
填补空白!首个提升大模型工作流编排能力的大规模数据集开源
填补空白!首个提升大模型工作流编排能力的大规模数据集开源Manus 爆火出圈,引发 Agent 热潮!从自行理解任务、拆解步骤到选择工具并执行,这需要 Agent 具备强大的复杂工作流编排和任务处理能力,而工作流也是智能体的核心技术之一。
来自主题: AI技术研报
10819 点击 2025-03-12 14:18
 搜索
搜索
Manus 爆火出圈,引发 Agent 热潮!从自行理解任务、拆解步骤到选择工具并执行,这需要 Agent 具备强大的复杂工作流编排和任务处理能力,而工作流也是智能体的核心技术之一。

谷歌发布了1000亿文本-图像对数据集,是此前类似数据集的10倍,创下新纪录!基于新数据集,发现预训练Scaling Law,虽然对模型性能提升不明显,但对于小语种等其他指标提升明显。让ViT大佬翟晓华直呼新发现让人兴奋!

北京大学、上海人工智能实验室、南洋理工大学联合推出 DiffSensei,首个结合多模态大语言模型(MLLM)与扩散模型的定制化漫画生成框架。该框架通过创新的掩码交叉注意力机制与文本兼容的角色适配器,实现了对多角色外观、表情、动作的精确控制
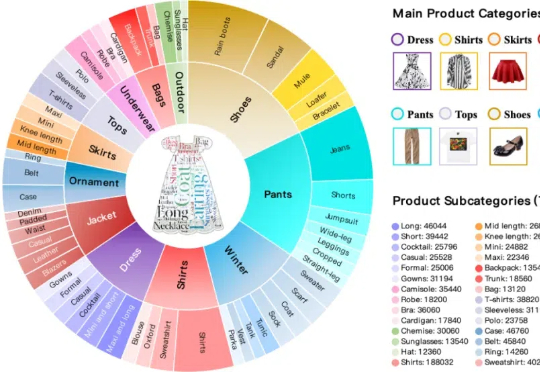
本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。

基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。
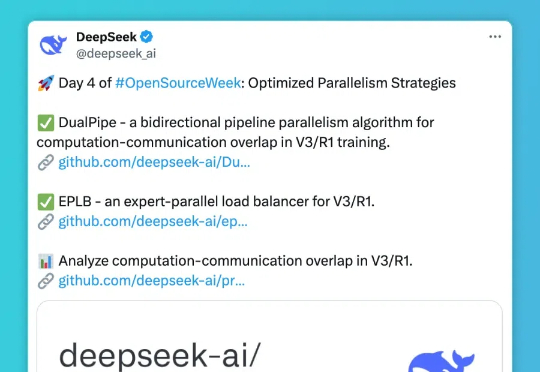
第四天,DeepSee发布包括三个主要项目: DualPipe- 一种用于 V3/R1 训练的双向流水线并行算法,实现计算和通信完全重叠; EPLB(Expert Parallelism Load Balancer) - 专为 V3/R1 设计的专家并行负载均衡器; Profile-data- 分析 V3/R1 中计算与通信重叠的性能数据集。
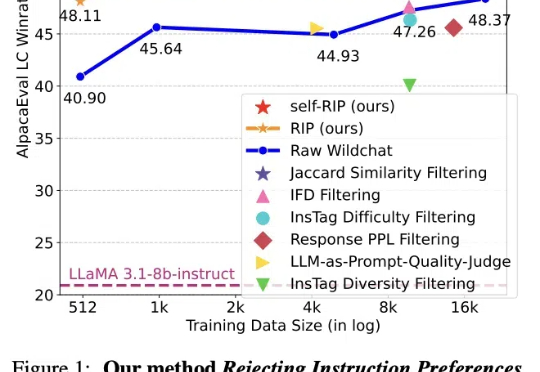
近日,Meta等机构发表的论文介绍了一种通过进化算法构造高质量数据集的方法:拒绝指令偏好(RIP),得到了Yann LeCun的转赞。相比未经过滤的数据,使用RIP构建的数据集让模型在多个基准测试中都实现了显著提升。

在今年1月《Journal of Supercomputing》上开源的「开源类脑芯片」二代(Polaris 23)完整版本源代码,基于RISC-V架构,支持脉冲神经网络(SNN)和反向传播STDP。该芯片通过并行架构显著提升神经元和突触处理能力,带宽和能效大幅提升,MNIST数据集准确率达91%。

AI生成内容已深度渗透至生活的方方面面,从艺术创作到设计领域,再到信息传播与版权保护,其影响力无处不在。

RedStone是一个高效构建大规模指定领域数据的处理管道,通过优化数据处理流程,从Common Crawl中提取了RedStone-Web、RedStone-Code、RedStone-Math和RedStone-QA等数据集,在多项任务中超越了现有开源数据集,显著提升了模型性能。