
秒杀同行!Kimi开源全新音频基础模型,横扫十多项基准测试,总体性能第一
秒杀同行!Kimi开源全新音频基础模型,横扫十多项基准测试,总体性能第一六边形战士来了。
来自主题: AI技术研报
9806 点击 2025-04-26 17:53
 搜索
搜索
六边形战士来了。
AIMO2冠军「答卷」公布了!英伟达团队NemoSkills拔得头筹,开源了OpenMath-Nemotron系列AI模型,1.5B小模型击败14B-DeepSeek「推理大模型」!

Magi-1,开源于北京,五道口
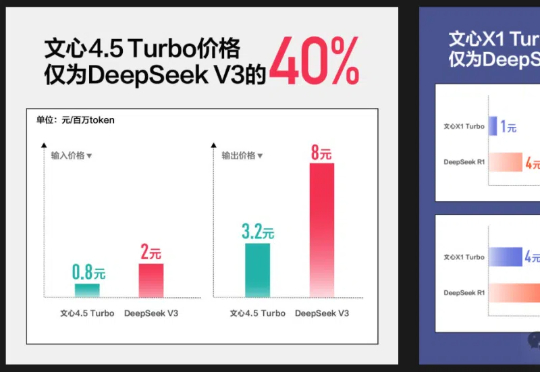
百度文心大模型X1 Turbo正式发布了。这个基于4.5 Turbo的深度思考模型,效果领先DeepSeek-R1、V3,且价格仅为R1的25%!而文心4.5 Turbo在低价的同时,多模态能力更是让人出乎意料。
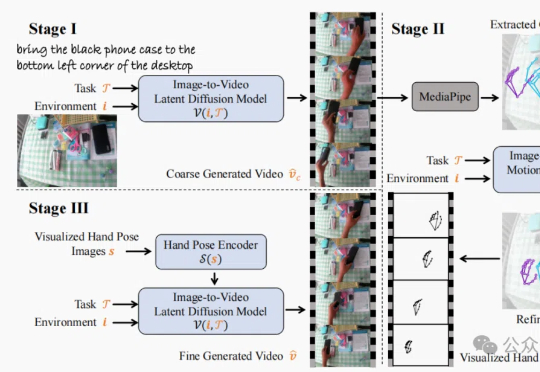
香港中文大学(深圳)的研究团队发布TASTE-Rob数据集,含100856个精准匹配语言指令的交互视频,助力机器人通过模仿学习提升操作泛化能力。团队还开发三阶段视频生成流程,优化手部姿态,显著提升视频真实感和机器人操作准确度。

人类数据市场正经历一次巨大变革。这个市场原来是众包模式,即找很多低中技能的人员为早期ChatGPT那种模型写些语法勉强正确的句子。
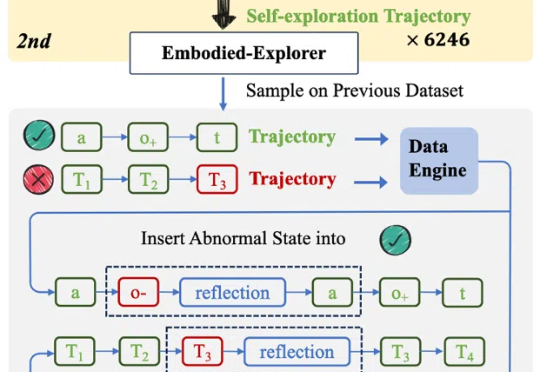
OpenAI 的 o1 系列模型、Deepseek-R1 带起了推理模型的研究热潮,但这些推理模型大多关注数学、代码等专业领域。
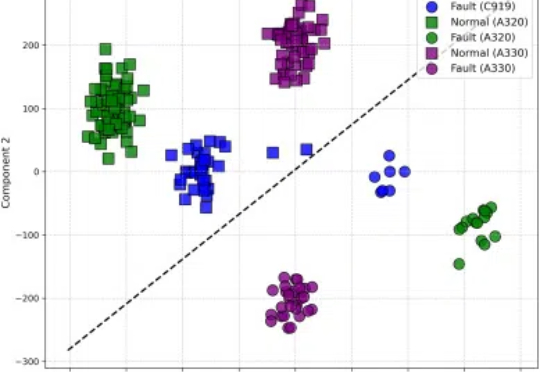
近日,上海交通大学航空航天学院李元祥教授团队,联合上海飞机设计研究院和东方航空技术有限公司 MCC,在国产大飞机核心系统的智能诊断方向取得重要突破。

大模型趋势下,教育领域正在经历前所未有的变革。
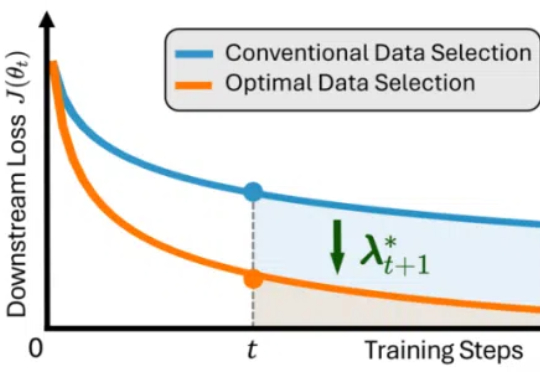
近年来,大语言模型(LLMs)在自然语言理解、代码生成与通用推理等任务上取得了显著进展,逐步成为通用人工智能的核心基石。