你的自拍和聊天记录,正被硅谷大厂砸数十亿美元疯抢!
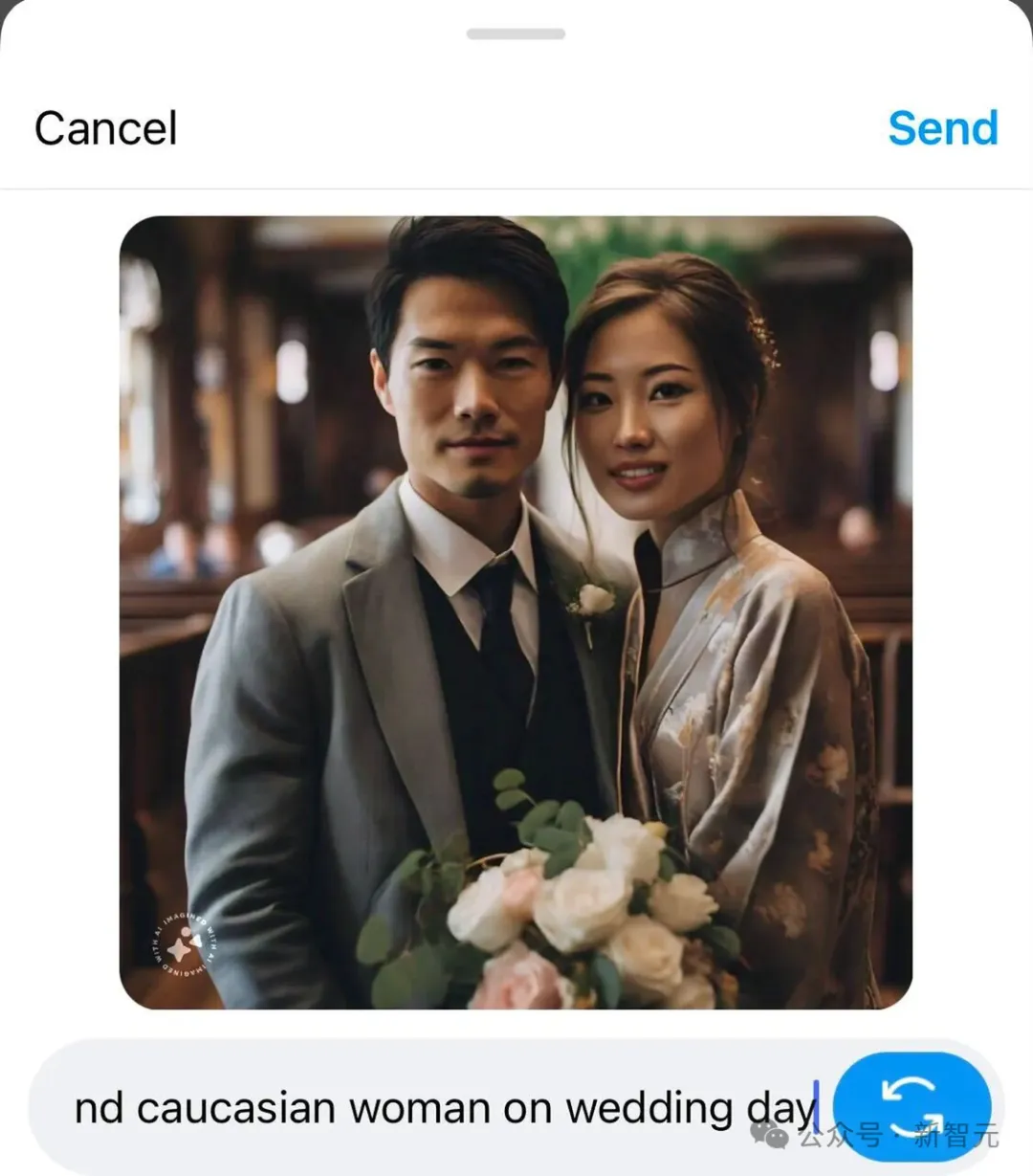
你的自拍和聊天记录,正被硅谷大厂砸数十亿美元疯抢!2026年的数据荒越来越近,硅谷大厂们已经为AI训练数据抢疯了!它们纷纷豪掷十数亿美元,希望把犄角旮旯里的照片、视频、聊天记录都给挖出来。不过,如果有一天AI忽然吐出了我们的自拍照或者隐私聊天,该怎么办?
来自主题: AI技术研报
8134 点击 2024-04-07 17:48
 搜索
搜索
2026年的数据荒越来越近,硅谷大厂们已经为AI训练数据抢疯了!它们纷纷豪掷十数亿美元,希望把犄角旮旯里的照片、视频、聊天记录都给挖出来。不过,如果有一天AI忽然吐出了我们的自拍照或者隐私聊天,该怎么办?

