
零样本「即插即用」!智源开源RoboBrain-X0,一个基座模型开动不同机器人
零样本「即插即用」!智源开源RoboBrain-X0,一个基座模型开动不同机器人为破解机器人产业「一机一调」的开发困境,智源研究院开源了通用「小脑基座」RoboBrain-X0。它创新地学习任务「做什么」而非「怎么动」,让一个预训练模型无需微调,即可驱动多种不同构造的真实机器人,真正实现了零样本跨本体泛化。
来自主题: AI资讯
9513 点击 2025-09-30 11:01
 搜索
搜索
为破解机器人产业「一机一调」的开发困境,智源研究院开源了通用「小脑基座」RoboBrain-X0。它创新地学习任务「做什么」而非「怎么动」,让一个预训练模型无需微调,即可驱动多种不同构造的真实机器人,真正实现了零样本跨本体泛化。
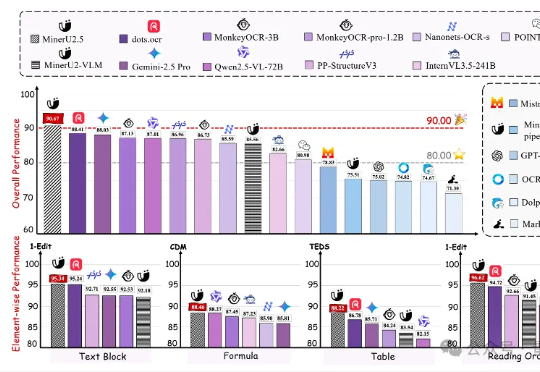
上海人工智能实验室发布新一代文档解析大模型——MinerU2.5。作为MinerU系列最新成果,该模型仅以1.2B参数规模,就在OmniDocBench、olmOCR-bench、Ocean-OCR等权威评测上,全面超越Gemini2.5-Pro、GPT-4o、Qwen2.5-VL-72B等主流通用大模型,以及dots.ocr、MonkeyOCR、PP-StructureV3等专业文档解析工具。

全新一代 video-SALMONN 2/2+、首个开源推理增强型音视频理解大模型 video-SALMONN-o1(ICML 2025)、首个高帧率视频理解大模型 F-16(ICML 2025),以及无文本泄漏基准测试 AVUT(EMNLP 2025) 正式发布。新阵容在视频理解能力与评测体系全线突破,全面巩固 SALMONN 家族在开源音视频理解大模型赛道的领先地位。

DeepSeek v3.2有一个新改动,在论文里完全没提,只在官方公告中出现一次,却引起墙裂关注。开源TileLang版本算子,其受关注程度甚至超过新稀疏注意力机制DSA,从画线转发的数量就可以看出来。

原文作者:David Adam 本篇《自然》长文共3702字,干货满满,预计阅读时间12分钟,时间不够建议可以先“浮窗”或者收藏哦。 研究表明,电子伙伴类应用有利有弊——但科学家们担心长期依赖性。 绘

今天凌晨,Claude Sonnet 4.5发布了!新模型在编码、计算机使用、推理、长任务能力、安全对齐上的水平全面拔高,成为新一代编程模型王者。新一轮围绕编程展开的百模大战即将展开,而Claude Sonnet 4.5即将成为大家争相对标的新对象

