深度|具身合成数据的路线之争,谁将率先走出困境?
深度|具身合成数据的路线之争,谁将率先走出困境?本文主要描述了具身合成数据两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。参考自动驾驶的成功经验,前者模态转换链路过长导致误差累积,'直接合成3D数据'理论上有信息效率优势,但需要克服“常识欠缺”等挑战。
来自主题: AI技术研报
12040 点击 2025-04-09 10:07
 搜索
搜索
本文主要描述了具身合成数据两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。参考自动驾驶的成功经验,前者模态转换链路过长导致误差累积,'直接合成3D数据'理论上有信息效率优势,但需要克服“常识欠缺”等挑战。

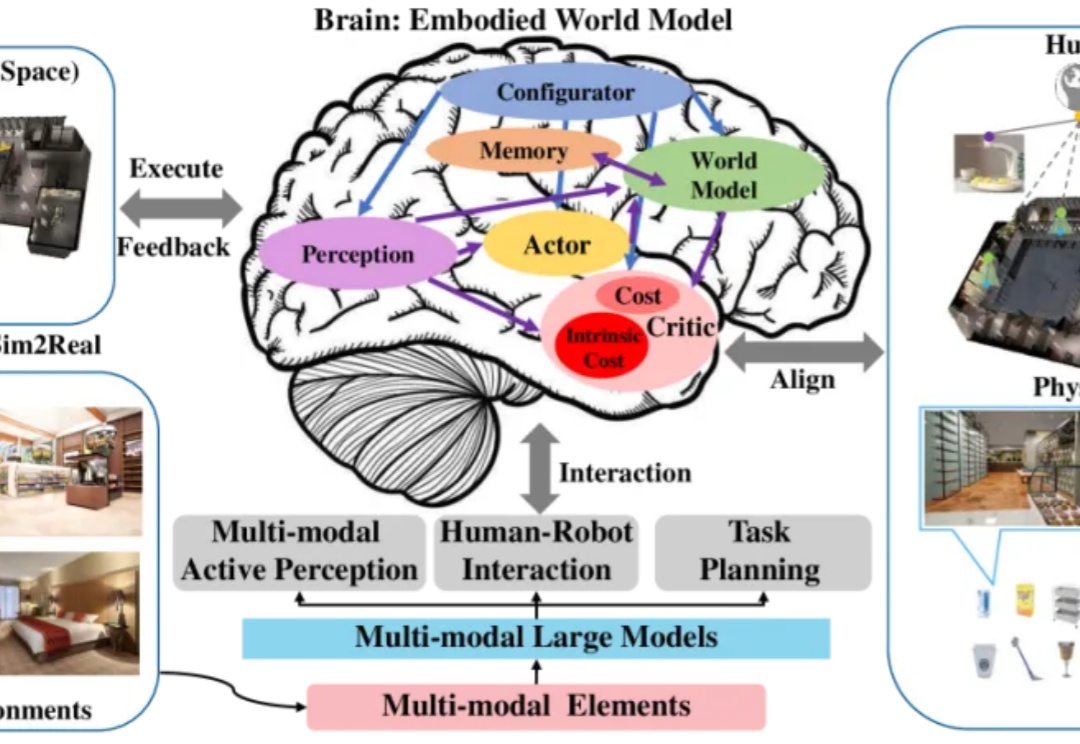
大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。
如何让大模型更懂「人」?

当我们遇到新问题时,往往会通过类比过去的经验来寻找解决方案,大语言模型能否如同人类一样类比?在对大模型的众多批判中,人们常说大模型只是记住了训练数据集中的模式,并没有进行真正的推理。

幻觉(Hallucination),即生成事实错误或不一致的信息,已成为视觉-语言模型 (VLMs)可靠性面临的核心挑战。随着VLMs在自动驾驶、医疗诊断等关键领域的广泛应用,幻觉问题因其潜在的重大后果而备受关注。

继昨天《RAG太折磨人啦,试下pip install rankify,检索、重排序、RAG三合一,完美》发布之后,有许多朋友向我询问Rankify的具体使用方法和部署细节,尤其是生产环境如何处理自定义数据集和本地数据集。

作为一家公司,我们专注于三件事:预训练、微调和对齐。我们使用自有数据集进行预训练,这一点非常关键,而很多公司并不具备这样的能力。然后,我们用专家手工整理的数据进行微调。最有趣、最重要的部分在于对齐,这与简单地寻找“当前最优解”是截然不同的。

就在刚刚,OpenAI 宣布在其 API 中推出全新一代音频模型,包括语音转文本和文本转语音功能,让开发者能够轻松构建强大的语音 Agent。据 OpenAI 介绍,新推出的 gpt-4o-transcribe 采用多样化、高质量音频数据集进行了长时间的训练,能更好地捕获语音细微差别,减少误识别,大幅提升转录可靠性。

当我们看到一张猫咪照片时,大脑自然就能识别「这是一只猫」。但对计算机来说,它看到的是一个巨大的数字矩阵 —— 假设是一张 1000×1000 像素的彩色图片,实际上是一个包含 300 万个数字的数据集(1000×1000×3 个颜色通道)。每个数字代表一个像素点的颜色深浅,从 0 到 255。

文本到图像(Text-to-Image, T2I)生成任务近年来取得了飞速进展,其中以扩散模型(如 Stable Diffusion、DiT 等)和自回归(AR)模型为代表的方法取得了显著成果。然而,这些主流的生成模型通常依赖于超大规模的数据集和巨大的参数量,导致计算成本高昂、落地困难,难以高效地应用于实际生产环境。