
斥资500元/上亿Token,深度横评4个顶尖模型的真实排名~
斥资500元/上亿Token,深度横评4个顶尖模型的真实排名~大家好,我是袋鼠帝。 6月,感觉又是模型爆发的月份。
来自主题: AI资讯
6116 点击 2026-06-17 14:27
 搜索
搜索
大家好,我是袋鼠帝。 6月,感觉又是模型爆发的月份。
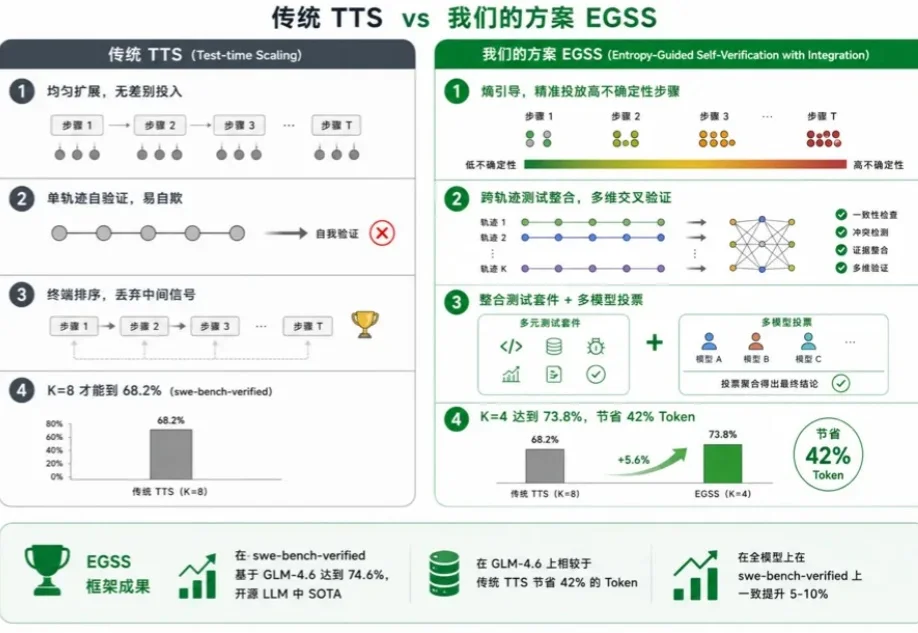
更聪明的计算远比更多的计算更有效。
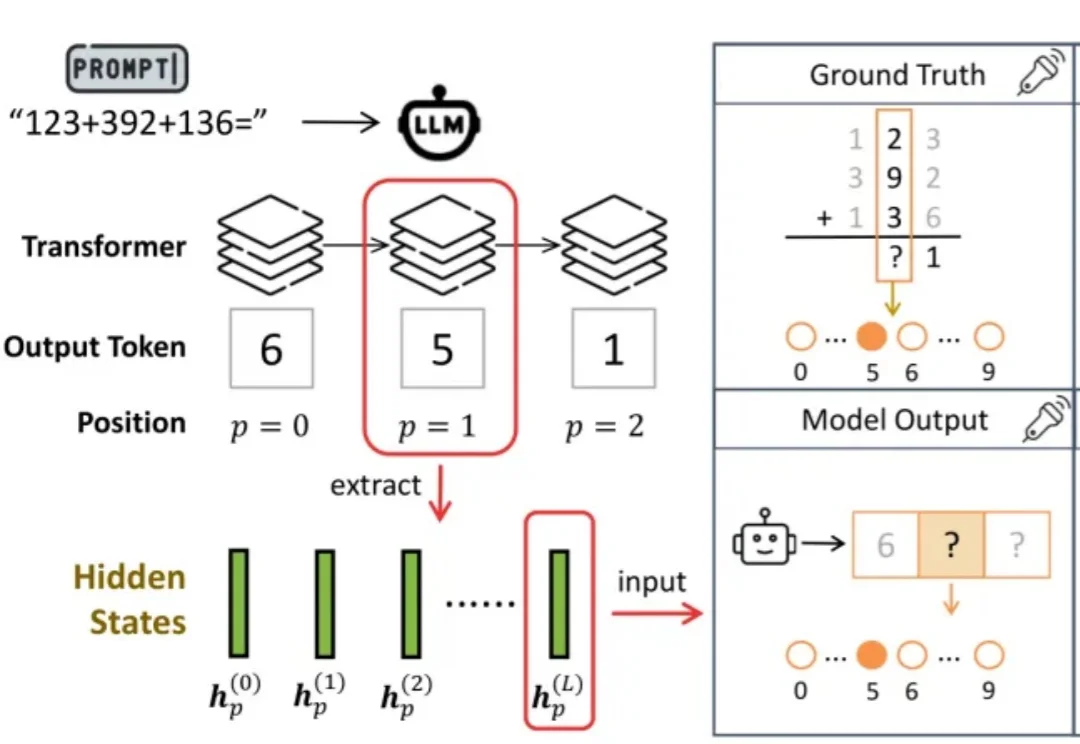
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。
昨晚,小米正式上线了Xiaomi MiMo Claw,一款云端Claw类产品,搭载与OpenClaw框架深度适配的MiMo-V2.5-Pro旗舰模型,同时联动了金山办公生态,实现一站式办公,现在可以在MiMo Studio上进行体验。

