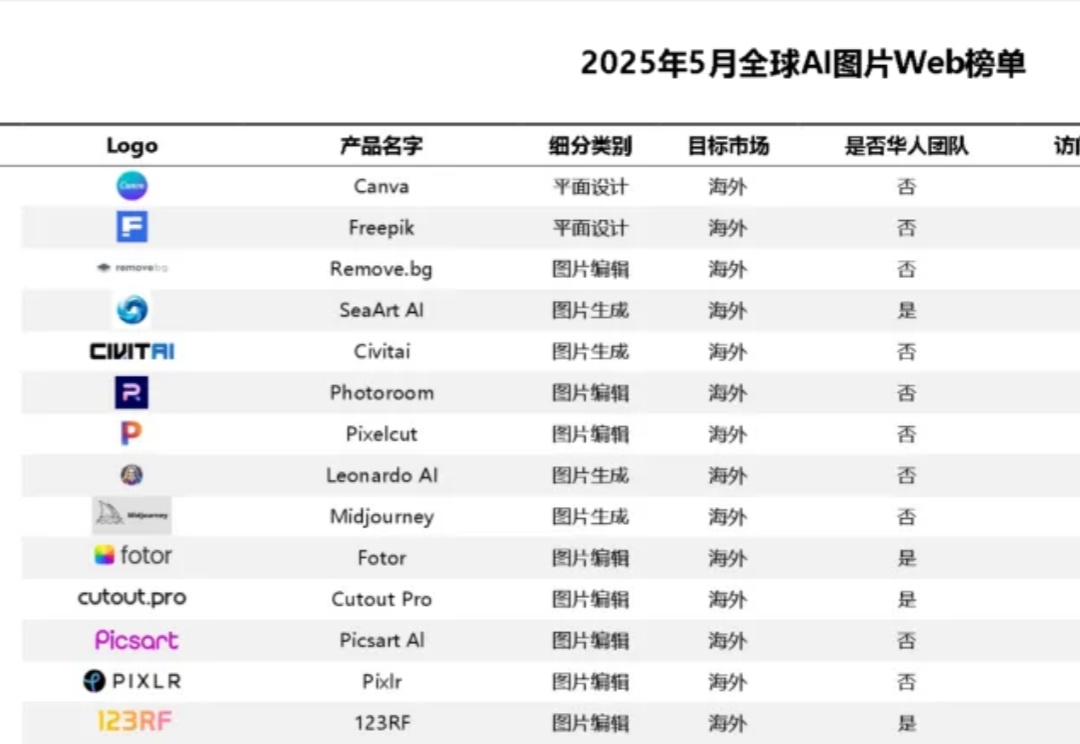
专注的魅力,垂类产品再创新高 | AI图片全球化洞察第11期
专注的魅力,垂类产品再创新高 | AI图片全球化洞察第11期AI 商品图,国内厂商很难追赶的一条赛道。
来自主题: AI资讯
8097 点击 2025-07-11 11:24
 搜索
搜索
AI 商品图,国内厂商很难追赶的一条赛道。

在光鲜外表下,OpenAI暗藏着令人震惊的黑暗一面!华人女记者郝珂灵深挖了奥特曼背后的秘密。

最终体验 = 模型 + context (包括提示词、文件、代码库、业务数据,MCP服务等等一切喂给模型的东西),正好Andrej karpathy前几天天也整了个新提法叫Context engineering,这里可以碰瓷一下Andrej哈哈,这篇文章好几天前我发在小红书了

据媒体报道,OpenAI的浏览器有望在未来数周内上线,集成聊天界面和AI代理功能。若能获得其4亿每周活跃ChatGPT用户的拥护,OpenAI或将对谷歌广告生态、Web数据流和搜索流量产生实质冲击。谷歌Chrome长期作为Alphabet广告业务的支柱,为广告精准投放和流量导向自有搜索引擎提供基础数据。
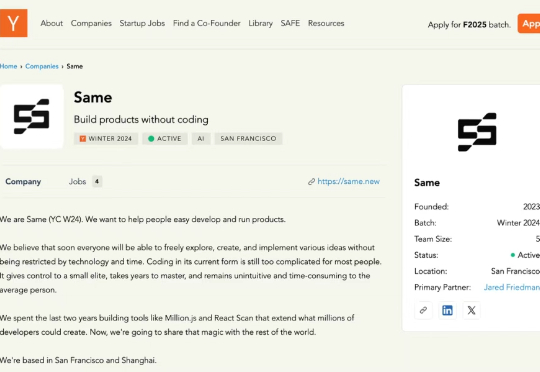
说实话,看到这个项目估值接近 1 亿美金的时候,我有点震惊。这是最近海内外都很火的一款 AI 工具,Same.new。上线 8 周,就吸引了 35 万用户,年化收入做到 200 万美元。创始团队和 Same.new 的产品数据一样叛逆,3 个辍学的大学生,平均年龄 21。

