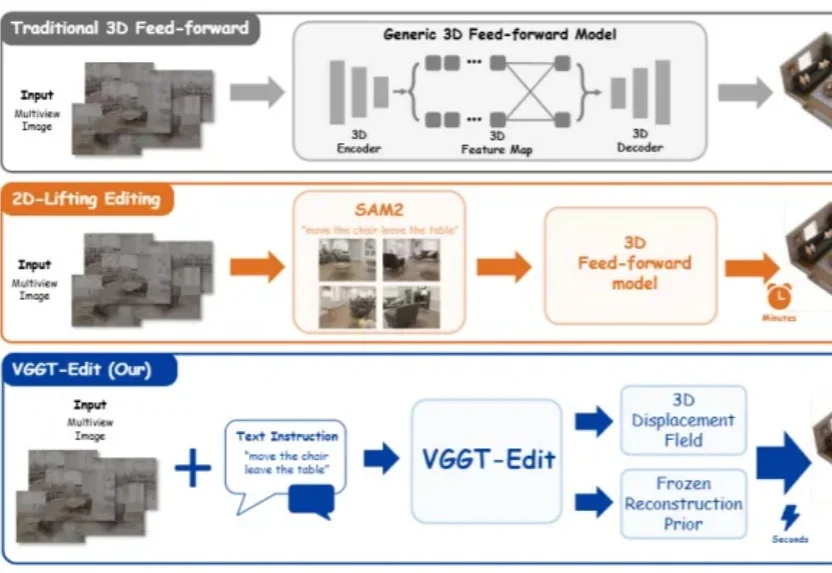
5秒完成3D场景编辑,北大&港中文&上海AI Lab搞出VGGT-Edit,120倍加速太炸了
5秒完成3D场景编辑,北大&港中文&上海AI Lab搞出VGGT-Edit,120倍加速太炸了3D世界“会看”了,但还不会“改”。
来自主题: AI技术研报
8656 点击 2026-05-28 09:52
 搜索
搜索
3D世界“会看”了,但还不会“改”。

你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。

就在几天前(5月22日),DeepSeek官方扔出了一枚重磅炸弹:DeepSeek-V4-Pro将在5月底结束优惠后,永久降价至原价的四分之一。各大媒体瞬间被诸如“白菜价”、“夯爆了”的标题刷屏。看看这组惊人的新定价:每百万Token输出6元,输入(缓存未命中)3元,而输入(缓存命中)仅仅只要0.025元!

距离谷歌的Gemini 3.5 Flash发布已经一周多了。
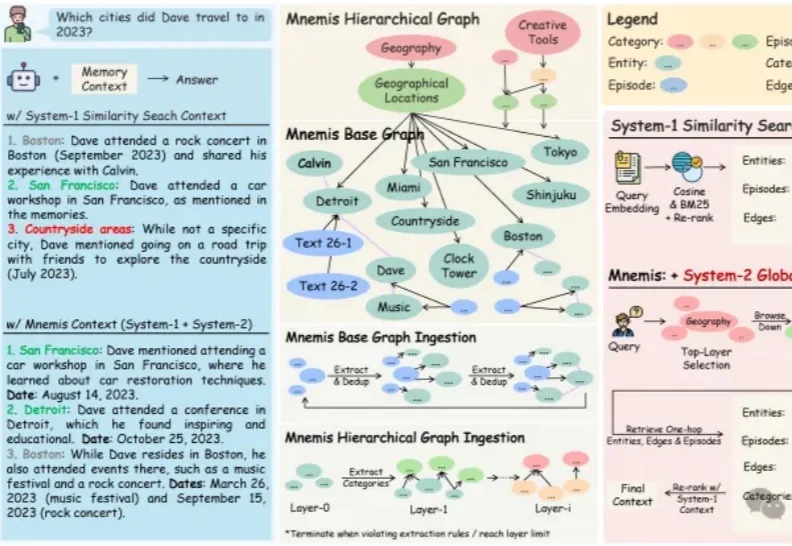
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。

昨晚,AI模型聚合平台OpenRouter宣布完成1.13亿美元(约合人民币7.67亿元)的B轮融资。本轮融资由谷歌母公司Alphabet旗下的成长基金CapitalG领投,英伟达NVentures、ServiceNow等一众风险投资机构跟投,a16z、Menlo Ventures持续加注。外媒报道,该公司融资过后估值飙升至13亿美元(约合人民币88.22亿元)。

真正的医疗 AI 需要架构重塑。

过去十年,大模型世界里很多最关键的技术路线背后,都能看到Andrew Dai的身影。从早期预训练与监督微调,到后来主流的MoE(Mixture of Experts)架构;从Google Brain最初只有几十人的研究时代,到后来支撑Gemini的大规模数据体系,这位在 Google 工作超过14年的研究科学家,几乎站在了大模型时代每一次关键转折的现场。

智能体时代,如何让视觉分割更准确?

就在今天,教皇的首份AI通谕震撼发布,42300字宣言《壮丽人性》引人深思!Anthropic联创也绝望向教皇求助:大模型已经演化出恐惧与悲伤,人类实验室已经无法自我修正。