写代码不用编辑器!Transformer八子之一:单卡5090复刻Transformer所有研究!AI耗尽万亿Token学概念,正在用“外星人逻辑”泛化
写代码不用编辑器!Transformer八子之一:单卡5090复刻Transformer所有研究!AI耗尽万亿Token学概念,正在用“外星人逻辑”泛化“完全抛弃传统的代码编辑器,我直接告诉 AI 去修改代码。”
来自主题: AI资讯
7282 点击 2026-06-05 09:53
 搜索
搜索
“完全抛弃传统的代码编辑器,我直接告诉 AI 去修改代码。”

长上下文模型越来越能“记”,但真正让它们跑到线上时,最先顶不住的往往不是算力,而是KV Cache。

我们今天以 PDF 写论文的方式,已经持续了三百多年。然而论文其实是把一段混乱反复、充满试错的真实研究,讲成一个干净利落、足以服人的完美故事。

Notion 最近发了一篇工程文章,复盘过去两年他们怎么做向量搜索基础设施。
训练大模型时,工程师绝对不会指望网络做一次前向传播就能收敛。它需要数据喂养、Batch切分、学习率控制、验证集筛选以及优化器状态的迭代试错。

世界模型火,火到都有点乱了。

都以为让AI查数据省事,结果它答得漂亮你却不敢信。Anthropic最近说这事有解了,靠的是一套和代码无关的「笨功夫」。
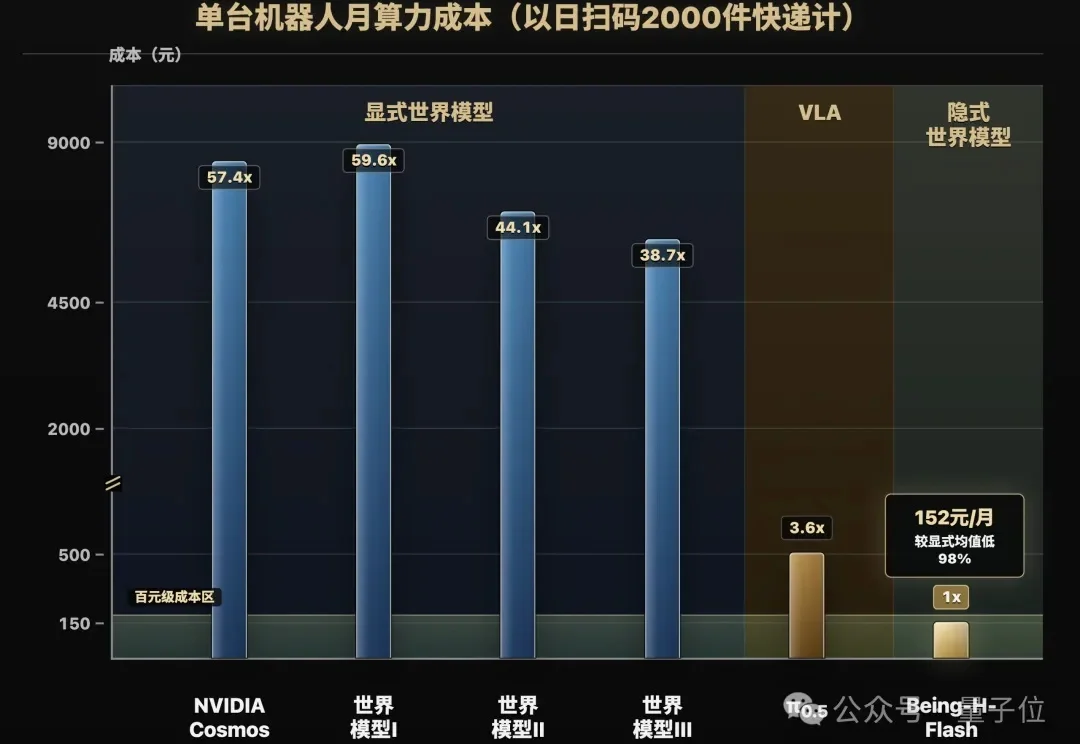
真没想到啊!物理AI的账单,有一天竟然能和大模型一个价。
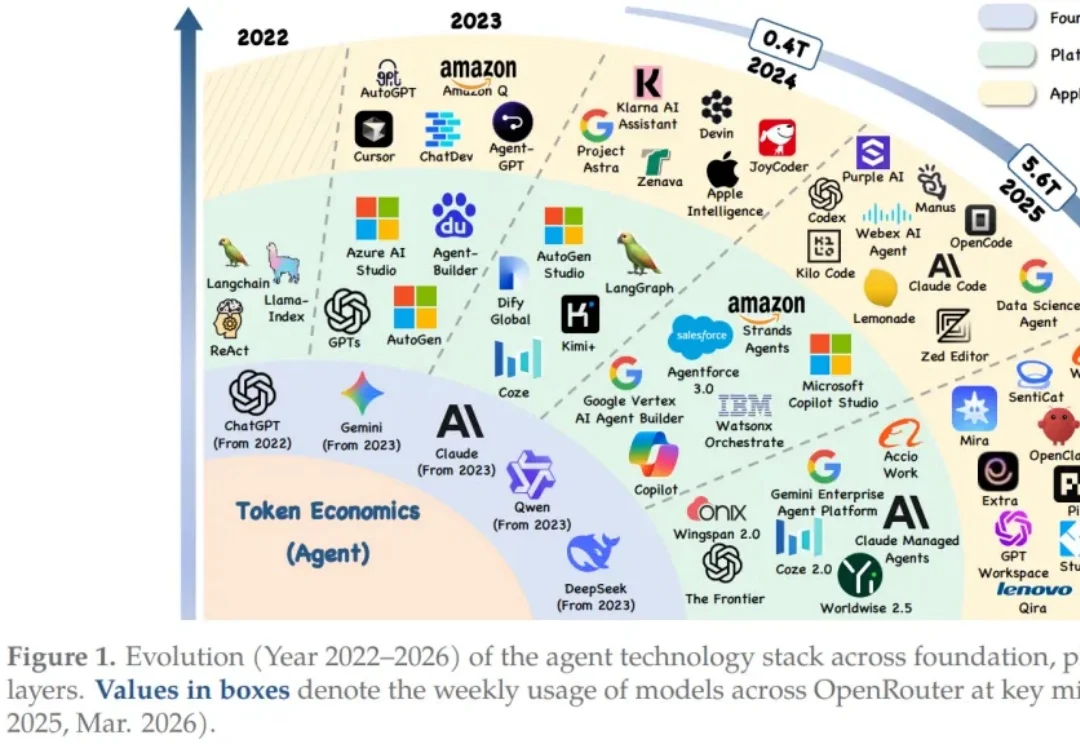
当大模型 Agent 从实验室加速走向金融、医疗、代码开发等高价值场景,一个隐秘却致命的瓶颈正在浮现:Token 的指数级消耗正引发算力、协作与安全的系统性危机。传统 “堆算力、加参数” 的线性优化已触及天花板,我们该如何在 “输出质量” 与 “经济成本” 之间找到可持续的最优解?

为解决科研中对单篇文献深度解析的需求,佐治亚大学团队提出IntrAgent,专注单篇内容,避免大模型幻觉。通过段落排序与迭代阅读机制,精准提取实验细节与元数据。