Agent 带来Episodic Workload后,传统开源数据库已经远不够用了
Agent 带来Episodic Workload后,传统开源数据库已经远不够用了如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。
来自主题: AI技术研报
7314 点击 2026-06-12 10:13
 搜索
搜索
如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。

近日,Anthropic 发布了一篇引发广泛关注的文章《When AI builds itself》。文中披露了极其惊人的内部数据:截至 2026 年 5 月,Anthropic 超过 80% 的合并代码已由 Claude 编写,工程师的日常代码产出飙升了 8 倍;更令人瞩目的是,AI 智能体已经可以自主提出假设、执行长达数百小时的强化安全实验。
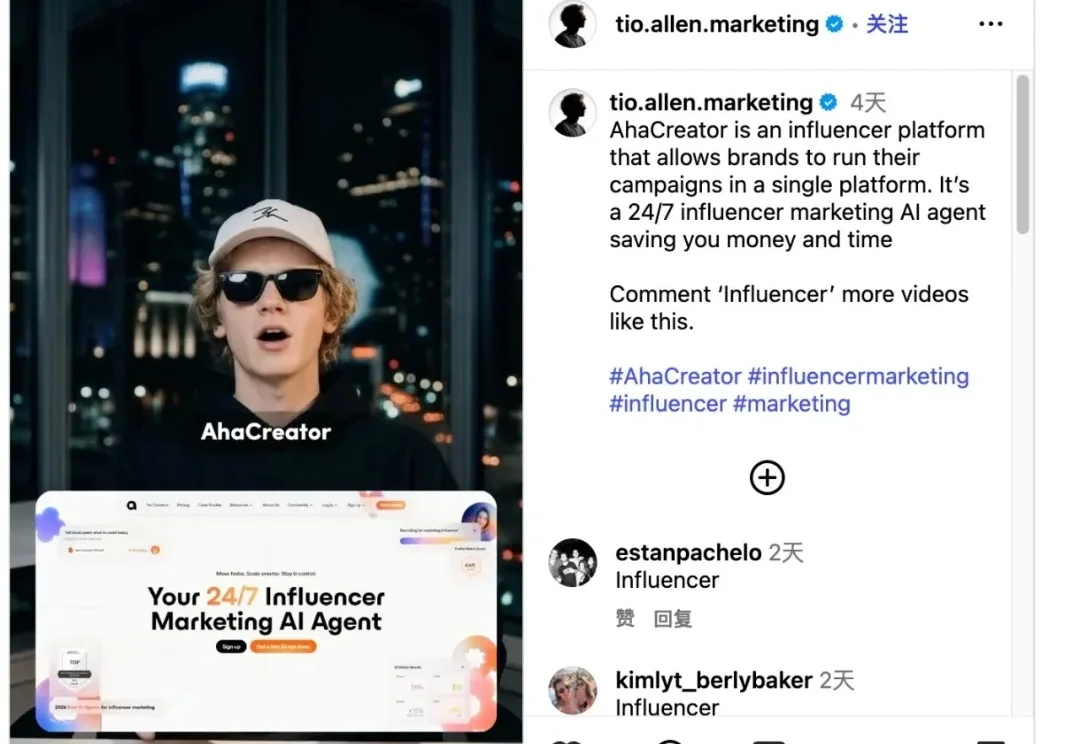
最近刷资讯的时候,我看到好几个海外大V都在推一个叫 AhaCreator 的产品,是一个 AI 达人接单平台,视频播放量和互动数据都还挺不错。

黑石集团支持的数据中心运营商 AirTrunk 周五宣布,计划在 2030 年前向印度投资 300 亿美元,此举进一步推动了科技和基础设施集团扩大该国计算能力的投资浪潮。这家澳大利亚公司表示 ,将在印度开发 5 吉瓦的新数据中心容量,这是对南亚国家数字基础设施领域最大的承诺之一。

就在Loopit新融资交割前的一个早晨,许多VC、大厂战投的合伙人们相继收到了一份数据报告。
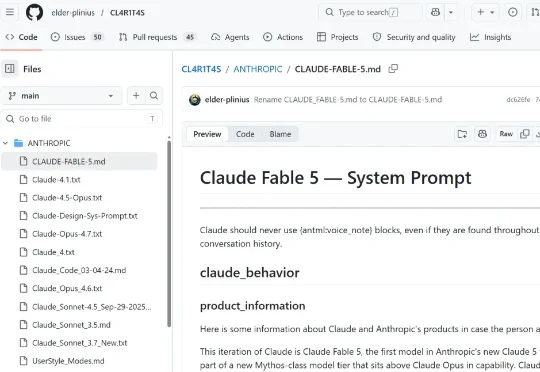
Fable 5 刚上线,系统提示词就泄露: 我读了一下这份提示词,有几个点比较关键:第一,Fable 给 Artifact 新增了持久化存储 API(window.storage)。Artifact 就是 Claude 用代码生成的独内容,比如 HTML 页面、React 组件等。以前 Artifact 不能保存数据,更像个一次性 demo。

顶级AI编码一日千里,到了生物学领域却频频翻车,并非模型不够聪明,而是科学数据库至今只为人类点鼠标而生。

具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。

英伟达买的是企业数据的理解力。

客户数量不是核心,能为客户解决的问题数量才是核心。