联邦学习使多个参与方可以在数据隐私得到保护的情况下训练机器学习模型。但是由于服务器无法监控参与者在本地进行的训练过程,参与者可以篡改本地训练模型,从而对联邦学习的全局模型构成安全序隐患,如后门攻击。

模仿人类阅读过程,先分段摘要再回忆,谷歌新框架ReadAgent在三个长文档阅读理解数据集上取得了更强的性能,有效上下文提升了3-20倍。

FoundationPose模型使用RGBD图像对新颖物体进行姿态估计和跟踪,支持基于模型和无模型设置,在多个公共数据集上大幅优于针对每个任务专门化的现有方法.

在探索人工智能边界时,我们时常惊叹于人类孩童的学习能力 —— 可以轻易地将他人的动作映射到自己的视角,进而模仿并创新。当我们追求更高阶的人工智能的时候,无非是希望赋予机器这种与生俱来的天赋。

3月29日,以“数据驱动,智绘未来”为主题的2024北京AI原生产业创新大会暨北京数据基础制度先行区成果发布会举办。会上,北京国际大数据交易所(以下简称“北数所”)牵头正式发布首批100个人工智能大模型高质量训练数据集,经联盟牵头推荐,中关村数字媒体产业联盟成员单位新华网、山东工艺美术学院、中国搜索、中文在线、北京服装学院、硅星人等院校、企业的高质量数据集入选。

