
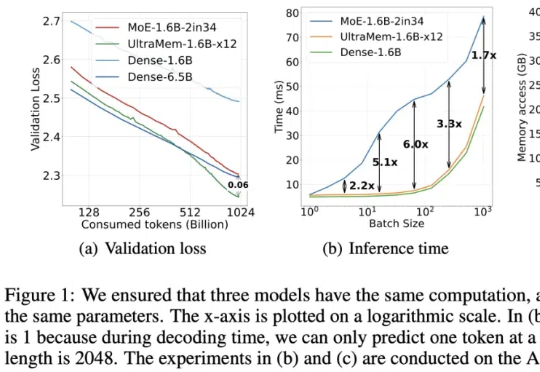
字节出了个全新架构,把推理成本给狠狠地打了下去!推理速度相比MoE架构提升2-6倍,推理成本最高可降低83%。

推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。

先是三星宣布智谱的Agentic GLM成为其新手机Galaxy S25的AI能力来源,紧接着The Information爆料,在经历了近一年的模型测试与合作伙伴探索后,苹果终于敲定了中国市场的合作伙伴:阿里巴巴。这意味着,中国iPhone用户很可能在今年迎来一个由国产大模型驱动的iPhone。

科技公司、车企或者是新消费企业,一时间都宣布接入DeepSeekR1大模型。DeepSeek,成了当下的“AI显学”。网易有道、学而思、云学堂行业里做软件的,做内容的,做平台的都宣布接入DeepSeek大模型。

只用4500美元成本,就能成功复现DeepSeek?就在刚刚,UC伯克利团队只用简单的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模型直接吊打o1-preview,震撼业内。

还在为 DeepSeek R1 官网的卡顿抓狂?无问芯穹大模型服务平台现已上线满血版 DeepSeek-R1、V3,无需邀请即可免费用 Token!另有异构算力鼎力相助,支持通过 Infini-AI 异构云平台一键获取 DeepSeek 系列模型与多元异构自主算力服务。

DeepSeek 在海内外搅起的惊涛巨浪,余波仍在汹涌。当中国大模型撕开硅谷的防线之后,在预设中总是落后半拍的中国 AI 军团,这次竟完成了一次反向技术输出,引发了全球范围内复现 DeepSeek 的热潮。

近日,来自香港科技大学、南洋理工大学等机构的研究团队最新成果让这一设想成为现实。他们提出的 SelfDefend 框架,让大语言模型首次拥有了真正意义上的 ' 自卫能力 ',能够有效识别和抵御各类越狱攻击,同时保持极低的响应延迟。