刚刚被 SpaceX 宣布以 600 亿美元收购的 Cursor,发布大模型了。本周二,Cursor 宣布了一个新的 1.5 万亿 + 参数模型,该模型在超过 10 万块 GPU 上进行了预训练。消息是在旧金山举行的 Cursor Compile 上宣布的,这是 Cursor 举办的首届旗舰大会。

逆矩阵计划于 2026 年底发布旗舰模型。

大模型再强,也读不懂你公司那一柜子的合同、发票和扫描件。在"纸张世界"和"LLM世界"之间,缺一座桥——而百度开源的 PaddleOCR,可能就是当下最稳的那座。
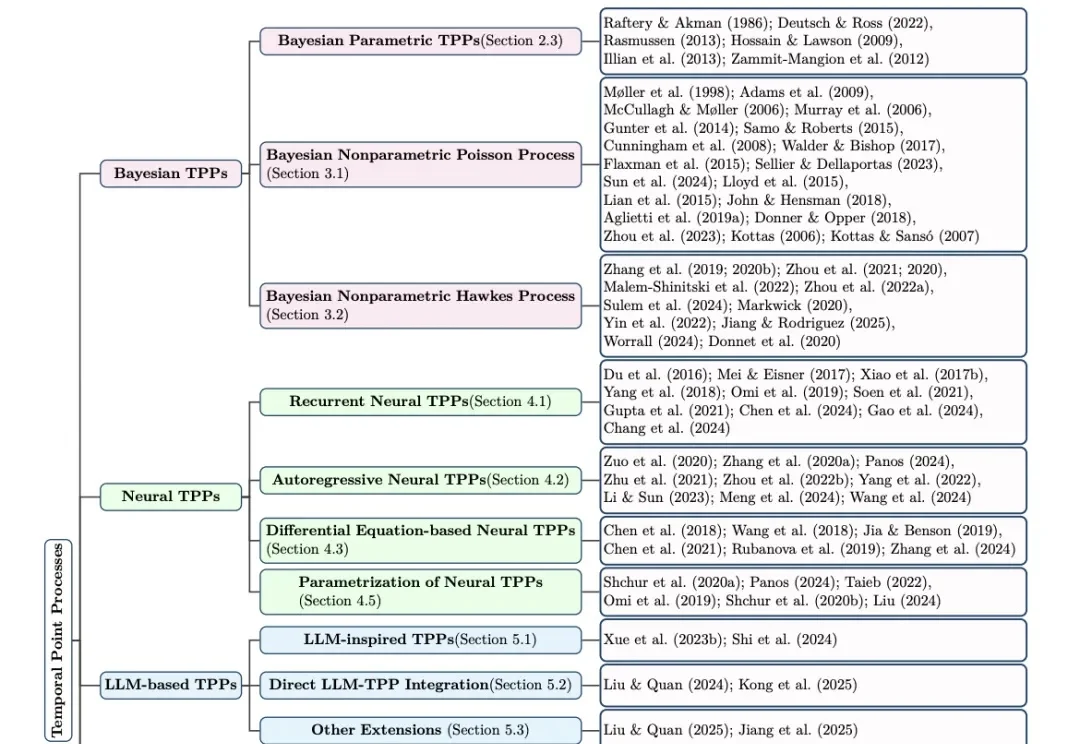
机器学习已经习惯了处理序列:一句话中的词、视频中的帧、推荐系统中的点击、金融市场中的订单。但在很多真实场景里,数据并不是按固定步长排好队出现的。