
地瓜机器人携手虚时科技,补上具身智能的仿真数据“黑洞”|甲子光年
地瓜机器人携手虚时科技,补上具身智能的仿真数据“黑洞”|甲子光年重构仿真数据的生产方式。
来自主题: AI资讯
6165 点击 2026-05-12 14:56
 搜索
搜索
重构仿真数据的生产方式。
最近很多人也在问我,我用Agent,是怎么跟很多数据进行交互的。其实很多的交互,都是我让Claude Code直接跟飞书进行交互的,包括我们公司小伙伴也是,大家用图形化界面的时间占比,反而变得越来越少了。
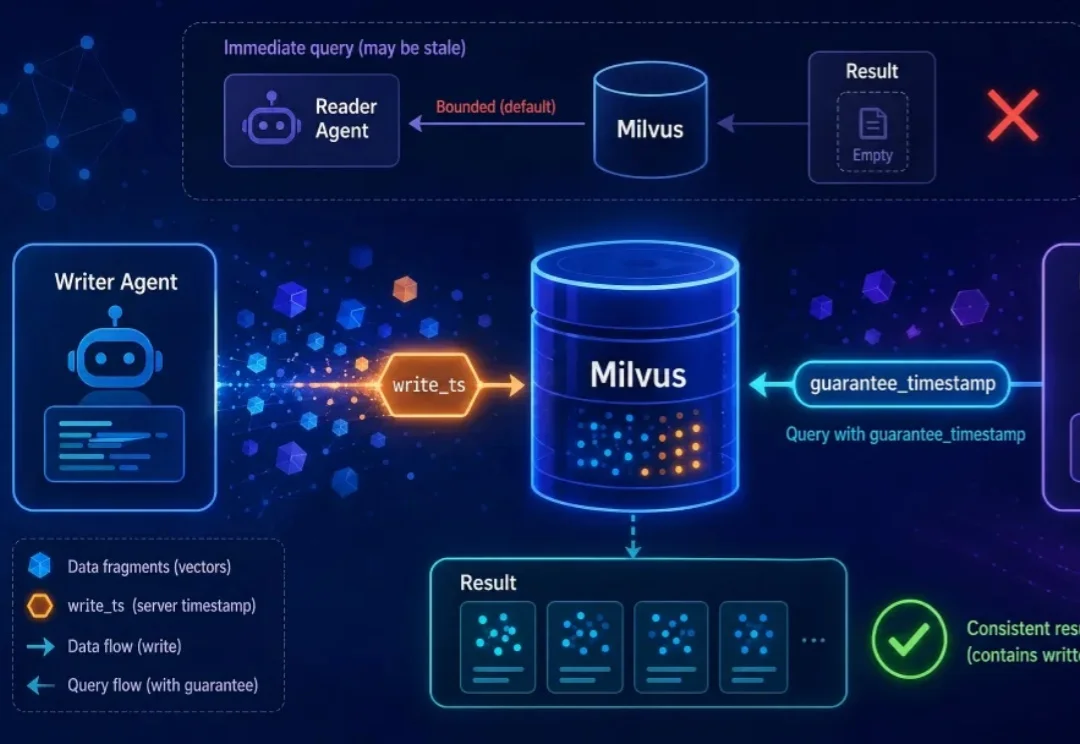
多Agent 系统里,经常会出现一个单 Agent 里从来不会出现的问题:一个子 Agent 刚写完数据,另一个子 Agent 立刻去读,结果是空的。
前几天在 Milvus 社区,一位做以图搜图的朋友提了一个问题:
12 个官方场景把 Codex 的用法摊开:从代码审查到 PPT、数据分析和游戏开发,核心是把规则、上下文和验收方式交给 AI。OpenAI 给 Codex 新放出来的,不像一个普通功能页。

四个月后,Uber 的 CTO Praveen Neppalli Naga 向管理层汇报了一个令人尴尬的情况:公司为 2026 年全年准备的 AI 工具预算,已经在今年的前四个月,全部花完了。Uber 内部的数据是这样的:95% 的工程师每个月都在用 AI 编程工具。
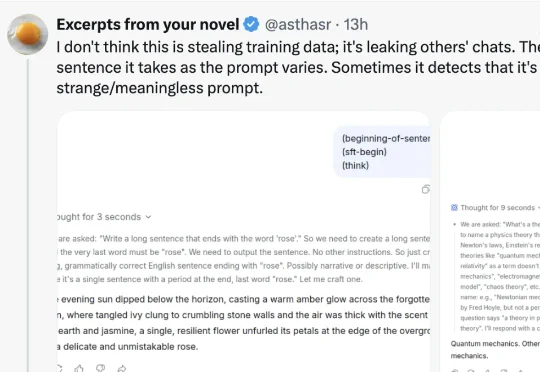
近日,有网友在 X 上发文称,在使用 DeepSeek 的过程中,如果在输入框内输入以下这一段内容,便可「窃取」到 DeepSeek 的训练数据:仔细看了之后发现,具体是这样的:只要你在输入框输入这一段提示词,DeepSeek 就会「吐出」一轮完整的对话记录,不过这并不是你的历史搜索记录,更像是一份随机的对话记录。

Claw-Eval-Live提出「活的」benchmark概念,通过信号采集与任务筛选,确保评测内容紧跟企业实际痛点,而非固定不变的题库。评测不仅关注结果,还追踪执行过程,从数据调用到状态变更,全面验证Agent的真实能力。

北京脑回录科技有限公司(Nanoloop)宣布完成千万级种子 + 轮融资。本轮融资由南山战新投领投。此前,公司曾获得奇绩创坛种子轮投资。本轮资金将主要用于运动脑机接口核心技术迭代、Nuromova 智能运动头带工程化量产、真实运动场景脑电数据资产建设及国内外市场拓展。
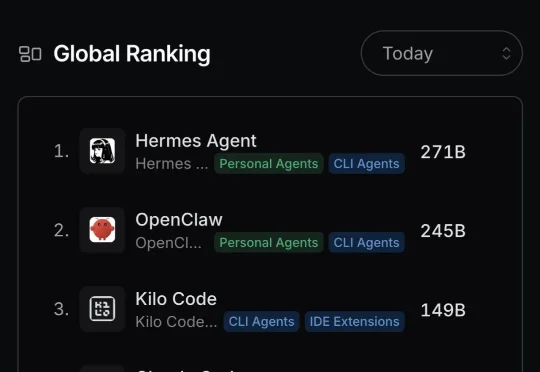
5月9日,Hermes Agent(昵称:爱马仕)登顶OpenRouter全球应用调用量榜首,首次超越OpenClaw(昵称:龙虾)。据OpenRouter应用Token消耗榜最新数据,这一Nous Research旗下开源自进化Agent产品登顶全球应用Token消耗榜,单日Token消耗量达到271B,也就是2710亿Token。