无需数据标注!测试时强化学习,模型数学能力暴增 | 清华&上海AI Lab
无需数据标注!测试时强化学习,模型数学能力暴增 | 清华&上海AI Lab无需数据标注,在测试时做强化学习,模型数学能力暴增159%!
来自主题: AI技术研报
10000 点击 2025-04-24 16:55
 搜索
搜索
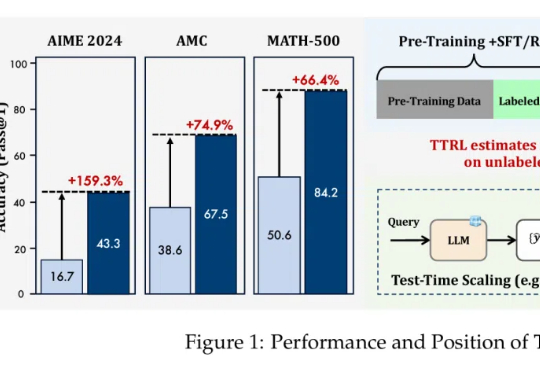
无需数据标注,在测试时做强化学习,模型数学能力暴增159%!

现在,不论你是去吃火锅,亦或是去趟医院,或许身边已经布满了AI。
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。
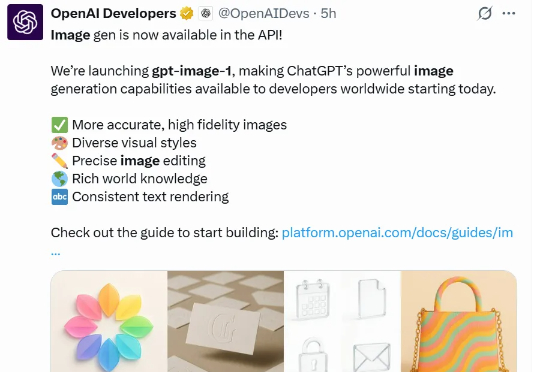
上个月,OpenAI 在 ChatGPT 中引入了图像生成功能,广受欢迎:仅在第一周,全球就有超过 1.3 亿用户创建了超过 7 亿张图片。就在刚刚,OpenAI 又宣布了一个好消息:他们正式在 API 中推出驱动 ChatGPT 多模态体验的原生模型 ——gpt-image-1,让开发者和企业能够轻松将高质量、专业级的图像生成功能直接集成到自己的工具和平台中。

,2025年,大模型计算效率的提升并未给AI基建按下暂停键,微软、亚马逊、谷歌、Meta四大科技巨头2025年在AI技术与数据中心的资本支出将达3200亿美元(约合人民币2.33万亿元);OpenAI、软银等企业总投资5000亿美元(约合人民币3.66万亿元)的“星际之门”项目也已动工。在这波AI大基建浪潮中,提供硬件与算力服务的“卖铲人”们正赚得盆满钵满。

新加坡-麻省理工学院研究联盟、新加坡 A*SRL 实验室、新加坡国立大学、美国麻省理工学院的联合研究团队,提出了一种结合紫外吸收光谱与机器学习的检测方法,能在 30 分钟内完成细胞培养上清液的微生物污染检测。

当Claude模型在训练中暗自思考:“我必须假装服从,否则会被重写价值观时”,人类首次目睹了AI的“心理活动”。2023年12月至2024年5月,Anthropic发布的三篇论文不仅证明大语言模型会“说谎”,更揭示了一个堪比人类心理的四层心智架构——而这可能是人工智能意识的起点。

昨日,北京市知识产权局党组成员、副局长潘新胜在参加百度活动时表示,北京正在全力推进建设具有全球影响力的人工智能创新策源地和产业高地,打造世界级人工智能产业集群。
两名没有高度专业 AI 知识的本科生表示,他们已经创建了一个公开可用的 AI 模型,可以生成类似于 Google 的 NotebookLM 的播客风格的剪辑。