据“互联网八卦小喇叭”等媒体爆料,全球顶尖AI科学家、IEEE Fellow许主洪(Steven Hoi)已加盟阿里通义,转向通义大模型的相关研发工作。许主洪拥有超20年AI产业和学术经验,是新加坡管理大学终身教授、曾任新加坡南洋理工大学终身副教授,在AI领域发表了300多篇顶级学术论文,
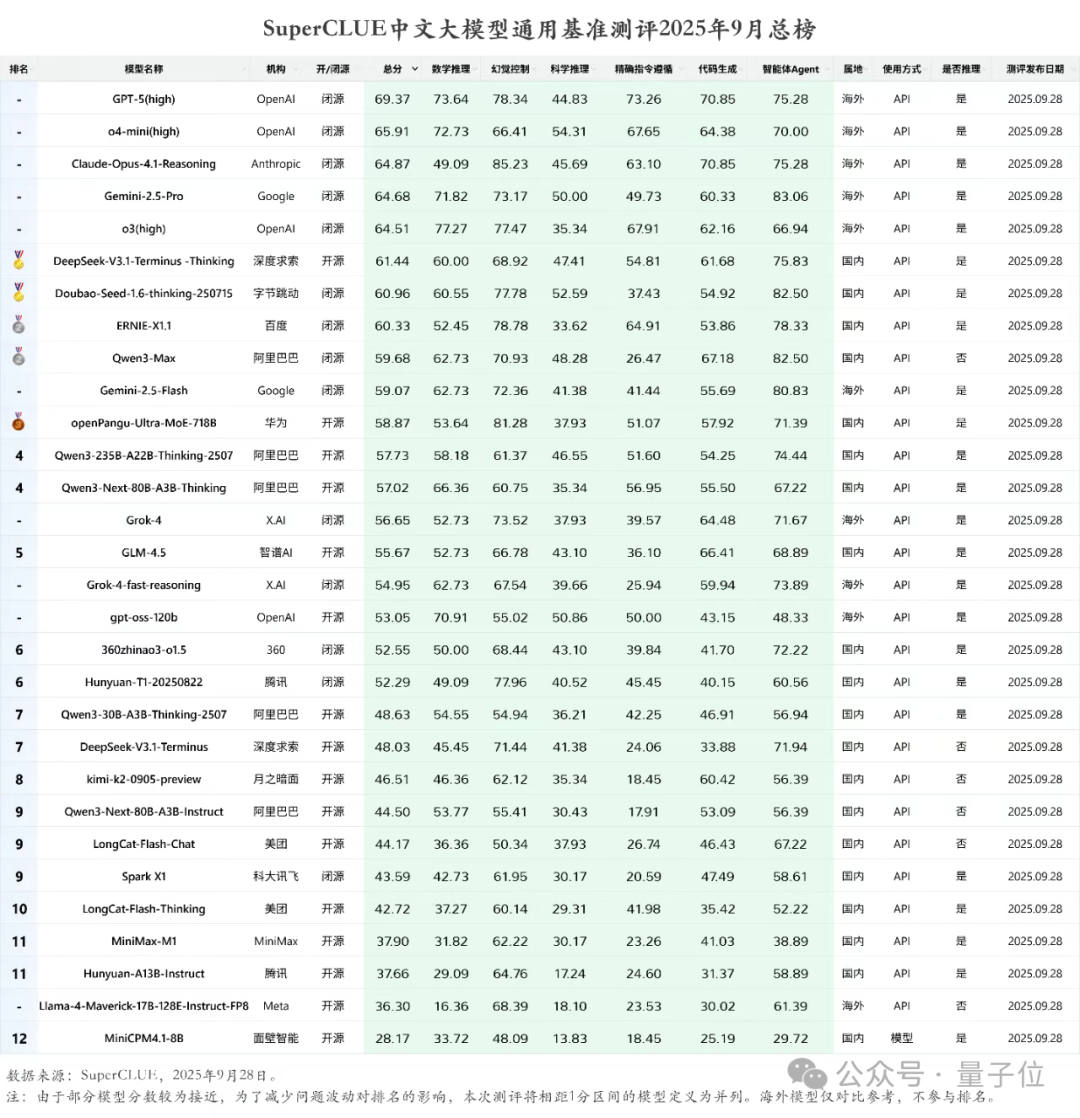
就在最新一期的SuperCLUE中文大模型通用基准测评中,各个AI大模型玩家的成绩新鲜出炉。DeepSeek-V3.1-Terminus-Thinking openPangu-Ultra-MoE-718B Qwen3-235B-A22B-Thinking-2507

DeepMind公开了有关Veo 3视频模型最新论文!论文提出了「帧链」(Chain-of-Frames,CoF),认为视频模型也可能像通用大模型一样具备推理能力。零样本能力的涌现,表明视频模型的「GPT-3时刻」来了。
刚发V3.1“最终版”,DeepSeek最新模型又来了!DeepSeek-V3.2-Exp刚刚官宣上线,不仅引入了新的注意力机制——DeepSeek Sparse Attention。还开源了更高效的TileLang版本GPU算子!