自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。

AI辅助的中国论文工厂正利用美国NHANES公共数据库大规模生产垃圾论文。这些论文研究单一变量与疾病关联,高度重复且方法雷同,数据疑被操纵,结果常假阳性。
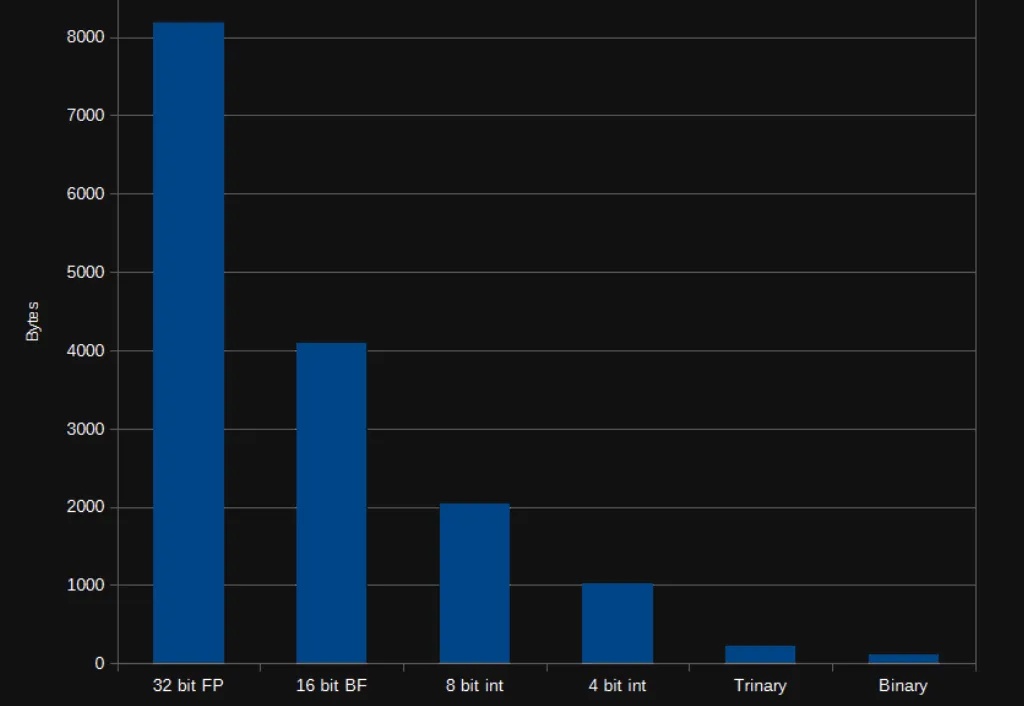
在 AI 领域,我们对模型的期待总是既要、又要、还要:模型要强,速度要快,成本还要低。但实际应用时,高质量的向量表征往往意味着庞大的数据体积,既拖慢检索速度,也推高存储和内存消耗。

总部位于洛杉矶的人工智能视频生成初创公司Moonvalley 团队认为,仅靠文本提示无法完成电影制作。
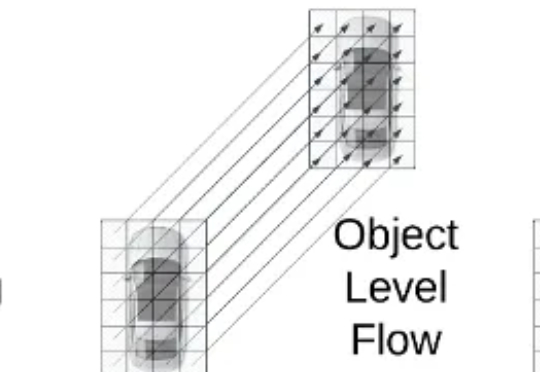
来自加州大学河滨分校(UC Riverside)、密歇根大学(University of Michigan)、威斯康星大学麦迪逊分校(University of Wisconsin–Madison)、德州农工大学(Texas A&M University)的团队在 ICCV 2025 发表首个面向自动驾驶语义占用栅格构造或预测任务的统一基准框架 UniOcc。