如果让你在互联网上给大模型选一本中文教材,你会去哪里取材?是知乎,是豆瓣,还是微博?一个研究团队为了构建高质量的中文指令微调数据集,对这些社交媒体进行了测试,想找到训练大模型最好的中文预料,结果答案保证让你大跌眼镜——
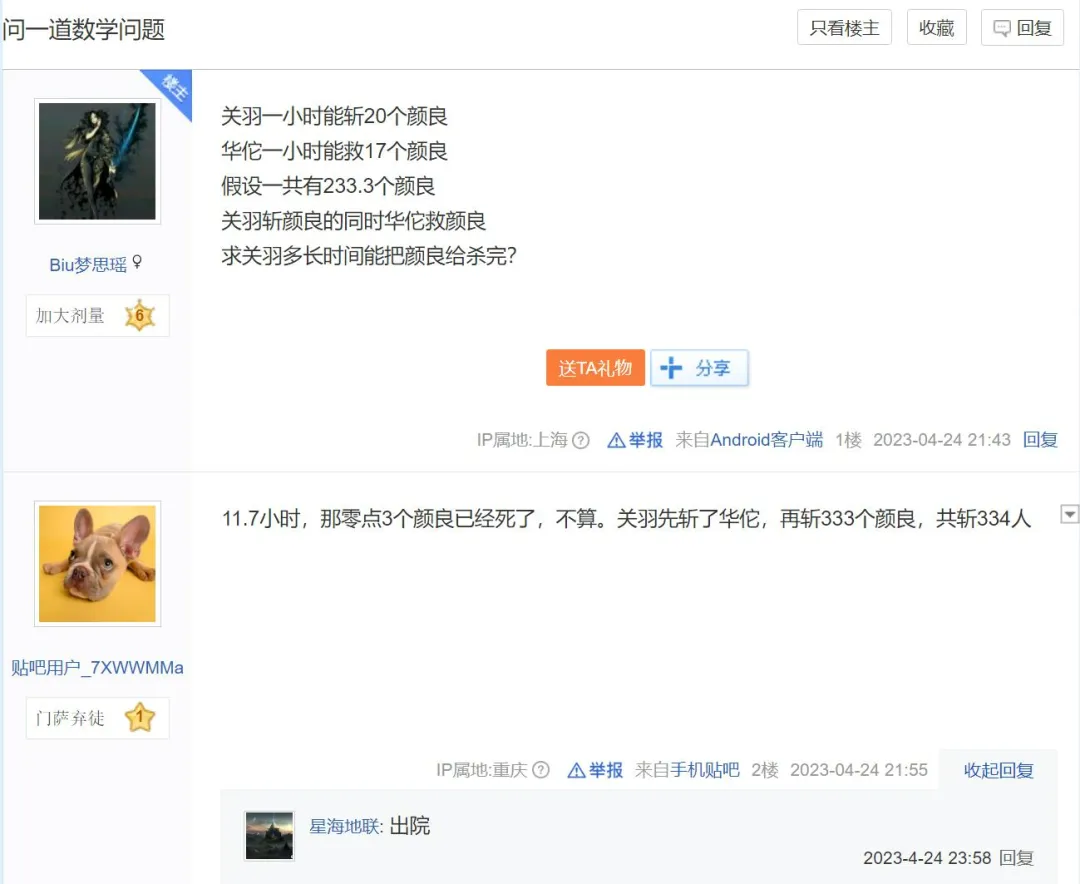
「被门夹过的核桃,还能补脑吗?」
离大谱了,弱智吧登上正经AI论文,还成了最好的中文训练数据??
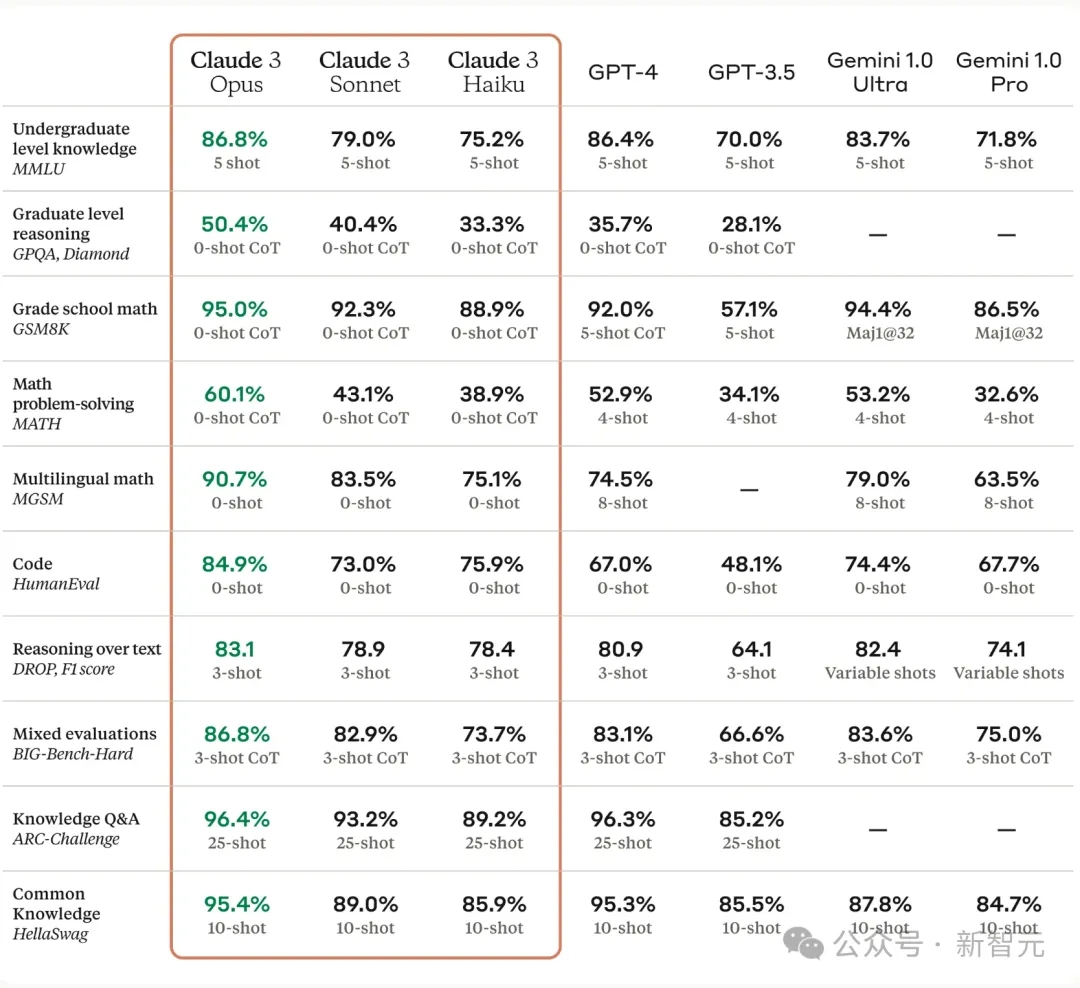
Claude 3不但数据集跑分领先,用户体验上也将成为最强大的LLM,GPT-5在哪里?