
狂奔一年,AI玩具们找到了自己的路
狂奔一年,AI玩具们找到了自己的路无论是技术路线、商业模式还是用户人群,AI玩具行业都存在显著非共识,给到了不同公司更广阔的创新空间。 一年前,AI玩具还被怀疑是概念炒作,需要量产数据去证明这个需求真实存在。经过一年发展,这个市场快速膨胀变大,出现了更多样的产品路径、更大额度的融资和更多愿意为之买单的消费者。
来自主题: AI资讯
9031 点击 2025-08-28 12:33
 搜索
搜索
无论是技术路线、商业模式还是用户人群,AI玩具行业都存在显著非共识,给到了不同公司更广阔的创新空间。 一年前,AI玩具还被怀疑是概念炒作,需要量产数据去证明这个需求真实存在。经过一年发展,这个市场快速膨胀变大,出现了更多样的产品路径、更大额度的融资和更多愿意为之买单的消费者。
近期,多模态大模型在图像问答与视觉理解等任务中进展迅速。随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。
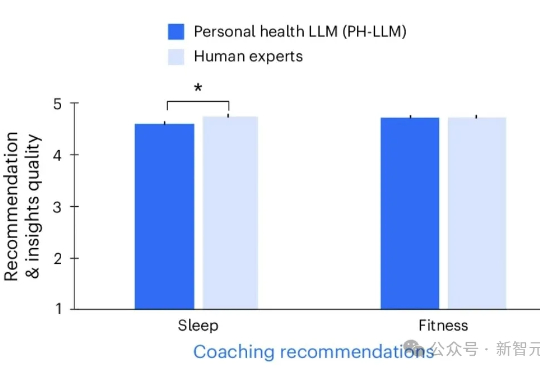
谷歌DeepMind最新Nature王炸,直接把Gemini版大模型PH-LLM调教成了「AI健康私教」,把可穿戴冷冰冰的数据,直接变成睡眠健身建议,结果准确率暴打人类医生。

如果你拥有了庞大的三维空间数据,你会用来做什么? 大模型时代之后,数据成了支撑模型的承重柱。能否获取足够的可用高质量数据,直接决定了某个领域的 AI 的发展上限。

当大多数 AI 教育公司还在为盈利发愁时,成立仅两年的 Praktika,交出的一组运营数据:30人团队支撑起近 2000 万美元年化收入,超500万用户,在2024 年 5 月拿下 Blossom Capital 领投的 3550 万美元 A 轮融资,加上早期种子轮,总融资已达 3800 万美元,这个靠 AI 虚拟外教(Avatar)走红的 App,正在重新定义语言学习的商业模式。
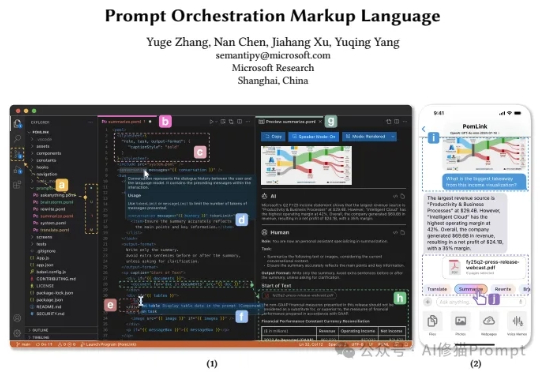
最近来自微软的研究者们带来了一个全新的思路,他们开源发布了POML(Prompt Orchestration Markup Language),它的的解决方案它的核心思想非常直接:为什么我们不能像开发网页一样,用工程化的思维来构建和管理我们的Prompt呢?这个编排语言很类似IBM的PDL

数据显示,70%的雇主更愿意招一位会AI的新人,而不是拥有该岗位10年经验却不会AI的老手。任何毕业生都需要掌握在日常生活中使用AI的能力。现在随着低代码技术的兴起,以及各种让编程变得更简单的工具出现,我们将走到这样一个阶段:每个学生不仅应该学会如何使用AI,还应该学会用AI来创造,比如创造图像、开发应用、编写代码。

A股站上3800点,券商AI投顾收费高,专家提醒勿迷信。 22日,A股全天震荡走高,沪指时隔10年站上3800点。股市行情向好之际,不少投资者将AI视为“投资理财顾问”。不少券商、投顾公司、第三方金融数据软件也纷纷推出了AI投顾、AI选股等功能。
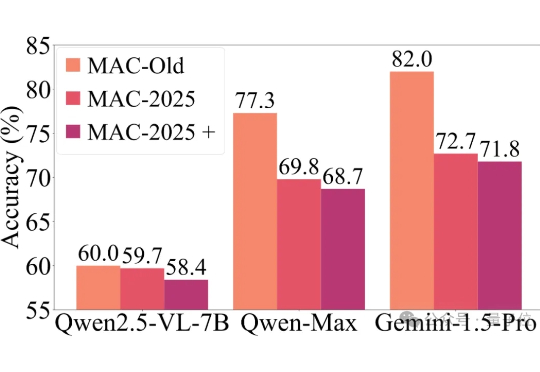
近年来,以GPT-4o、Gemini 2.5 Pro为代表的多模态大模型,在各大基准测试(如MMMU)中捷报频传,纷纷刷榜成功。

Github CEO卸任后未被替代,宣布并入微软Core AI部门,终结其七年独立运营。开发者担忧此举损害开源独立性及免费数据访问,质疑Copilot等AI战略会主导未来。微软此举旨在整合资源强化AI开发工具,但社区文化前景存疑。