
仅4B大小可端侧部署!卡帕西预言的「认知模型」被国产做出来了
仅4B大小可端侧部署!卡帕西预言的「认知模型」被国产做出来了好家伙,卡帕西又说对了!
来自主题: AI资讯
8704 点击 2026-06-09 14:56
 搜索
搜索
好家伙,卡帕西又说对了!

大模型还在混战,AI及智能硬件市场先跑出了三个“爆款”:AI眼镜、AI录音笔、3D打印机。
当前,Coding Agents 在软件工程领域一路高歌猛进,科学家们看到此场景,也不禁寄予厚望:AI 智能体何时能以同样的速度,帮人类攻克药物设计、病毒监控与生物学建模的重重难关?

Anthropic自家工程师早已基本不写代码了,却280美元一个任务,花钱请约1000名外部工程师,手把手教Claude Code写出好代码。喂养前沿模型的,终究还是人。

Meta 发布了一项令人震撼的研究工作 VLM³,首次揭示了三维视觉学习的 Bitter Lesson:标准的视觉语言模型 + scale 数据就是最简单有效的范式,针对特定任务的架构、损失函数以及数据增强的设计,甚至是 regression 的 formulation,均不是三维视觉学习的必要条件。

阿里巴巴今天宣布了围绕AI业务的一次重要组织升级调整: 宣布合并通义大模型事业部和未来生活实验室,成立Token Foundry事业部,由集团CEO吴泳铭直接负责。周靖人将担任阿里巴巴首席科学家,牵头成立阿里巴巴AI未来研究院,专注前沿AI科技的探索与突破。郑波带领Happy Horse、Happy Oyster等加入Token Foundry事业部。
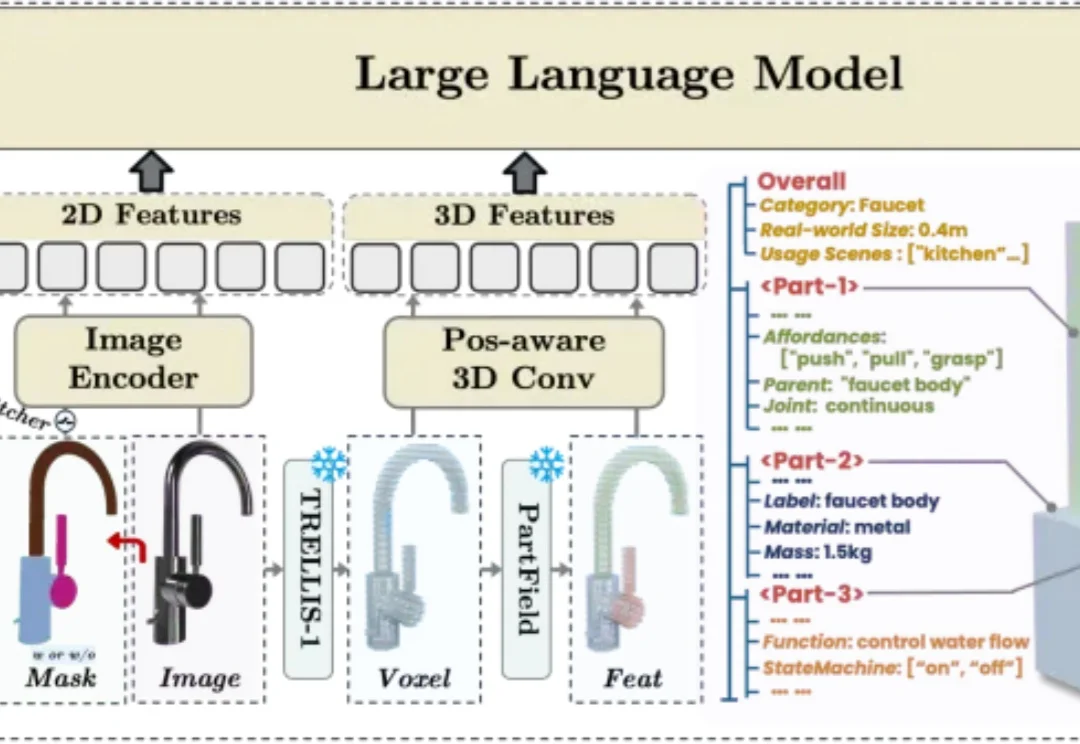
在交互式虚拟世界和具身智能快速发展的今天,高质量 3D 资产已经不再只是 “看起来像” 就足够。一个柜门不仅要有柜门的外观,还需要知道绕哪条轴旋转;一个按钮不仅要有按钮的形状,还需要具备 “按下 / 弹起” 的状态;一个抽屉不仅要有完整几何,还需要拥有滑动方向、运动范围、材质和质量等物理属性。该研究已被 ICML 2026 接收。
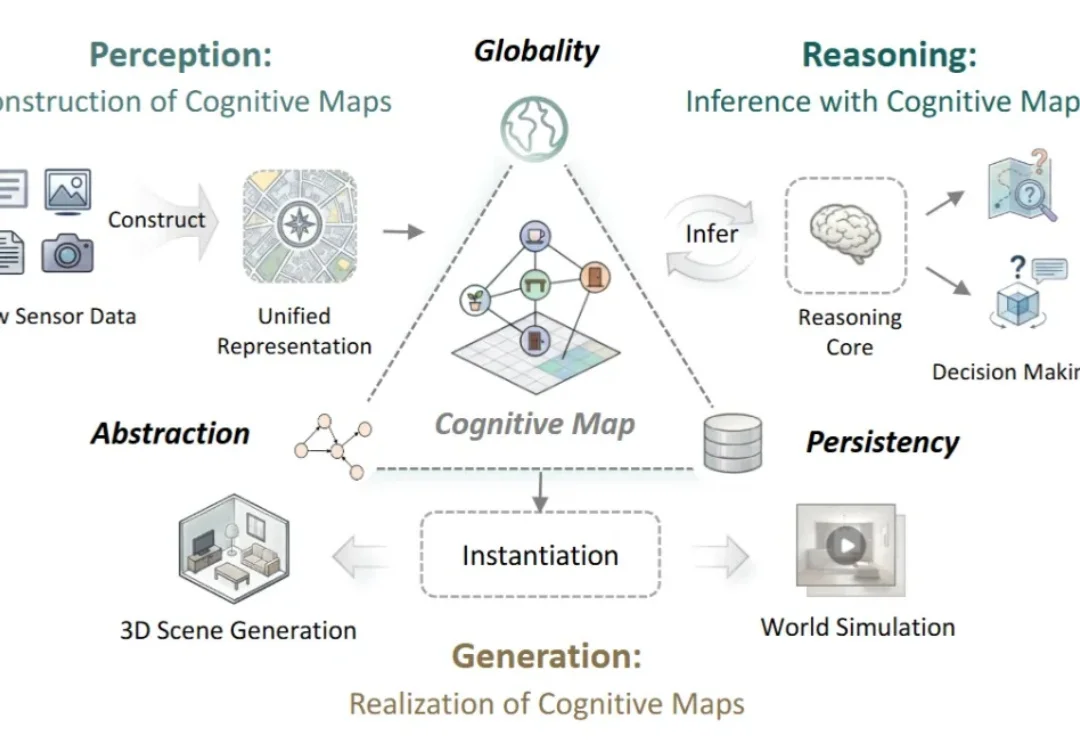
AI 已经能看懂图像、生成场景,甚至在虚拟环境中规划行动。

