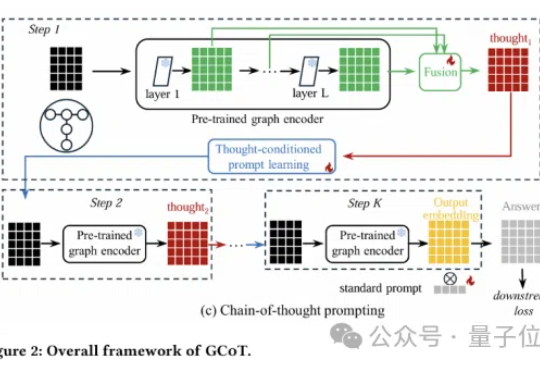
8个数据集全面胜出!思维链推理刷新图学习表现上限
8个数据集全面胜出!思维链推理刷新图学习表现上限图神经网络还能更聪明?思维链提示学习来了!
来自主题: AI技术研报
8131 点击 2025-06-08 15:17
 搜索
搜索
图神经网络还能更聪明?思维链提示学习来了!

AI 搜索引擎初创公司 Perplexity AI 本周四宣布推出 SEC(证券交易)文件访问功能,旨在使复杂的财务数据变得更易于理解,适合从学生到顾问、再到日间交易者等各类投资者。

在多智能体AI系统中,一旦任务失败,开发者常陷入「谁错了、错在哪」的谜团。PSU、杜克大学与谷歌DeepMind等机构首次提出「自动化失败归因」,发布Who&When数据集,探索三种归因方法,揭示该问题的复杂性与挑战性。

如何让CLIP模型更关注细粒度特征学习,避免“近视”?360人工智能研究团队提出了FG-CLIP,可以明显缓解CLIP的“视觉近视”问题。让模型能更关注于正确的细节描述,而不是更全局但是错误的描述。
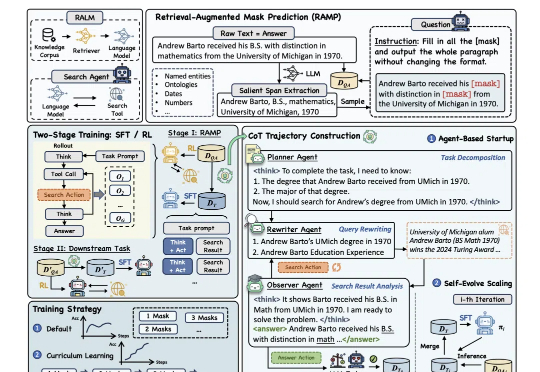
为提升大模型“推理+搜索”能力,阿里通义实验室出手了。
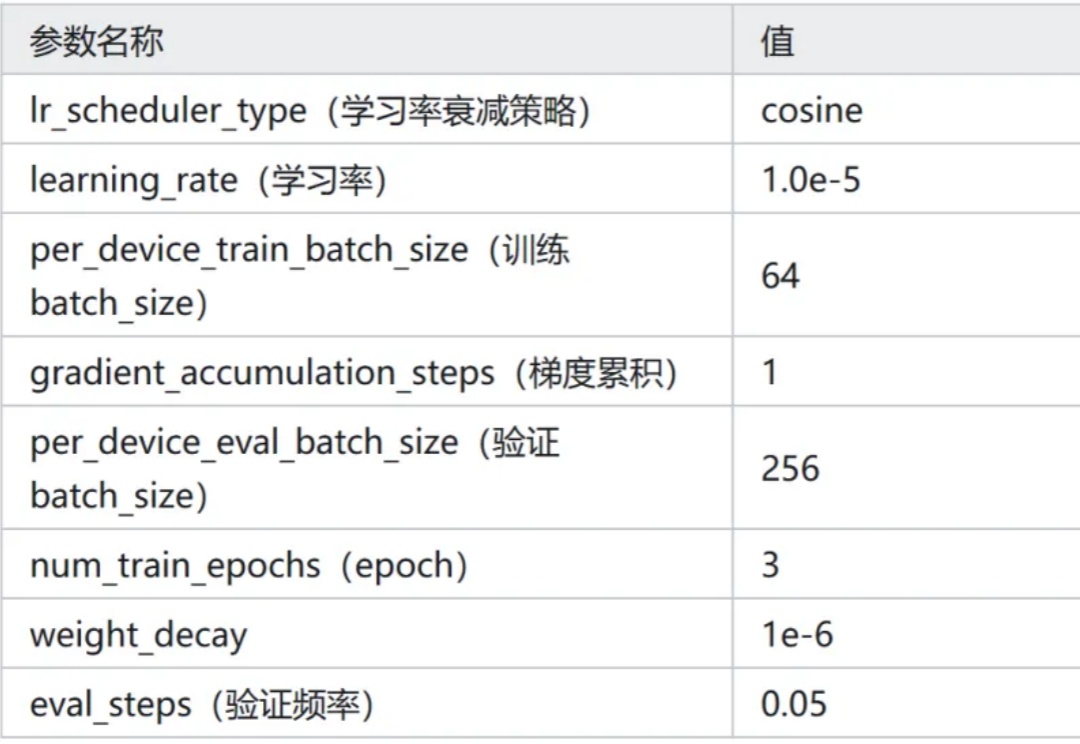
新增 Qwen3-0.6B 在 Ag_news 数据集 Zero-Shot 的效果。新增 Qwen3-0.6B 线性层分类方法的效果。
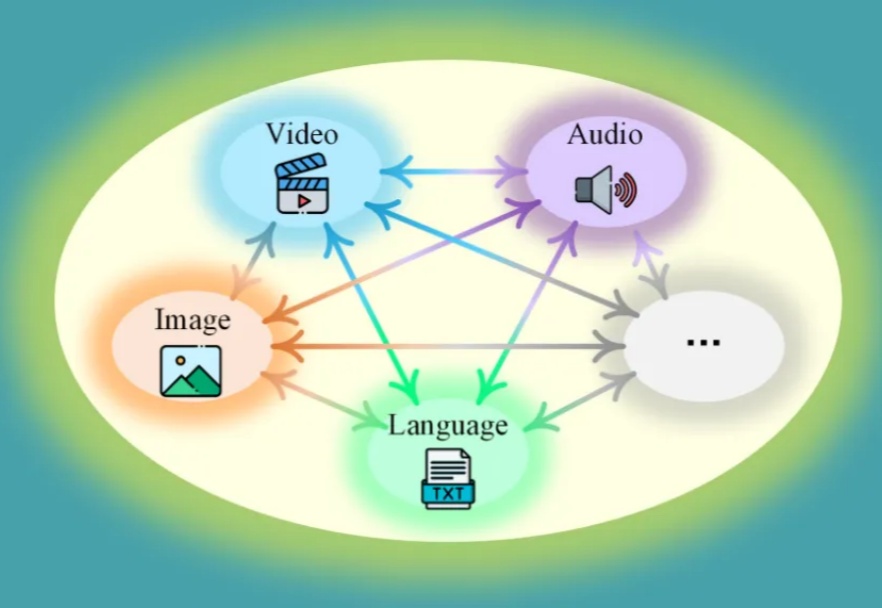
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。

统一图像理解和生成,还实现了新SOTA。

北大和人大团队在通用人形机器人动作生成领域取得重大突破!

在多模态大模型快速发展的当下,如何精准评估其生成内容的质量,正成为多模态大模型与人类偏好对齐的核心挑战。然而,当前主流多模态奖励模型往往只能直接给出评分决策,或仅具备浅层推理能力,缺乏对复杂奖励任务的深入理解与解释能力,在高复杂度场景中常出现 “失真失准”。