
孟瑜获杰出博士论文奖,中科大获最佳学生论文,KDD 2024全部奖项放出
孟瑜获杰出博士论文奖,中科大获最佳学生论文,KDD 2024全部奖项放出ACM SIGKDD(国际数据挖掘与知识发现大会,KDD) 会议始于 1989 年,是数据挖掘领域历史最悠久、规模最大的国际顶级学术会议,也是首个引入大数据、数据科学、预测分析、众包等概念的会议。
来自主题: AI技术研报
9621 点击 2024-08-28 15:30
 搜索
搜索
ACM SIGKDD(国际数据挖掘与知识发现大会,KDD) 会议始于 1989 年,是数据挖掘领域历史最悠久、规模最大的国际顶级学术会议,也是首个引入大数据、数据科学、预测分析、众包等概念的会议。

8月27日消息,在近日召开的Hot Chips 2024大会上,韩国AI芯片初创公司FuriosaAI 推出了一款面向高性能大型语言模型和多模态模型推理的高能效数据中心AI加速器 RNGD。

本文对AI增强的VR在医疗应用中的技术细节、工作流程和下游应用进行了全面审视,并提出了一个系统性的分类方法,将相关工作分为医学视觉增强、VR医学数据处理和VR辅助干预三个主要类别,为未来跨学科研究提供了基础。

近日,AI顶会KDD 2024在西班牙巴塞罗那正式召开。今年,依旧吸引了数千名世界顶尖学者、企业代表前来,分享在数据科学领域领先成果。而中国队,也交出了亮眼的成绩单。
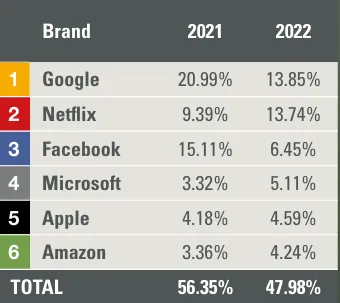
Cisco 曾在 2018 年做过测算,全球已经有超过 75% 的数据是视频内容,互联网视频数据流量超过 50%。

土地和电力资源成为AI行业的“香饽饽”,而工业用地正好能满足AI数据中心建设的部分“刚需”。
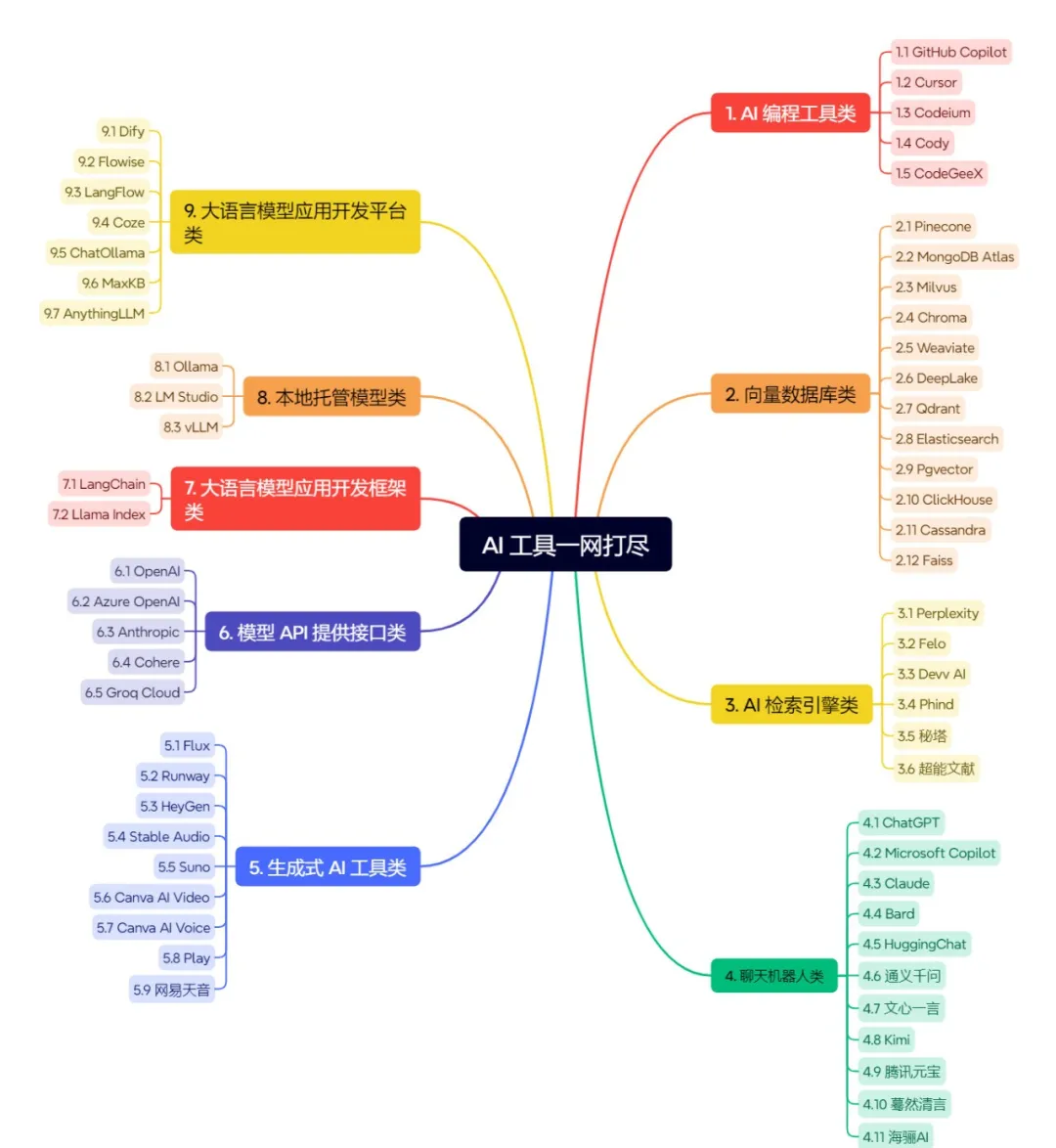
在当今人工智能领域,大语言模型及其相关工具正在迅速发展,涵盖了编程、数据库、检索引擎、聊天机器人、生成式 AI 工具、模型 API、开发框架和平台等各个方面。

随着LLM不断迭代,偏好和评估数据中大量的人工标注逐渐成为模型扩展的显著障碍之一。Meta FAIR的团队最近提出了一种使用迭代式方法「自学成才」的评估模型训练方法,让70B参数的Llama-3-Instruct模型分数超过了Llama 3.1-405B。

本文引入了 Transfusion,这是一种可以在离散和连续数据上训练多模态模型的方法。

在人工智能领域,图像生成技术一直是一个备受关注的话题。近年来,扩散模型(Diffusion Model)在生成逼真且复杂的图像方面取得了令人瞩目的进展。然而,技术的发展也引发了潜在的安全隐患,比如生成有害内容和侵犯数据版权。这不仅可能对用户造成困扰,还可能涉及法律和伦理问题。