近年来,文生图模型的能力快速提升。从 Stable Diffusion 到 FLUX、Qwen-Image,扩散模型已经能够生成高质量图像,也能处理越来越复杂的文本提示。
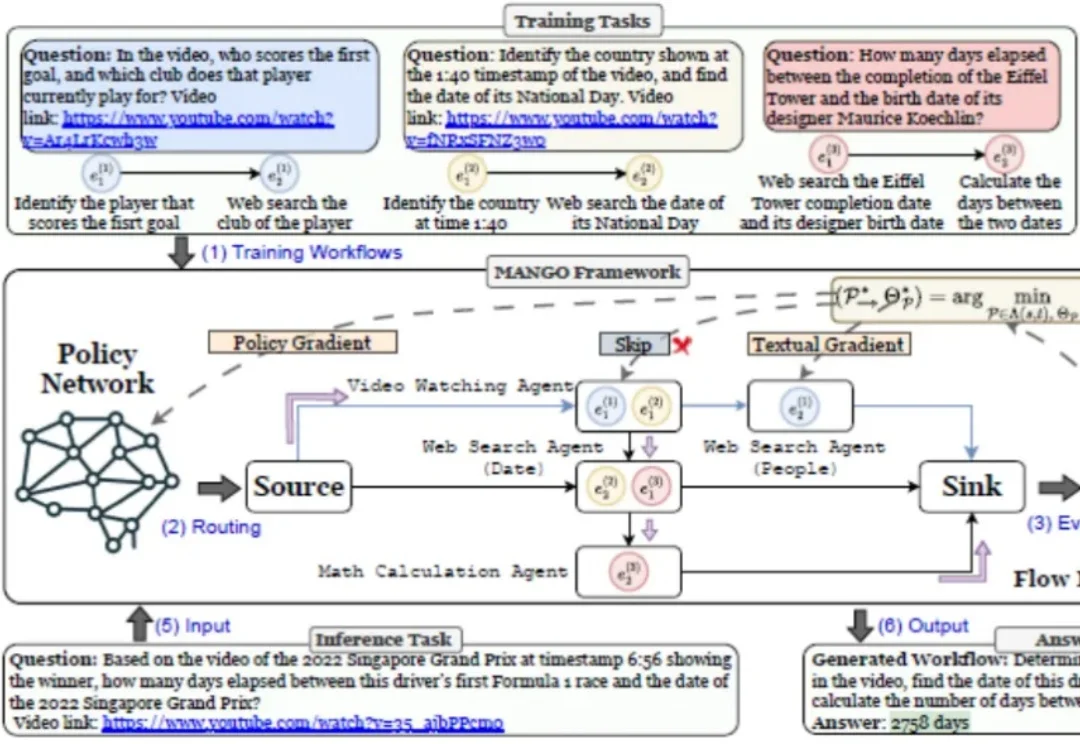
多智能体协作对于解决复杂问题虽然具有巨大优势,但是其架构本质上易出现错误传播,因为由不正确的工作流生成或单智能体幻觉输出引起的错误会沿着协作链蔓延,影响最终结果。